Web based School



- 37 — Networking
- Haste Makes Waste, So Plan!
- Down to the Wire
- Types of EtherNets
- What Is a Hub?
- What Is a Repeater?
- What Is a Bridge?
- What Is a Router?
- What Is Switched EtherNet?
- How to Segment and Expand an EtherNet Network
- Configuring TCP/IP
- Assigning Addresses—/etc/hosts
- Naming Networks—/etc/networks
- Choosing the Netmask for a Network—/etc/netmasks
- Mapping Names to Machines—/etc/ethers
- Mapping Names to Interfaces—/etc/hostname.??n
- Starting TCP/IP at Boot Time
- Network Daemons
- The Master Daemon—inetd
- The Remote Procedure Call Master Daemon—rpcbind
- The Service Access Facility Master Daemon—listen
- Other Daemons That Can Be Started at Boot Time
- Daemons Started from inetd
- ftpd
- telnetd
- shell
- login
- exec
- comsat
- talk, ntalk
- uucpd
- tftp
- finger
- systat
- netstat
- time
- daytime
- echo
- discard
- chargen
- RPC Services Started from inetd
- Sharing Files and Directories—NFS
- Backing Up on a Network
- Introduction to NIS
- What Is NIS?
- The NIS Components
- Database Administration Utilities
- NIS Daemons
- Database Distribution Utilities
- Database Lookup Utilities
- DB Files
- What Files Does NIS Control?
- Automounting File Systems
- Analyzing and Troubleshooting Utilities
- Summary
- Internet Protocol (IP) The underlying layer that provides the transfer of information from computer to computer.
- Transmission Control Protocol (TCP) A protocol layer on top of IP that provides reliable connection-oriented communications between two processes. The TCP layer adds flow control, error detection and recovery, and connection services.
- User Datagram Protocol (UDP) A protocol layer on top of IP that provides a low-overhead, unnumbered datagram protocol. It is connectionless and does not provide error checking or flow control.
- Serial Line IP (SLIP) An adaptation of the normal EtherNet-based IP that runs over asynchronous serial lines. It is considered obsolete and has been replaced by PPP.
- Point to Point Protocol (PPP) An adaptation of the normal EtherNet-based IP that runs over asynchronous and synchronous serial lines. It supports dial-up and dedicated circuits and compression to improve bandwidth utilization.
- Internet Control Message Protocol (ICMP) A protocol layer on top of IP that provides control messages to control the IP protocol, such as Host or Network Unreachable, or "reroute this message." The most common use of it is for the ping
packet to see if a computer is alive.
-
TCP/IP Basics
37 — Networking
37 — Networking
By Sydney S. Weinstein
UNIX is a network operating system. It is tightly integrated with the TCP/IP networking protocols. Most of the original work on networking and UNIX was done at the University of California at Berkeley in the late 1970s and early 1980s. Thus, UNIX has a
well-developed and rich set of networking utilities available to both the user and the system administrator.
This chapter explains the basics of networking with TCP/IP and introduces you to how the network is administered. Then it goes into using the network, via the Network File System (NFS) and the Network Information Service (NIS). Because things don't
always go right, the last part of this chapter is on troubleshooting UNIX networks.
TCP/IP Basics
The primary protocol used by UNIX is the Internet Protocol, or IP. Often called TCP/IP, it actually is composed of several parts, including the following:
The basis of communications in IP is the packet. All communications over any medium IP supports are in integral units of packets. Packets are exchanged between nodes. Every node has an address. From the user's point of view, every IP node can
communicate with every other node in the network. However, underneath, the IP software may route the packet via many store and forward hops before the packet gets to the final destination.
Addressing
IP addresses are 32-bit quantities. Every computer has one or more addresses assigned to it. Each network interface (EtherNet adapter, token ring, FDDI, serial line, and so on) has its own 32-bit address. With 32 bits there are 232 addresses available,
or a maximum of 4,294,967,296 network interfaces. However, to make routing (sending the packets for each address to the proper computer, or network node) easier, not all the addresses are used. Instead, the addressing space is broken up to make it easier
to route to networks of different sizes.
In IP each network is given a network number. Each computer on the network is given a node number within that network. Thus the address is split into two parts separated by a dot (network.node). Routing decisions are made on the network part. Reception
decisions within a network are made on the entire address.
For ease of reference, the addresses are not normally written as network.node, but as dotted quads, where each section refers to the value of 8 bits of the 32-bit address, as in this:
192.65.202.1
which is the address of our gateway host at MYXA Corporation.
Class A, B, and C Addresses
Networks come in different sizes. Really big organizations have thousands of locations and thousands of computers. Middle-sized organizations have hundreds of locations and thousands of computers. Small organizations are, well, small. To make it easy to
handle routing decisions, which are made on a network basis and not on the full address, the addressing space is split into several classes.
Class A Addresses
The 32 bits are split into 1 bit of 0, 7 bits of network number, and 24 bits of node number. (See Figure 37.1.) There could have been a maximum of 127 Class A addresses. However, net 0 is reserved, because at one time it was used as a global broadcast,
and net 127 is reserved to mean loop back, or stay within my own computer. This leaves 126 possible Class A addresses. Each Class A address can have 224—or 16,777,214—nodes (the addresses with all 0s and all 1s are reserved to mean
"broadcast to all nodes in this network"). In reality, the organization that uses a Class A address internally splits it up to route to their many internal networks, called subnets, and it really supports many fewer systems. Class A addresses are
very rarely handed out. An example of a Class A address is net 16, Digital Equipment Corporation.
Figure 37.1. A Class A network address layout.
{kind=link}
Class B Addresses
In a Class B address the 32 bits are split into 2 bits of 10, 14 bits of network number, and 16 bits of node number. (See Figure 37.2.) Allowing the address of 128 to equal a Class B broadcast, this leaves 16,383 Class B addresses with up to 65,534
nodes per network. Again, an address that is all 0s or all 1s is a broadcast address. Class B addresses, like Class A addresses, are normally split by their owners into many networks of fewer nodes per network. Even so, Class B addresses are running out
and are hard to obtain. Most major universities have one or more Class B addresses.
Figure 37.2. A Class B network address layout.
{kind=link}
Class C Addresses
In a Class C address the 32 bits are split into 3 bits of 110, 21 bits of network number, and 8 bits of node number. (See Figure 37.3.) This provides 2,097,150 Class C addresses, with up to 254 nodes per network. Again, an address that is all 0s or all
1s is a broadcast address. Class C addresses are often handed out in blocks of 4 or 8 to allow for more than 254 nodes in the same network. MYXA Corporation has several Class C networks and a block of 8 Class C's.
Figure 37.3. A Class C network address layout.
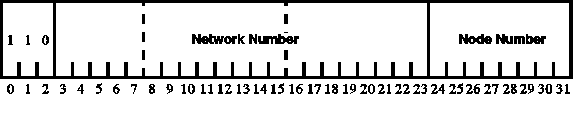{kind=link}
Acquiring a Network Number
Every network, whether connected to the Internet or not, should apply for a network number. If you are connected to the Internet, you will have to do this. Routing is based on the network number, and if you don't want your packets going to some other
network, you have to have a unique network number.
Even if your network is not connected to the Internet, you still should apply for the network number. It's a lot easier to set up your network now, with a unique network number, than to decide later that you want to connect to a public TCP/IP network,
such as the Internet, and have to reassign the network numbers and IP addresses for all your nodes. Besides, the network number is free—all it takes is a small amount of effort to get one. You simply need to fill in a network address request template
and send it in to the Network Information Center, known as NIC. (The CD-ROM for this guide contains a complete copy of the application template in a file called NET-ADDR.TXT.)
Here is how to provide information for the nine items in the application found on the disk:
Item 1
If you are a connected network, you will get your network number from your Internet provider, who will file this form with the NIC on your behalf. Therefore, let the Internet provider answer this question (you can leave it blank).
If you are a nonconnected network, you don't need to answer it, so leave it blank.
Item 2
Who is the person responsible for this network number? This should be your network administrator or some such person. If this person has already filed information with the NIC, he or she will have a NIC handle. If not, don't worry. The first time you
send an application in, the NIC will assign you a net handle.
If you do not have an Internet-reachable electronic mail address, leave the Net Mailbox field blank.
Item 3
This shows how NIC will list this network in its database. Just make up some short name so you can recognize that it's yours.
Item 4
This is the name and address of the site of this network—usually it's your name and address.
Item 5
You can skip this question because the military's network known as MILNET uses its own forms and files them with the NIC.
Items 6 and 7
This is very important, because it determines what type of network number you get (and if you get a Class C number(s), it determines how many you get). The NIC expects the five year number to be a guess.
You will be assigned a Class C number unless your answer in Item 7 explicitly shows that because the number of networks and nodes you have that you really cannot fit into a set of Class C numbers and you require a Class B number. How you answer this
question, however, also indicates how many Class C numbers you can get. It helps to document your entire network and show how the net numbers will be used. Since address space is getting short, NIC is getting particular on how you answer this question.
Item 8
This should not be a problem. If you are a commercial organization, your net is most likely commercial.
Item 9
This needs only a short response on how you plan to use the network. The big justification is in Item 7 on the class of network required.
Filing the application is simple enough. If you are requesting a connected network number, send your application via electronic mail to your Internet service provider, who will file it with the NIC on your behalf or assign you a number from their pool
of addresses. If the application is for a nonconnected network, and you have access to electronic mail, that is the preferred method of filing. If this is not the case, print out the application and mail it to the address on the form.
Broadcast Address
In IP messages are addressed to a single node, to all nodes on the subnet, or to all nodes on the network. The last two are called broadcast addresses. When IP was first implemented, the address of all 0s for the node number was used for the broadcast
address. This was later changed to all 1s. To retain backward-compatibility, IP implementations will accept either all 0s or all 1s as the broadcast address. In addition, if the network number is all 0s or all 1s it is considered a networkwide broadcast
address. This makes the following broadcast addresses:
- x.y.z.255 Subnet broadcast on subnet x.y.z
- x.y.255.255 Subnet broadcast on subnet x.y
- x.255.255.255 Subnet broadcast on subnet x
- 255.255.255.255 Global broadcast
To prevent a broadcast address in one network from leaking to other networks by accident, most routers are configured not to propagate a broadcast across network boundaries.
Net Mask
Since the IP address is broken into two parts, the network number and the node number, some way must be used to split the address into these two parts. This is the netmask. It is a bit mask that when bit-wise anded with the full 32-bit address results
in the network number portion of the address. Although the specifications of IP do not require this mask to be a consecutive set of 1s followed by all 0s, most implementations of IP do require this. The default netmask for IP addresses is the following:
- For Class A: 255.0.0.0
- For Class B: 255.255.0.0
- For Class C: 255.255.255.0
The net mask is heavily involved in routing. Packets with a network number matching your network number are considered local and are not routed. Packets with a network number different from your network number are routed. The netmask is used to make
this distinction.
As an example, you have a Class B address of 190.109.252.6 for your workstation. This could be configured as one of the following:
- One big network with many thousands of possible addresses, with a netmask of 255.255.0.0 and a network number of 190.109.0.0 and a node address of 252.6.
- A subnet allowing only a few nodes under the big network, with a netmask of 255.255.255.0 and a network number of 190.109.252 and a node address of 6.
- A larger subnet allowing more nodes under the big network, with a netmask of 255.255.240.0 and a network number of 190.109.240.0 and a node address of 12.6.
Routing
A network by it self is not as much use as one that can connect to other networks. To get a message off your network and onto the others requires knowing where and how to deliver the packets. This is known as routing.
In IP each network keeps track of only the first hop on the route to all other networks. It keeps track of which gateway to use for each other network to which it wants to communicate. Those nodes know the next hop for the packet, and so on. Eventually
the packet reaches its destination. This is called store and forward routing, because each node in the chain receives the packet and then forwards it to the next destination. However, it is networks that have routes to gateway nodes, not nodes that have
routes.
There are several types of routes:
- Default All packets for networks you don't explicitly list elsewhere are sent to this node for forwarding. If your network has only one gateway, this is all you need.
- Static A command is used to add a route for one or more networks, and it never changes. This is used when there are a few gateways to fixed networks, and normally a default route is used for the remaining networks.
- Dynamic The system listens to broadcasts of routes from the gateways and adjusts automatically. Many Internet nodes use this method.
Routing is transparent and automatic by the system. You can turn it off by performing a modification to the TCP parameters in the operating system. Firewall gateways, which are used to protect networks from security breaches, turn off this automatic
forwarding.
Naming
Although you can refer to anything via its dotted quad, you may have difficulty remembering the dotted quad. So the developers of the Internet and IP invented a scheme to assign names to the numbers. A name can be used to map to dotted quad network node
address. Thus, the node 190.109.252.6 could be referred to as fasthost. A table of translations between the names and the dotted quads is kept on UNIX systems in /etc/hosts. Not only hosts, but also dotted quad values, can have names, as in:
- 190.109.252.0 The network on which fastnode resides could be fastnet.
- 190.109.252.255 The broadcast address for that network could be fastnet-broadcast.
- 255.255.255.0 The netmask for fastnet could be fastnet-netmask.
- 190.109.0.0 The Class B overall net could be backbone-net.
These names are interchangeable in UNIX commands with dotted quads wherever a node address or network number is needed.
Port Number
In addition to the IP address, some of the IP protocols use a port number. This is a 16-bit quantity that allows for more than one connection to the node. Each concurrent connection is to a port, and with 16 bits this limits any node to 65535
connections simultaneously. Port numbers lower than 1024 are considered privileged and require root access to open.
UDP Versus TCP
The two major protocols in IP are UCP and TDP. These two are used by most other services and protocols to transfer the data.
UDP is the simpler of the two and is an unnumbered message sent to a particular IP address and port. UNIX buffers the request and provides the message to any process that reads that port. It is a connectionless service and no acknowledgment of reception
is sent to the sending system. It is only possible to read complete messages. The messages may be of any size less than the buffer size of the UDP queue (usually less than 24 KB).
TCP is a connection-oriented protocol. It guarantees delivery of the data, in order and error free. A TCP connection is a unique combination of four values:
- The sending IP address
- The sending port number
- The receiving IP address
- The receiving port number
This allows multiple connections at the same time to the same receiving port, as all four values uniquely identify a connection. The connection is bidirectional, and what is written at one end is read by the other, and vice versa.
TCP connections work just like stream I/0 in that any number of bytes at a time can be read or written. When the connection is broken, a write receives a broken pipe error and a read receives EOF (End of File).
ARP
Behind the scenes, the IP protocol still needs to converse over the EtherNet. In doing so, it has to address the message to an EtherNet address, not just an IP address. This is necessary so that the EtherNet hardware receives the message and passes it
on for further processing. This conversion from IP address to EtherNet address is handled by the Address Resolution Protocol (ARP).
A node needing to convert an IP address to an EtherNet address for the first time broadcasts a message using the ARP protocol, asking what is the EtherNet address for a particular IP address. When a node running ARP hears its IP address, it responds
with its EtherNet address directly (not via broadcast) to the requesting node. That node then caches the result for later reuse. If an address is not used in a while, it is timed out and flushed from the cache.
RARP
The opposite translation—converting an EtherNet address to an IP address—is performed by the Reverse Address Resolution Protocol (RARP). In any network, several nodes are usually set up to run rarp daemons. (Daemons are processes that run in
the background—they are discussed later in this chapter.) These programs listen for rarp requests, and using a data table provided in a disk file, respond with the IP address that is mapped to that EtherNet address.
RARP can be used by nodes when they boot. Instead of configuring the node with its IP address in a system configuration file, it can ask the network, and therefore some central mapping server, what IP address it is to use. Once it has the IP address, it
can use the naming service or the host's file to determine its hostname. Diskless workstations have no local configuration and rely on RARP for boot time setup.
ICMP
When something goes wrong, someone has to act as traffic cop. That role belongs to the Internet Control Message Protocol (ICMP). ICMP is used to transparently control the network and for diagnostic purposes. If too much traffic is being generated by a
connection, the system can send it an ICMP source quench message and ask it to slow down. If a packet is being sent to a host that a gateway knows does not exist, an ICMP host unreachable message is returned. If a gateway receives a packet, but doesn't
know how to route it to its final destination, a ICMP network unreachable message is returned. If the wrong gateway is used for a packet, an ICMP redirect message is used to instruct the connection about the proper route. But the most well-known ICMP
message is echo. It just echoes what it receives and is how the ping command works. (ping is covered later in this chapter.)
Well-Known Services
Many daemons listen for connections on pre-agreed on ports. These are the well-known services. The port numbers are specified in the file /etc/services. Many of these services are controlled by the Internet dispatch daemon, inetd.
Telnet
Remote serial communication via IP is performed via telnet. The receiving UNIX system listens either via a telnetd daemon or via inetd for telnet connection requests on TCP port 23. A connection request is made using the telnet program. Once a
connection is established, telnetd establishes a connection to the login program, and a remote login session is started.
FTP
If an interactive session isn't needed, but file transfer is desired, the file transfer protocol (ftp) is used. ftp is actually run under the TCP protocol, but is called a protocol itself because it uses specific commands to transfer the information.
Again, as with telnet, an ftpd or inetd listens for a connection on TCP port 20. Using the ftp program a UNIX user establishes a connection. The ftpd program accepts login information and provides file transfer capabilities both to and from each system.
ftp is one of the original four-letter command and three-digit response protocols that are common in TCP/IP. Commands sent from ftp to ftpd include USER to log in and PASS to provide the password. Responses are three-digit numeric codes with a
human-readable explanation following. The number codes are divided into response groups:
- 1xx Informative message.
- 2xx Command succeeded.
- 3xx Command ok so far, send the rest of it.
- 4xx Command was correct, but couldn't be performed for some reason. This error group generally means try again later.
- 5xx Command unimplemented, or incorrect, or a serious problem has occurred. Abort this command and do not retry it later.
This same protocol style is used by almost all protocols run on top of TCP/IP.
DNS
Whereas telnet and ftp are examples of TCP-based services, the domain name service (DNS) is an example of a UDP-based service. The DNS daemon, named, listens on UDP port 53. When it receives a request to look up a name or number, it searches in memory
tables for the answer. If it has seen the answer recently, it can respond immediately from its in-memory tables. If not, it asks a higher-level server whom to ask for this query and then requests the information from that server. This provides a very
fast-responding, totally distributed naming service.
Haste Makes Waste, So Plan!
Providing a reliable, responsive network takes planning. Except in the smallest of networks, you can't just connect all the systems together, slap on any address, and then expect everything to work perfectly. This section contains some guidelines to
help you plan your network so that it works not only reliably but also responsively for your UNIX system.
Segmenting the Network
Depending on how you plan to use the network, UNIX systems can place much more traffic on a network than can a comparable number of PCs or Macs. If you intend to share disk resources across the network using NFS, UNIX can saturate a network very
quickly.
In designing a UNIX network, you need to keep in mind the following goals:
- Diskless and dataless clients should be on the same segment as their servers.
- File servers can be on the same segment, or if they serve multiple segments, on a backbone segment.
- Don't overload any segment. Depending on the amount of file sharing, 12 to 24 nodes per segment should be considered full.
- Place servers for broadcast services, such as RARP and BOOTP, on each segment and do not transmit broadcasts between segments.
- Use bridging routers or routers to connect the segments to the backbone.
Although each segment as well as the backbone needs its own network address, you do not need to use a Class C address for each network. With only 24 nodes per network being considered full load, using 5 bits for the node address will allow 30 nodes.
This give 3 bits for subnetting, allowing 6 networks to share the same Class C address.
Draw a Map
It really helps when planning a network to draw a logical connection map such as the one in Figure 37.4. This map does not show the geography of the net, but it does show its logical topology. Note how I listed the node addresses of each gateway to the
network on the map. You use these to make up your routing tables.
Draw several maps, at different level of details. It's not necessary, nor even desirable, to show which nodes are connected to each of the networks in the map. But each of the subnets would also have its own map showing every node connected and their
addresses. Having and keeping these maps up-to-date might take a small amount of time, but it's worthwhile when you have to figure out configurations or troubleshoot the network.
Down to the Wire
So far this chapter has dealt with the network as a virtual entity. It's time to give the network some identity. Most UNIX systems connect to an EtherNet-type local area network. EtherNet was invented by Xerox to act as a network for their printers and
it was perfected by a cooperative effort of DEC, Intel, and Xerox. EtherNet is a bus-based network in which all nodes on the network can hear all other nodes. All EtherNets share some common features:
- A 10 MB-per-second transfer rate.
- Limited distance for the network cable. The actual limit is based on the cable type and it ranges from 250 meters (10BASE2) to about 750 meters (10BASE5).
- A limit on the number of nodes possible on a segment.
- Uses the Carrier Sense Multi-Access with Collision Detection protocol for transmission on the cable.
- Uses a 48-bit Media Access Control (MAC) address that is unique. The first 24 bits are the vendor and model of the EtherNet adapter, the last 24 bits are a serial number. No two EtherNet adapters are supposed to have the same MAC-level address.
Specialized chips now handle the mechanics of listening to the network, deciding when to transmit, transmitting, receiving, and filtering packets.
Types of EtherNets
EtherNet comes in three main connection types, which describe the type of cable used.
10BASE5, or Thicknet
This is the original EtherNet. It is a triaxial cable, usually yellow or orange in color, with black bands every 2 meters. The nodes are connected to the cable using taps at those black bands. While rarely used for new installations any longer, many
backbones have used this connection method.
Thicknet networks require external transceivers to connect the EtherNet board to the cable. A drop cable called an AUI (Attachment Unit Interface) cable is used to connect the transceiver to the network board. The AUI cable has 15 pin connectors on each
end and uses a special variant of the DB-15 connector with an unusual slide-locking mechanism.
Thicknet is the most expensive method of connecting nodes, but can also connect the most nodes over the longest distances.
10BASE2, or Thinnet
In an effort to reduce costs, the next development was to place the transceiver directly on the board and drop the expensive triaxial cable for inexpensive RG-58/U cable and BNC connectors. This led to Thinnet, or as it is often called, Cheapernet. In
10BASE5 the transceivers tap onto the cable and an AUI stub cable allows the node to be up to 30 meters from the network backbone cable. In 10BASE2 the cable is looped through each node and a BNC T-connector is used to connect directly to the network
board.
10BASE2 networks are limited in distance to several hundred meters, and a fault at any point in the network usually takes down the entire network. However, 10BASE2 networks are very reliable.
10BASET, or Twisted Pair
The newest type of EtherNet simulates the bus topology, using a star configuration and a central repeating hub. It uses two twisted-pair cables running directly from each node to a central hub. At the node end, these cables are usually terminated in an
RJ-45 connector that looks like a telephone plug but is 8 pins wide instead of the usual 6 for the RJ-11.
At the hub end many different connection types are used, including RJ-45 for single lines and 25 pair Amphenol connectors for multiple terminations. Hubs are available with from 4 to hundreds of ports and many even have sophisticated monitoring
abilities.
This method was developed to allow EtherNet to use existing twisted-pair telephone cabling. However, it works better if type 3 network cabling is used. It is also the least expensive method of wiring a new network.
What Is a Hub?
10BASET networks need a central device to repeat the signals from each leg of the star onto all other legs. This is performed by a hub. It converts the star back into a logical bus topology. It also provides signal conditioning and regeneration to allow
the twisted-pair cable to be used at EtherNet speeds.
Hubs are content-passive devices in that anything received on one port is retransmitted on all other ports of the hub.
What Is a Repeater?
Because EtherNets are limited in length due to signal timings and attenuation, a device was needed to regenerate the signals to extend the network. This is the repeater. It is connected between two segments of an EtherNet network and repeats whatever it
hears on one segment onto the other segment.
Repeaters are also content-passive devices in that anything received from one segment is repeated on the other one.
What Is a Bridge?
A bridge is also used to connect two segments of a network. However, its not content passive. It is a link-level filtering device. It reads the EtherNet MAC header, looking for the MAC-level address. If the address is for another node it recognizes as
being on the same segment on which it received the packet, it discards the packet. If it is a broadcast packet, or one it does not recognize, it repeats the packet onto the other network.
Bridges have to read the packet to determine the address, so there is a delay inherent in going through a bridge. This delay could be just long enough to read the MAC header and determine whether to forward the packet. Other bridges store the entire
packet and then retransmit it. This type of bridge has a longer delay because it must read not just the header but the entire packet.
Bridges are rated by the number of packets per second they can forward.
What Is a Router?
Whereas a bridge makes its decision based on the link level or MAC address, a router makes its forwarding decisions based on the network level or IP address. Routers read the entire packet into memory, and then decide what to do with the packet, based
on its contents.
Whereas bridges work at the EtherNet level and do not need to understand the protocol being used in the messages, routers work at the network level and need special software to understand every network protocol being used (IP, IPX, DECNET, and so on).
Routers are very configurable and can be used to filter packets and isolate networks from other network problems. Some configurations can also be used as security filters to keep out unwanted traffic.
However, for all this flexibility and protection you pay a price. Routers are more expensive and slower than bridges. They must read in the entire packet, and this causes a delay at least equal to the time it takes to read in the entire packet. This
delay is called latency, and although it has little effect on throughput, it does effect response time.
What Is Switched EtherNet?
With the growth in networking and multimedia software, the old 10 MB/s EtherNet is showing its age. One stop gap measure on the way to faster networks is switched EtherNet. Using a special computer as a switch, a private EtherNet is created between the
switch and each node. Then the switch forwards the packets onto the desired node on its private EtherNet connection.
This breaks the bus and sends only broadcast and addressed traffic to each node. The overall traffic can be higher when each node talks to many other nodes. It works well, but introduces latency. The switch must delay the packet at least long enough to
read the MAC-level address. Often switches are implemented as a store and forward bridge.
In addition, the use of switched Ethernet makes it more difficult to diagnose problems on the network because you can no longer listen in to the bus from any node to determine where problems are occurring.
How to Segment and Expand an EtherNet Network
When a segment is getting too full, the first thing to do is to split it into two segments connected by a bridge. This reduces the traffic on each segment, but does not require you to readdress all of the IP addresses on the network.
Place all diskless systems on the same segment as their servers and try to split the groups of servers and workstations across both segments. Then split the network and place a bridge between the two segments.
If this is insufficient for the growth, it will be necessary to split the network into two or more subnets and use routing instead of bridging to reduce the traffic load.
Configuring TCP/IP
When you first hook a UNIX system to the network there are many files that need to be populated with the data describing the IP network. Several of these files have default contents provided by the vendor. These may be sufficient, but often there are
additions needed. This section describes the contents of the UNIX TCP/IP configuration files found in the /etc directory.
Assigning Addresses—/etc/hosts
The hosts file is used for translating names into IP addresses and IP addresses back into names. A sample file consists of:
# # Internet host table # 127.0.0.1 localhost loghost 190.109.252.1 gateway 190.109.252.2 sn1-router 190.109.252.33 sn1-gateway 190.109.252.34 sn1-host sn1-boothost
The # is the common character, which means that the system ignores all the characters that appear on a line following the #.
Entries are individual lines. Each entry starts with the dotted quad for the IP address, followed by white space, blanks, and/or tabs, and a list of names for this host. Any one of the names listed will be translated into the IP address. Looking up the
hostname for an IP address will return the first name listed. All the rest of the names are considered aliases.
Naming Networks—/etc/networks
Just as it is easier to refer to hosts by name rather than by number, it's also easiest to refer to networks by name. A file is provided to separate network numbers from host numbers. This file differs from the hosts file in that only the network number
portion is listed in the file as seen in this example:
# # The networks file associates Internet Protocol (IP) network # numbers with network names. The format of this file is: # # network-name network-number nicnames . . . # # # The loopback network is used only for intra-machine communication # loopback 127 # # Internet networks # arpanet 10 arpa # Historical subnet 190.109.252 subnet-seg1 190.109.252.32 subnet-seg2 190.109.252.64
Choosing the Netmask for a Network—/etc/netmasks
Normally when a netmask is needed, the IP system looks at the address class and chooses a netmask that matches the class of the address. However, as in the subnetting example, often a different netmask is needed. These exceptions to the rule are listed
in the netmasks file as shown in this example:
# # The netmasks file associates Internet Protocol (IP) address # masks with IP network numbers. # # network-number netmask # # Both the network-number and the netmasks are specified in # "decimal dot" notation, e.g: # # 128.32.0.0 255.255.255.0 # 190.109.252.0 255.255.255.0 190.109.252.32 255.255.255.224 190.109.252.64 255.255.255.224
A command that needs a netmask can either take the netmask as an override on the command line or consult the netmasks file to determine if there is a specific netmask before resorting to calculating one based on the class of the address.
Mapping Names to Machines—/etc/ethers
BOOTP and RARP need a file to map EtherNet addresses into IP numbers. This is provided by the ethers file, which maps the EtherNet MAC address into a hostname. Then the hosts file is used to map this into an IP address.
# # The ethers file associates ethernet addresses with hostnames # 08:00:20:0e:b9:d3 gateway 08:00:20:11:30:d0 sn1-router 08:00:20:0e:1d:0b sn1-gateway 08:00:20:0b:de:0d sn1-host
By placing the IP address in only the hosts file and making use of RARP for assigning network numbers, it is possible to readdress an entire network just by changing the hosts file and rebooting the machines. This makes changes very convenient.
Mapping Names to Interfaces—/etc/hostname.??n
Many UNIX systems have more than one network interface. Each network interface on a host has its own IP address. Because a node name can appear only once in the /etc/hosts file, each interface also has its own node name. So the node, on boot, still
needs to know which name, and therefore which IP address, to use on which network interface.
This is provided by the file /etc/hostname.??n where ?? is the name of the interface type, and n is a digit referring to the interface number. On Suns this is usually /etc/hostname.le0 for the first interface, /etc/hostname.le1 for
the second, and so on.
This file contains just one line with one word on that line, the hostname to use for that particular interface:
fasthost
Naming Supported Protocols—/etc/protocols
To enable the diagnostic output of the utilities to list the protocols by name rather than by protocol number, a mapping is kept in the file /etc/protocols. This file is provided by the vendor and should not need changing. Not all the protocols listed
in this file are necessarily supported on your system. An example of the contents of /etc/protocols is as follows:
# # Internet (IP) protocols # ip 0 IP # internet protocol, pseudo protocol number icmp 1 ICMP # internet control message protocol ggp 3 GGP # gateway-gateway protocol tcp 6 TCP # transmission control protocol egp 8 EGP # exterior gateway protocol pup 12 PUP # PARC universal packet protocol udp 17 UDP # user datagram protocol hmp 20 HMP # host monitoring protocol xns-idp 22 XNS-IDP # Xerox NS IDP rdp 27 RDP # "reliable datagram" protocol
Naming Supported Services—/etc/services
Programs that wish to connect to a specific port use the services file to map the service name to the port number. This file is shipped from your vendor with all the default services in it. Local services can be added to support databases or any local
extensions desired. The file is large, so the following example is only a small extract. Remember that ports smaller than 1024 are privileged and can only be listened on by processes owned by root.
# # Network services, Internet style # This file is never consulted when the NIS are running # tcpmux 1/tcp # rfc-1078 echo 7/tcp echo 7/udp discard 9/tcp sink null discard 9/udp sink null systat 11/tcp users daytime 13/tcp daytime 13/udp netstat 15/tcp chargen 19/tcp ttytst source chargen 19/udp ttytst source ftp-data 20/tcp ftp 21/tcp telnet 23/tcp smtp 25/tcp mail time 37/tcp timserver time 37/udp timserver name 42/udp nameserver whois 43/tcp nicname # usually to sri-nic domain 53/udp domain 53/tcp hostnames 101/tcp hostname # usually to sri-nic sunrpc 111/udp sunrpc 111/tcp ident 113/tcp auth tap # # Host specific functions # bootps 67/udp # bootp server bootpc 68/udp # bootp client tftp 69/udp rje 77/tcp finger 79/tcp link 87/tcp ttylink supdup 95/tcp iso-tsap 102/tcp x400 103/tcp # ISO Mail x400-snd 104/tcp csnet-ns 105/tcp pop-2 109/tcp # Post Office auth 113/tcp uucp-path 117/tcp nntp 119/tcp usenet # Network News Transfer ntp 123/tcp # Network Time Protocol ntp 123/udp # Network Time Protocol snmp 161/udp # # UNIX specific services # # these are NOT officially assigned # exec 512/tcp login 513/tcp shell 514/tcp cmd # no passwords used printer 515/tcp spooler # line printer spooler courier 530/tcp rpc # experimental uucp 540/tcp uucpd # uucp daemon biff 512/udp comsat who 513/udp whod syslog 514/udp talk 517/udp ntalk 518/udp route 520/udp router routed timed 525/udp timeserver new-rwho 550/udp new-who # experimental rmonitor 560/udp rmonitord # experimental monitor 561/udp # experimental pcserver 600/tcp # ECD Integrated PC board srvr kerberos 750/udp kdc # Kerberos key server kerberos 750/tcp kdc # Kerberos key server
The format of the file is the name of the service followed by white space, then the port number, followed by a / and the protocol (either TCP or UDP). This is optionally followed by nicknames for the service. If a service is available both under UDP and
TCP it must be listed twice in the file, once for UDP and once for TCP.
Binding Daemons to Services—/etc/inetd.conf
Rather than having each task listen for connections on its own ports, UNIX uses a common daemon to listen on many ports at once. This is the Internet services daemon or inetd. It listens on every port listed in its configuration file. When it receives a
connection it forks off and starts the appropriate service daemon. Some services are handled internally by inetd, including daytime and echo.
When you change the inetd.conf file you need to signal the daemon to reread the file. Sending inetd the HUP signal causes it to reread the file. HUP is the signal 1 so you can use the following commands to have inetd reread the /etc/inetd.conf file:
kill -HUP pid
Alternatively, you can enter this:
kill -1 pid
In these commands pid is replaced by the pid of the inetd process, which will cause inetd to reread its configuration file. The following is a small sample of the file to show the format:
#
# Configuration file for inetd(1M). See inetd.conf(4).
#
# To re-configure the running inetd process, edit this file, then
# send the inetd process a SIGHUP.
#
# Syntax for socket-based Internet services:
# <service_name> <socket_type> <proto> <flags> <user> <server_pathname> <args>
#
# Syntax for TLI-based Internet services:
#
# <service_name> tli <proto> <flags> <user> <server_pathname> <args>
#
# Ftp and telnet are standard Internet services.
#
ftp stream tcp nowait root /etc/in.tcpd in.ftpd
telnet stream tcp nowait root /etc/in.tcpd in.telnetd
#
# Shell, login, exec, comsat and talk are BSD protocols.
#
shell stream tcp nowait root /etc/in.tcpd in.rshd
login stream tcp nowait root /etc/in.tcpd in.rlogind
#
#
# RPC services syntax:
# <rpc_prog>/<vers> <endpoint-type> rpc/<proto> <flags> <user> \
# <pathname> <args>
#
# <endpoint-type> can be either "tli" or "stream" or "dgram".
# For "stream" and "dgram" assume that the endpoint is a socket descriptor.
# <proto> can be either a nettype or a netid or a "*". The value is
# first treated as a nettype. If it is not a valid nettype then it is
# treated as a netid. The "*" is a short-hand way of saying all the
# transports supported by this system, ie. it equates to the "visible"
# nettype. The syntax for <proto> is:
# *|<nettype|netid>|<nettype|netid>{[,<nettype|netid>]}
# For example:
# dummy/1 tli rpc/circuit_v,udp wait root /tmp/test_svc test_svc
#
# System and network administration class agent server
#
# This is referenced by number because the admind agent is needed for the
# initial installation of the system. However, on some preinstalled systems
# the SNAG packages may not be present. Referencing the service by number
# prevents error messages in this case.
#
100087/10 tli rpc/udp wait root /usr/sbin/admind admind
Dealing with Naming
There are three methods of translating names and IP addresses commonly in use in UNIX networking:
- /etc files The C library routines will use the files in the /etc directory to perform the translations.
- NIS The Network Information Service will be used. Calls are made by the C library routines to the NIS server for translation of the names and numbers.
- DNS The Internet Domain Name Service is used. Calls are made by the C library routines to the DNS server for translation of the names and numbers.
This choice is controlled by a combination of methods:
- The presence of the file /etc/resolv.conf On some systems, providing this file automatically enables the use of DNS. This file is required for DNS and lists the default domain name and the IP address of your DNS servers as in:
domain conglomerate.com
nameserver 190.109.252.17
nameserver 190.109.252.37
- Installation of a special shared library Some systems have the choice of naming service compiled directly into the shared library. This was true for older BSD systems such as SunOS 4. In these systems you need to build a new shared library to
change the method.
- Specifying the method in /etc/nssswitch.conf Newer operating systems provide a control file to specify how to perform naming lookup. The contents of this file specify which method to use. The sample below uses NIS and DNS, but not the files in
/etc:
#
# /etc/nsswitch:
#
# An example file that could be copied over to
# /etc/nsswitch.conf
# It uses NIS (YP) in conjunction with files and DNS for hosts.
#
# "hosts:" and "services:" in this file are used only if the
transports.
# the following two lines obviate the "+" entry in /etc/passwd and
/etc/group.
passwd: files nis
group: files nis
# consult /etc "files" only if nis is down.
hosts: nis dns [NOTFOUND=return] files
networks: nis [NOTFOUND=return] files
protocols: nis [NOTFOUND=return] files
rpc: nis [NOTFOUND=return] files
ethers: nis [NOTFOUND=return] files
netmasks: nis [NOTFOUND=return] files
bootparams: nis [NOTFOUND=return] files
publickey: nis [NOTFOUND=return] files
netgroup: nis
automount: files nis
aliases: files nis
# for efficient getservbyname() avoid nis
services: files nis
sendmailvars: files
- System V Release 4 (SRV4) uses the /etc/netconfig This file specifies which shared libraries are to be used to perform name lookups as well as other TCP services. The sample below uses the file first and DNS second:
##
# The Network Configuration File.
#
# Each entry is of the form:
#
# network_id semantics flags protofamily protoname device nametoaddr_libs
#
ticlts tpi_clts v loopback - /dev/ticlts /usr/lib/straddr.so
ticots tpi_cots v loopback - /dev/ticots /usr/lib/straddr.so
ticotsord tpi_cots_ord v loopback - /dev/ticotsord /usr/lib/straddr.so
tcp tpi_cots_ord v inet tcp /dev/tcp /usr/lib/tcpip.so,/ _usr/lib/resolv.so
udp tpi_clts v inet udp /dev/udp /usr/lib/tcpip.so,/_usr/lib/resolv.so
icmp tpi_raw - inet icmp /dev/icmp /usr/lib/tcpip.so,/usr/lib/resolv.so
rawip tpi_raw - inet - /dev/rawip /usr/lib/tcpip.so,/usr/_lib/resolv.so
Starting TCP/IP at Boot Time
TCP/IP doesn't just magically start when UNIX is booted. The interfaces, addresses, and routes all need to be configured. In addition, daemons need to be started. This is performed automatically at boot time by the start-up scripts. On BSD-derived
systems, this is in /etc/rc.boot to set up the protocol and /etc/rc.local to start the rest. On SVR4, it's /etc/init.d/inetinit, which also runs /etc/inet/rc.inet. On Solaris 2, it's /etc/init.d/rootusr to set the hostname, /etc/init.d/inetinit for the
main configuration, and /etc/init.d/inetsvc for the services that need NIS to be running before they can be started.
In all three cases it's necessary to configure the protocol, set the parameters for the hostname and address, and start the daemons.
Starting TCP/IP
The TCP/IP protocol stack is implemented differently in BSD and SVR4 operating systems. On BSD it's part of the kernel. On SVR4 it's a streams driver and is configured at run time. This leads to different start-up scripts.
BSD Start-Up
Starting TCP/IP on SunOS and other BSD systems requires initializing the network interface with its address and then enabling it. This is performed in /etc/rc.boot. Using the relevant portions of the rc.boot file, here are the steps in configuring a BSD
system:
##! /bin/sh -
#
# @(#)rc.boot 1.44 90/11/02 SMI
#
# Executed once at boot time
#
PATH=/sbin:/single:/usr/bin:/usr/etc; export PATH
HOME=/; export HOME
. . .
#
# Set hostname from /etc/hostname.xx0 file, if none exists no harm done
#
hostname="'shcat /etc/hostname.??0 2>/dev/null'"
if [ ! -f /etc/.UNCONFIGURED -a ! -z "$hostname" -a "$hostname" != "noname" ];
then
hostname $hostname
fi
#
# Get the list of ether devices to ifconfig by breaking /etc/hostname.* into
# separate args by using "." as a shell separator character, then step
# through args and ifconfig every other arg.
#
interface_names="'shcat /etc/hostname.*2>/dev/null'"
if test -n "$interface_names"
then
(
IFS="$IFS."
set 'echo /etc/hostname\.*'
while test $# -ge 2
do
shift
if [ "$1" != "xx0" ]; then
ifconfig $1 "`shcat /etc/hostname\.$1`" netmask + -trailers up
fi
shift
done
)
fi
#
# configure the rest of the interfaces automatically, quietly.
#
ifconfig -ad auto-revarp up
. . .
ifconfig lo0 127.0.0.1 up
#
# If "/usr" is going to be NFS mounted from a host on a different
# network, we must have a routing table entry before the mount is
# attempted. One may be added by the diskless kernel or by the
# "hostconfig" program above. Setting a default router here is a problem
# because the default system configuration does not include the
# "route" program in "/sbin". Thus we only try to add a default route
# at this point if someone managed to place a static version of "route" into
# "/sbin". Otherwise, we add the route in "/etc/rc.local" after "/usr"
# has been mounted and NIS is running.
#
# Note that since NIS is not running at this point, the router's name
# must be in "/etc/hosts" or its numeric IP address must be used in the file.
#
if [ -f /sbin/route -a -f /etc/defaultrouter ]; then
route -f add default 'cat /etc/defaultrouter' 1
fi
The first block of code accessing hostname.xx0 sets the overall hostname for this system. It is the name that the hostname command will return. A loop is then run on each of the hostname. files to configure their interfaces using ifconfig. It uses the
default netmask computed or residing in the /etc/netmasks file and the host address as listed in the /etc/hosts file. It cannot use DNS or NIS at this point because the network is not yet able to ask someone else. Then it configures the loopback interface,
which is always at address 127.0.0.1. Finally, it tries to set up a default route to allow the /usr file system to be NFS mounted if it's shared.
The rc.local file is used to finalize the configuration once NIS is running. It sets the final address, netmask, and routes. This code excerpt shows the relevant sections that control this initialization:
#
# @(#)rc.local 1.116 91/05/10 SMI; from UCB 4.27 83/07/06
#
. . .
# set the netmask from NIS if running
# or /etc/netmasks for all ether interfaces
ifconfig -a netmask + broadcast + > /dev/null
#
# Try to add a default route again, now that "/usr" is mounted and NIS
# is running.
#
if [ ! -f /sbin/route -a -f /etc/defaultrouter ]; then
route -f add default 'cat /etc/defaultrouter' 1
fi
. . .
# If we are a diskless client, synchronize time-of-day with the server.
#
server='grep ":.*[ ][ ]*/[ ]" /etc/fstab |
sed -e "/^#/d" -e "s/:.*//"`
if [ "$server" ]; then
intr -a rdate $server
fi
#
# Run routed only if we don't already have a default route installed.
#
defroute="'netstat -n -r | grep default'"
if [ -z "$defroute" ]; then
if [ -f /usr/etc/in.routed ]; then
in.routed; echo 'running routing daemon.'
fi
fi
Only if there is no default route does the rc.local script automatically start the routing daemon to listen for route broadcasts.
SVR4 Start-Up
If you use SVR4 you must first load the streams modules into the system. It then performs the interface configuration. /etc/inetd.inet runs the file /etc/confnet.d/inet/config.boot.sh. The file is not as straightforward as the BSD rc.boot and is very
large, so it is not listed here. However, it completes the following steps:
- It determines from the system configuration information (/etc/confnet.d/inet/interfaces) which network devices exist.
- It loops over those devices performing the following:
Address determination for the interface from the interfaces file
Installation of the protocol stack onto the stream head for the interface device
ifconfig of the interface to set its address, netmask, and broadcast address
The loopback devices is listed in the interfaces file and is handled as part of the loop.
When the interfaces are up, the /etc/inet/rc.inet file is used to start the daemons. As the following excerpt shows, if you need to start other daemons or set up static routes, you will have to edit this file yourself to add the commands. Just place
them were indicated in the comments.
# @(#)rc.inet 1.5 STREAMWare TCP/IP SVR4.2 source
# Inet startup script run from /etc/init.d/inetinit
. . .
#
# Add lines here to set up routes to gateways, start other daemons, etc.
#
#
# Run the ppp daemon if /etc/inet/ppphosts is present
#
if [ -f /etc/inet/ppphosts -a -x /usr/sbin/in.pppd ]
then
/usr/sbin/in.pppd
fi
# This runs in.gated if its configuration file (/etc/inet/gated.conf) is
# present. Otherwise, in.routed is run.
#
if [ -f /etc/inet/gated.conf -a -x /usr/sbin/in.gated ]
then
/usr/sbin/in.gated
else
#
# if running, kill the route demon
#
kill 'ps -ef|grep in[.]routed|awk '{print $2}'' 2>/dev/null
/usr/sbin/in.routed -q
fi
#
# /usr/sbin/route add default your_nearest_gateway hops_to_gateway
# if [ $? -ne 0 ]
# then
# exitcode=1
# fi
#
# Run the DNS server if a configuration file is present
#
if [ -f /etc/inet/named.boot -a -x /usr/sbin/in.named ]
then
/usr/sbin/in.named
fi
#
# Run the NTP server if a configuration file is present
#
if [ -f /etc/inet/ntp.conf -a -x /usr/local/etc/xntpd ]
then
/usr/local/etc/xntpd
fi
Solaris 2 Start-Up Code
Solaris 2 uses a slightly different configuration. It splits the task into three parts, which are listed in the following sections.
/etc/init.d/rootusr
You need to configure enough of the network to be able to NFS mount /usr if needed. Except for the pathnames, this code is almost identical to the code in the BSD /etc/rc.boot.
#
# Configure the software loopback driver. The network initialization is
# done early to support diskless and dataless configurations.
#
/sbin/ifconfig lo0 127.0.0.1 up 2>&1 >/dev/null
#
# For interfaces that were configured by the kernel (e.g. those
# on diskless machines), reset the netmask using the local
# "/etc/netmasks" file, if one exists.
#
/sbin/ifconfig -au netmask + broadcast + 2>&1 >/dev/null
#
# Get the list of network interfaces to configure by breaking
# /etc/hostname.* into separate args by using "." as a shell
# separator character, then step through args and ifconfig
# every other arg. Set the netmask along the way using local
# "/etc/netmasks" file. This also sets up the streams plumbing
# for the interface. With an empty /etc/hostname.* file this
# only sets up the streams plumbing allowing the ifconfig
# auto-revarp command will attempt to set the address.
#
interface_names="'echo /etc/hostname.*[0-9]2>/dev/null'"
if test "$interface_names" != "/etc/hostname.*[0-9]"
then
(
echo "configuring network interfaces:\c"
IFS="$IFS."
set 'echo /etc/hostname\.*[0-9]'
while test $# -ge 2
do
shift
if [ "$1" != "xx0" ]; then
addr='shcat /etc/hostname\.$1'
/sbin/ifconfig $1 plumb
if test -n "$addr"
then
/sbin/ifconfig $1 "$addr" netmask + \
broadcast + - trailers up \
2>&1 > /dev/null
fi
echo " $1\c"
fi
shift
done
echo "."
)
fi
#
# configure the rest of the interfaces automatically, quietly.
#
/sbin/ifconfig -ad auto-revarp netmask + broadcast + -trailers up \
2>&1 >/dev/null
#
# Set the hostname from a local config file, if one exists.
#
hostname="'shcat /etc/nodename 2>/dev/null'"
if [ ! -z "$hostname" ]; \
then
/sbin/uname -S $hostname
fi
#
# Otherwise, set host information from bootparams RPC protocol.
#
if [ -z "`/sbin/uname -n`" ]; then
/sbin/hostconfig -p bootparams
fi
#
# If local and network configuration failed, re-try network
# configuration until we get an answer. We want this loop to be
# interruptable so that the machine can still be brought up manually
# when the servers are not cooperating.
#
trap 'intr=1' 2 3
while [ -z "`/sbin/uname -n`" -a ! -f /etc/.UNCONFIGURED -a -z "${intr}" ];
do
echo "re-trying host configuration..."
/sbin/ifconfig -ad auto-revarp up 2>&1 >/dev/null
/sbin/hostconfig -p bootparams 2>&1 >/dev/null
done
trap 2 3
echo "Hostname: `/sbin/uname -n`" >&2
#
# If "/usr" is going to be NFS mounted from a host on a different
# network, we must have a routing table entry before the mount is
# attempted. One may be added by the diskless kernel or by the
# "hostconfig" program above. Setting a default router here is a
# problem because the default system configuration does not include the
# "route" program in "/sbin". Thus we only try to add a default route
# at this point if someone managed to place a static version of
# "route" into "/sbin". Otherwise, we may add the route at run
# level 2 after "/usr" has been mounted and NIS is running.
#
# Note that since NIS is not running at this point, the router's name
# must be in "/etc/hosts" or its numeric IP address must be used in
the file.
#
if [ -f /sbin/route -a -f /etc/defaultrouter ]; then
/sbin/route -f add default 'cat /etc/defaultrouter' 1
fi
When this script is completed, each interface has its IP address configured and is available for use.
/etc/init.d/inetinit
This is the configuration of the network before NIS is started. Because the name-mapping abilities provided by NIS are not yet available, all this code does is to initialize the routes, as shown below:
#
# This is the second phase of TCP/IP configuration. The first
# part, run in the "/etc/rcS.d/S30rootusr.sh" script, does all
# configuration necessary to mount the "/usr" filesystem via NFS.
# This includes configuring the interfaces and setting the
# machine's hostname. The second part, run in this script, does all
# configuration that can be done before NIS or NIS+ is started.
# This includes configuring IP routing, setting the NIS domainname
# and seting any tunable paramaters. The third part, run in a
# subsequent startup script, does all configuration that may be
# dependent on NIS/NIS+ maps. This includes a final re-configuration
# of the interfaces and starting all internet services.
#
#
# Set configurable parameters.
#
ndd -set /dev/tcp tcp_old_urp_interpretation 1
#
# Configure a default router, if there is one. An empty
# /etc/defaultrouter file means that any default router added by the
# kernel during diskless boot is deleted.
#
if [ -f /etc/defaultrouter ]; then
defroute="'cat /etc/defaultrouter'"
if [ -n "$defroute" ]; then
/usr/sbin/route -f add default $defroute 1
else
/usr/sbin/route -f
fi
fi
#
# Set NIS domainname if locally configured.
#
if [ -f /etc/defaultdomain ]; then
/usr/bin/domainname 'cat /etc/defaultdomain'
echo "NIS domainname is `/usr/bin/domainname`"
fi
#
# Run routed/router discovery only if we don't already have a default
# route installed.
#
if [ -z "$defroute" ]; then
#
# No default route was setup by "route" command above -
# check the kernel routing table for any other default route.
#
defroute="'netstat -rn | grep default'"
fi
if [ -z "$defroute" ]; then
#
# Determine how many active interfaces there are and how many
# pt-pt interfaces. Act as a router if there are more than 2
# interfaces (including the loopback interface) or one or
# more point- point interface. Also act as a router if
# /etc/gateways exists.
#
numifs='ifconfig -au | grep inet | wc -l'
numptptifs='ifconfig -au | grep inet | egrep -e '—>' | wc -l'
if [ $numifs -gt 2 -o $numptptifs -gt 0 -o -f /etc/gateways ];
then
# Machine is a router: turn on ip_forwarding, run routed,
# and advertise ourselves as a router using router discovery.
echo "machine is a router."
ndd -set /dev/ip ip_forwarding 1
if [ -f /usr/sbin/in.routed ]; then
/usr/sbin/in.routed -s
fi
if [ -f /usr/sbin/in.rdisc ]; then
/usr/sbin/in.rdisc -r
fi
else
# Machine is a host: if router discovery finds a router then
# we rely on router discovery. If there are not routers
# advertising themselves through router discovery
# run routed in space-saving mode.
# Turn off ip_forwarding
ndd -set /dev/ip ip_forwarding 0
if [ -f /usr/sbin/in.rdisc ] && /usr/sbin/in.rdisc -s; then
echo "starting router discovery."
elif [ -f /usr/sbin/in.routed ]; then
/usr/sbin/in.routed -q;
echo "starting routing daemon."
fi
fi
fi
/etc/init.d/inetsvc
After NIS has started, the rest of the network configuration daemons are started by the execution of the /etc/init.d/inetsrv file. This script is very much like the remainder of the SVR4 rc.inet script. It starts the daemons in the same manner and is
not listed here.
The Configuration Tools
Several tools are used by the configuration scripts. These same tools can be used directly by you to manually affect the configuration.
ifconfig
Interface configuration, or ifconfig, sets the IP address, broadcast address, and netmask used by a network interface. It also is used to mark the interface UP (enabled) or DOWN (disabled). ifconfig can also be used to report on the status of the
network interfaces. Use the ifconfig with the -a option at the shell prompt:
# ifconfig -a <ENTER>
lo0: flags=849<UP,LOOPBACK,RUNNING,MULTICAST> mtu 8232
inet 127.0.0.1 netmask ff000000
le0: flags=863<UP,BROADCAST,NOTRAILERS,RUNNING,MULTICAST> mtu 1500
inet 190.109.252.33 netmask ffffff00 broadcast 190.109.252.63
#
It reports on the interfaces by name, listing the current parameters (flags) both numerically and by their meaning. In addition, it prints the maximum transfer unit (largest packet allowed on the network interface) and the addresses. ifconfig is covered
in greater detail later in this chapter.
route
The next hop in a route is set with the route command. It can set static and default routes. The following could be entered at the shell prompt:
# route add default gateway 1 #
The route command has four arguments:
- command Add, delete.
- network What network to add. The network name is either numeric or it's converted by a lookup in /etc/networks. The keyword default is a special token to mean the default route.
- address The address of the node that is the next hop. It is looked up in /etc/hosts if not a dotted quad.
- metric How expensive (how slow) this route is. Any route off the current network must have a metric of at least 1. Higher metrics are used to prevent usage of slow links when faster links are available.
Alternatively, the daemon routed will listen for routing broadcasts and add the routes automatically.
The routing table is printed using the netstat command.
rdate/ntpdate
When systems share files with NFS, it's best that they agree on the time of day. This allows makefiles to be reliable among others. You can set the clock automatically from other systems by using either the rdate or the ntpdate command.
If you intend to run the Network Time Protocol to synchronize clocks continuously, use the ntpdate command from that package instead of rdate. It's more accurate and will start the clocks closer to each other, leaving less for xntpd to adjust.
Network Daemons
Most of the work done by the networking system is not handled by the UNIX operating system itself, but by programs that run automatically. These are called daemons. There are many helper programs used by the networking system, and understanding which
one does which functions will help you manage the system.
Three of the daemons can be considered the controllers. There's one for each of the communication service types: For sockets it's inetd, for RPC it's rpcbind, and for SAF it's listen.
The Master Daemon—inetd
inetd handles both TCP and UDP servers. For TCP inetd listens for connection requests on many ports at once. When it receives a connection request it starts the appropriate server and then goes back to listening. For UDP inetd listens for packets and
when they are received it starts the server. When the server exits it goes back to listening on the UDP port.
In this chapter, you have seen the control file for inetd, which is called /etc/inetd.conf. It consists of several fields separated by white space. The seventh field continues until the end of the line or the first # character. The fields are the
following:
- Service The name of the service as listed in the /etc/services file.
- Socket type stream or dgram. For TCP services it's almost always stream. For UDP services it has to be dgram.
- Protocol tcp and udp are the only two supported.
- Wait Tells whether inetd should wait until the server exists before listening again, or listen right away. Servers that once started listen for their own connections should use wait. Any service that must allow only one server at a time should
use wait. Most TCP services use nowait.
- User ID Tells what user ID inetd should use when starting the server. Only those services that need root access, such as telnetd to run login, should be started as root. All others should be started as nobody.
- Process to Run The file name to run.
- Command String The remainder of the line is passed in as the command string.
If the wait parameter is nowait, the connection is accepted and the socket is connected to standard input and output before the server is started. The server does not need to be aware that it is being run from the network.
The Remote Procedure Call Master Daemon—rpcbind
Another client/server system is the remote procedure call. This is used by network file system (NFS), NIS, and the lock manager daemon. It is also used by many application programs. The controlling daemon for RPC is rpcbind. It is started at boot time
by the system start-up scripts.
When RPC services are started they register themselves with rpcbind. Then when a call comes in it is dispatched by rpcbind to the appropriate server. No user configuration is necessary.
The Service Access Facility Master Daemon—listen
System V Release 4 introduced the Service Access Facility (SAF) to networking and added the listen process. SAF has its own configuration mechanism, which uses the port monitor facility. It is used by the System V line printer daemon. Most network
services use Berkeley's inetd instead of saf.
listen requires no direct configuration. It is managed automatically by the port monitor system, pmadm. To list which services are currently using listen use pmadm -l. Most SAF facilities are managed via sysadm.
Other Daemons That Can Be Started at Boot Time
Typically servers that run continuously and listen for messages are started at boot time and are not run from inetd. Most servers are not started until needed and do run from inetd.
routed
TCP/IP has a protocol called Router Interchange Protocol, or RIP. routed listens for RIP packets on the network interfaces, and when it hears them adds the routes they contain to the current routing tables. It also expires routes it has not heard for a
while. This allows the system to adapt dynamically.
If a system is itself connected to more than one network, routed will by default broadcast on each network on which routes are available on the other networks of this system. If another node is supposed to act as a router and this node is not, routed
can be started in -q, or quiet mode. Then it will only listen and not broadcast any routes.
gated
For external network gateways, a multi—protocol-routing daemon, gated, is available. It handles RIP, External Gateway Protocol (EGP) , Boundary Gateway Protocol (BGP), and HELLO. Unless you are the external gateway of a large network you will not
need gated.
gated reports only changes. Therefore, it will not periodically bring up the link. See the documentation on gated for how to configure it. There is a good note on configuring gated for use with PPP links in the dp-2.3 installation tips. dp-2.3 is a USENET-contributed PPP protocol package.
syslogd
UNIX includes a very flexible message logger called syslog. The server daemon, syslogd, listens for messages and when it receives them it forwards them to other processes, files, and devices via the specifications in the /etc/syslog.conf file. Messages
are classified as to who generated them and at what severity they were generated. Logging includes the time the message was generated, which host it came from, and the facility (who) and level (severity) at which it was issued.
Logging options include writing the message to a file or to a device (such as the console), starting a program and feeding it the message, or mailing the message. Zero or more actions are possible on any message. If a message matches no criteria in the
configuration file it is silently discarded.
To reread the configuration file once syslogd is started, send it the HUP (-1) signal with the kill command.
NFS
UNIX shares disk via NFS. NFS is an extension to the UNIX virtual file system and becomes just another file system type. NFS is split into four server daemons.
nfsd
This daemon listens for requests for I/O operations on NFS files by the operating system. It then contacts remote systems to read or write data blocks, set or read status information, or delete files. A system generally runs many nfsd daemons at the
same time. This allows for transactions to occur in parallel. Small systems generally run 4 nfsd daemons. Large servers can run 32 or more.
biod
The other end of a server to the nfsd client is a biod daemon. This listens to requests by nfsd daemons from remote systems and performs the local I/O required. Multiple biod daemons are normally run to allow multiple requests to be served in parallel.
lockd
Remote and local file locking is handled via the locking daemon. A single copy of lockd is run and it keeps track of all lock requests. These are advisory locks. No configuration of lockd is required.
statd
statd works with lockd to handle fault recovery for systems that have locks outstanding and then are no longer reachable due to network problems or having crashed. A single statd is also run.
This message, and check, can be suppressed by removing the files in /etc/.sm.bak for that system and then rebooting the system that is complaining.
NIS
The Network Information Service (NIS), or as it used to be called, Yellow Pages, provides a networkwide directory lookup service for many of the system configuration files. It is described in more detail later in this chapter.
sendmail
UNIX exchanges electronic mail between networked systems via the Simple Mail Transport Protocol (SMTP). SMTP is a TCP service that is provided by the Mail Transport Agent (MTA). The most common network MTA is sendmail. sendmail handles listening for
SMTP connections, processing the mail received, rewriting headers for further delivery, and handing off the message for final delivery.
sendmail uses a very complicated file, sendmail.cf, for configuration. Describing this file is beyond the scope of this chapter.
xntpd
Synchronizing the clocks across the network is very important. Tools such as make depend on it. However, clocks in computers drift. You can place calls to rdate in your cron scripts to force all systems to reset their clocks periodically to a single
system, but this jumps the clock and the clock might still drift.
Therefore, the Network Time Protocol was developed. This server checks with several other servers and determines not only the correct time, but how far off the current system is. It then uses a feature of the operating system to redefine how many
microseconds to add to the current time on each clock tick. It adjusts the length of a second, causing the system to slew its idea of the correct time slowly back to the correct time. It does this continuously, adapting to the changes in the system clock.
xntpd can keep a system to within several milliseconds of all other systems on the network.
In addition, xtnpd has the ability to synchronize to an external clock source. Using a radio clock tuned to a government time service, your network can be kept within milliseconds of the correct time.
xntpd is configured via the /etc/ntp.conf file, as shown in the following code:
server clock.big-stateu.edu version 2 server ntp-2.cs.university.edu server fuzz.network.net # requestkey 65535 controlkey 65534 keys /etc/ntp.keys authdelay 0.000017 # driftfile /etc/ntp.drift
The server lines list which servers this system will sync to. Your master systems should list external reference systems. The remainder of the systems should list your own master systems.
Daemons Started from inetd
Most servers are started from inetd. These servers transparently provide the network services to which UNIX users have grown accustomed.
ftpd
The file transfer protocol daemon is used to transfer files between any two systems, not just trusted ones.
The wuarchive ftp daemon is available via ftp from wuarchive.wustl.edu.
telnetd
The terminal sessions daemon is used to provide the basic remote login service. Telnet is a commonly used utility on many UNIX systems and now on non-UNIX systems.
shell
This is the server daemon for the Berkeley rsh command. rsh stands for remote shell and is used to execute a command on another system.
login
This is the server daemon for the Berkeley rlogin command. rlogin stands for remote login and is used to log in to a remote system. The caution for the shell service applies equally to this service.
exec
This is the server daemon for the rexec C subroutine. rexec stand for remote execute and is used to execute processes on a remote system. The caution for the shell service applies to this service as well.
comsat
The mail notification server daemon listens for incoming notifications of mail reception and informs processes that request it. It is used by the biff program.
talk, ntalk
talk and its newer cousin, ntalk (often just called talk), provide a keystroke-by-keystroke chat facility between two users anywhere on the network.
uucpd
The uupcd daemon transfers UUCP packets over the network. UUCP is used to transfer files from one UNIX system to another. See Chapter 43, "UUCP Administration," for more details on UUCP.
tftp
The Trivial File Transfer Protocol daemon is used for booting diskless systems and by some X terminals. See Chapter 33, "UNIX Installation Basics," and Chapter 40, "Device Administration," for more details. Again, the caution for the
shell service applies to this service.
finger
The finger daemon determines what a user is currently doing.
systat
The systat daemon performs a process status on a remote system. inetd forks off a ps command and returns the output to the remote system.
netstat
inetd forks off a netstat command and returns the output to the remote system.
time
Return the current system time in internal format. This service is provided internally by inetd as both a UDP and a TCP service. It returns a time-t consisting of the current system time. This is expressed as the number of seconds since the epoch,
January 1, 1970, at 0:00 GMT.
daytime
This is a human-readable equivalent of time. It is also internally provided both as a TCP and a UDP service and returns the time in the format Day Mmm dd hh:mm:ss yyyy.
echo
echo replies back what it receives. This service is provided internally by inetd as both a UDP and a TCP service. It returns whatever is sent to it. The UDP port echoes the packet back to the sender. The TCP service is line-oriented and echoes lines of
text back to the sender.
discard
This service is provided internally by inetd as both a UDP and a TCP service. It discards whatever it receives.
chargen
The character generator service is provided internally by inetd as both a UDP and a TCP service. On UDP it returns one copy of the printable characters of the ASCII character set. As a TCP service it repeats this, 72 characters per line, starting one
character later in the sequence on each line.
RPC Services Started from inetd
The following are RPC servers that are registered via inetd and are started when inetd receives a connection from rpcbind.
admind
This is the distributed system administration tool server daemon.
rquotad
This is the disk quota server daemon, which returns the disk quota for a specific user.
rusersd
This daemon returns a list of users on the host.
sprayd
This daemon sprays packets on a network to test for loss.
walld
This daemon will write a message to all users on a system.
rstatd
This daemon returns performance statistics about this system.
cmsd
This is the calendar manager server daemon.
ttdbserverd
This is the tool talk server daemon.
Sharing Files and Directories—NFS
One of the advantages of UNIX is how seamlessly the network is built in to everything else. This extends to the file system as well. Any part of the file system hierarchy can exist on any computer in the network. That computer doesn't even have to be
running UNIX. This is accomplished with the network file system, which is a very simple extension to the file system that transparently extends your disk over the network.
NFS is so effective that a fast disk on a server can be accessed faster than a medium-speed local disk on a workstation. This is partly due to caching effects of having many systems access the server, but it does show that using NFS is not necessarily
going to slow down your system.
How NFS Works
UNIX supports many file system types. The kernel accesses files via the virtual file system (VFS). This makes every file system type appear the same to the operating system. One VFS type is the network file system. When the kernel I/O routines access an
inode that is on a file system of the type NFS and the data is not in the memory cache of the system, the request is shunted to the next available nfsd task (or thread).
When the nfsd task receives the request it figures out on which system the partition resides and forwards the request to a biod (or nfsd thread) on the remote system using UDP. That system accesses the file using the normal I/O procedures just as in any
other process and returns the requested information via UDP. Since the biod just uses the normal I/O procedures the data will be cached in the RAM of the server for use by other local or biod tasks. If the block was recently accessed, the I/O request will
be satisfied out of the cache and no disk activity will be needed.
NFS uses UDP to allow multiple transactions to occur in parallel. But with UDP the requests are unverified. nfsd has a time-out mechanism to make sure it gets the data it asks for. When it cannot retrieve the data within its time-outs, it reports via a
logging message that it is waiting for the server to respond.
To increase performance the client systems add to their local file system caches disk blocks read via NFS. They also cache attribute lookups (inodes). However, to ensure that the disk writes complete correctly, NFS does those synchronously. This means
that the process doing the writing is blocked until the remote system acknowledges that the disk write is complete. It is possible to change this to asynchronous writes, where the disk write is acknowledged back to the process immediately and then the
write occurs later. The problem occurs when the write fails due either to the server being unreachable or a disk error. The local process was already told that the write succeeded and can no longer handle the error status. Although using asynchronous
writes is faster, it can lead to data corruption.
Exporting Hierarchies
Each server—and any system that exports its local disk via NFS is a server—must grant its permission to allow remote systems to access its disks. It does this by exporting part of its file system hierarchy. When you enable a system to access
your disks you provide a list of points in your file system hierarchy where you will allow access to that point and all places below that point. You cannot allow only single directories or files-only sections of the hierarchy at and below the export point.
Export points are listed in a file, and a command is run on that file to make the NFS aware of the list. BSD-derived UNIX systems and SVR4 use different mechanisms for this file.
/etc/exports—BSD-Derived UNIX Systems
The original NFS, as developed on BSD UNIX systems, used the exports file to hold the list of exportable points. This file is processed by the exportfs command to make NFS aware of the list. A sample exports file contains:
/files1 -access=ws1:ws2:gateway /files2 -access=ws1:ws2 /export /usr /cdrom -ro
Each line consists of a pathname for the export point and a list of export options. The list of options is not required.
When root runs the exportfs command with the -a argument, it will read the exports file and process it. The exportfs command can also be used by any user to print the current export list and by root to unexport a specific file system.
/etc/dfs/dfstab—SVR4
To allow for more than just NFS sharing, SVR4 extended the concept of an exports file and created the distributed file system directory. In this directory the file dfstab lists the shell commands to export any shared file systems, regardless of the
method of sharing. The share exports as a dfstab file is:
# place share(1M) commands here for automatic execution # on entering init state 3. # # share [-F fstype] [ -o options] [-d "<text>"] <pathname> [resource] # .e.g, # share -F nfs -o rw=engineering -d "home dirs" /export/home2 share -F nfs -o rw=ws1,root=ws2 -d "home dirs" /files share -F nfs -o r0=ws1:ws2 -d "frame 4" /opt/Xframe4 share -F nfs -o ro -d "cdrom drive" /cdrom
The share command is very similar to the export lines. It adds two options. The first is the -F nfs option to specify that this is an NFS export. The second is the -d option to specify a descriptive text string about this export. The remainder of the
options are the same as those possible in the exports file.
Export Options
There are many options to control the access allowed by remote systems. Most of the options reduce the access rights allowed.
rw[=client[:client]_]
The list of client hosts will be allowed read-write access to the hierarchy. If no hostnames are listed, any host can access the files read-write. If the ro option is given with no hostnames forcing read-only export, the hosts listed on the rw list are
considered exceptions to the ro list and are allowed read-write access.
ro[=client[:client]_]
The list of client hosts will be allowed read-only access to the hierarchy. If no hostnames are listed, any host can access the files read-only. If the rw option is given with no hostnames, forcing read-write export, the hosts listed on the ro list are
considered exceptions to the ro list and are allowed only read-only access.
anon=uid
Some systems cannot authenticate their users. Map any unauthenticated users to this user ID, which is normally set to nobody. Setting it to -1 (or 65535 on BSD) will deny access to unauthenticated users.
root=host[:host]_
Normally the root user ID from remote hosts is mapped to nobody. This option overrides this mapping and allows remote root users to have root access to this hierarchy.
secure
You should use a secure authentication scheme to authenticate users. Any unauthenticated requests are mapped as per the anon option previously described. Not all NFSs support this feature.
kerberos (SVR4 only)
Use kerberos instead of DES as the secure authentication method.
Export Security
Because your files are the key to your system you need to exercise some caution in exporting. The following are some simple rules:
- Avoid blanket read-write exports. List the valid systems for the export. Use netgroups if a large list of systems is being exported.
- Be very restrictive in providing root access.
- Block access from public networks to port 111, the RPC port, and port 2049, the NFS port, to prevent spoofed mount requests from systems outside your network. Use the port filtering ability of routers to block this access.
Mounting Remote Hierarchies
Accessing remote disks is a two-step process. The remote system must export it and the local system must mount it. An NFS mount is like any other mount in that it grafts a new file system onto the mount point in the hierarchy. However, NFS is also
different. Not only is the disk remote but any place in the export hierarchy can be mounted, not just the export point itself. This allows for small sections of the export tree, such as a single home directory, to be mounted.
Mounting is accomplished via the mount command, using the remote system name and export path as the disk device and the local mount point, as in the following:
mount server:/files/home/syd /home/syd mount -F nfs server:/files/home/syd /home/syd
The first line is for BSD systems and the second is for SVR4 and includes the file system type. In addition, NFS mounts support many options. These are specified with the -o argument before the server name.
If the entry is listed in /etc/fstab (/etc/vfstab on SVR4), the mount command needs to specify only the mount point. It will read the remainder of the data directly from the file.
NFS Mount Options
NFS mounts are tuned via the mount options. These options not only control mount time behavior but also access behavior. Options are separated by commas.
rw
Mount the file system for read-write access. This is the default mount method if no other option overrides it. Must be exported as read-write to succeed.
ro
Mount the file system read-only. You can mount a read-write exported file system as read only.
suid, nosuid
Honor or ignore the setuid bit. The default is setuid.
Since you have no control over which files are created on a remote file system, if you cannot trust the system you can instruct NFS to ignore the setuid bit on executable files.
remount
Change the mount options on an existing mount point.
fg, bg
Retry mount failures in the foreground or background. The default is fg.
If the first mount attempt fails because it could not reach, the server mount will retry the mount for retry times. With the default fg option the mount process will block until the mount succeeds. If you are mounting a partition at boot time
this will cause your boot to freeze until the partition can be mounted. Using bg will allow the mount to return. The file system is not mounted, but retry attempts occur in the background.
retry=n
This refers to the number of times to retry the mount operation. The default is 10000.
port=n
This is the server IP port number. The default is NFS_PORT, which is 2049.
rsize=n
Set the read buffer size to n bytes. The default is 8192.
If you are using older PCs on the network that cannot keep up with 8 KB worth of data in back-to-back packets, use this option to reduce the read size to a size they can handle. This will reduce performance slightly compared to if they could handle the
large rsize.
wsize=n
Set the write buffer size to n bytes.
timeo=n
Set the NFS time-out to n tenths of a second. This is the time the nfsd daemons wait for a response before retrying. On a local EtherNet the default value will be sufficient.
As an example, using V.32bis modems with V.42bis compression you can expect to achieve about 2000 bytes per second on normal files and a bit more on ascii ones. Using the 2000 byte speed, transferring 8 KB takes 4 seconds. Using a time-out of less than 4 seconds will cause re-requests and will further slow down the link.
retrans=n
Set the number of NFS retransmissions to n. If the request takes a time-out, it is retried n number of times. Each time it is retried the time-out is multiplied by 2. If after the number of retransmissions is exceeded it still fails, an
error is returned for soft mounts or a message is logged, indicating that the server is unreachable and the retries continue for hard mounts.
hard, soft
Retry an operation until the server responds or returns an error if the server takes more time-outs than retrans times. The default is hard.
All partitions mounted rw should be mounted hard to prevent corruption. This will hang processes waiting for response if the server becomes unreachable.
intr, nointr
This allows (or prevents) SIGINT to kill a process that is hung while waiting for a response on a hard-mounted file system. The default is intr.
secure
Use DES authentication for NFS transactions.
kerberos
Use kerberos authentication for NFS transactions.
noac
Suppress attribute caching.
acregmin=n
Hold cached attributes for at least n seconds after file modification. This option is useful for slow links to reduce the number of lookups, but is normally not tuned by system administrators.
acregmax=n
Hold cached attributes for no more than n seconds after file modification. On fast-changing file systems this will increase the responsiveness to updates made by other systems. If you have a file system that you are mounting on multiple clients
which frequently updates the same files from each of those clients, you might want to shorten this interval. The default is fine for most usage.
acdirmin=n
Hold cached attributes for at least n seconds after directory update. This option is useful for slow links to reduce the number of lookups, but is normally not tuned by system administrators.
acdirmax=n
Hold cached attributes for no more than n seconds after directory update. See the note under the explanation of acregmax.
actimeo=n
Set min and max times for regular files and directories to n seconds. This is a combined option that sets all four of the prior options to the same value.
Using the Cache File System
One of the newer concepts in NFS is the cache file system. On heavily loaded networks using the cache file system can reduce delays by substituting local disk space for network accesses. It also can be used to substitute a fast disk for slow CD-ROM.
It works by using part of or all of a local file system to cache recently used files. It caches both read and writes (optionally it can write directly back and cache only reads) and automatically handles refreshing the cache when the backing store file
is changed.
It is really simple to set up. You first create the cache and then mount the file system as type cachefs. One cache can handle multiple back end file systems.
Setting Up the Cache
If you want to let the cache take over an entire file system, then the default parameters of
cfsadmin -c /pathname
will create a cache on the file system at pathname. This will allow the cache to grow to the full size of the file system.
If you want the cache to be limited in size to a percentage of the file system you can use the maxblocks and maxfiles options to specify what percentage of the file system is allowed to be used by the cache.
Mounting as a cachefs File System
When the cache has been initialized there are two options for mounting it. In the first, when no special NFS mount options are used, the -F nfs in the mount command is replaced by two options: -F cachefs and -o backtype=nfs,cachedir=/pathname, as
in the following:
mount -F cachefs -o backtype=nfs,cachedir=/local/cache1 gateway:/sharedfiles /sharedfiles
Options to specify write-around and nonshared gateless options, suid/nosuid cache consistency-checking intervals, and suppressing the checking for changes (when used for read only file systems) are also available. See the chapter on the cache file
system in the Administering File Systems manual.
Backing Up on a Network
One advantage of a network is that you can share resources. One expensive resource that is easy to share is a high-speed tape drive such as DAT or 8mm. With all the disk in a network, something with a jukebox or autochanger is also handy. But it's
useless unless you can back up the systems over the network. There are commercial products that can make all of this point-and-shoot from the GUI, but the standard UNIX tools can also handle the backups.
There are three sets of utilities that can be used to perform backups:
- dump/restore
- tar
- cpio
Chapter 35, "File System Administration," presents the merits and drawbacks of each of these utilities. dump/restore, tar, and cpio are covered in more detail in Chapter 32, "Backing Up."
dump/restore has a direct network counterpart, rdump/rrestore. The others require using a connection via the rsh command to a program to access the drive on the server.
Using rdump/rrestore
Under the older BSD operating systems, using the command rdump instead of dump enabled you to specify the device name for the dump as hostname:device. The dump would then be pushed from the system running rdump onto the device at
hostname. This requires that the remote system have the dumping system in its .rhosts file for the operator or whatever user was doing the dump. Restores are performed using rrestore. Again, the device is referred to as hostname:device.
SVR4's ufsdump directly supports using the remote system and hostname:device so no special command is needed. Likewise, ufsrestore supports remote access.
Using tar over a Network
To use tar over the network you need to simulate the process that dump uses internally. You need to have it write to standard output and redirect that output across the network to a process that will read standard input and write it to the tape drive.
Unfortunately, doing so will preclude handling tape changes. The simplest way is to combine tar and dd, as in the following:
tar vcf pathname | rsh remote dd of=/dev/rst1
Alternatively, you can use this:
rsh client tar vcf - pathname | dd of=/dev/rst1
The first example uses a push to create the backup from the client to the remote system with the tape drive. The second is a pull to run the backup from the client remotely to the local system with the tape drive.
Using cpio over a Network
cpio can just as easily be used as tar, with the same method. Again, redirecting the output across the network is performed by the rsh command as in the following:
find / -print | cpio -oacv | rsh remote dd of=/dev/rst1
Alternatively, you can use this:
rsh client "find / -print | cpio -oacv" | dd of=/dev/rst1
Again, the first example uses a push to create the backup from the remote to the server. The second is a pull backup from the client to the system with the tape drive.
Introduction to NIS
NIS provides a networkwide management of the UNIX configuration and system administration files. It also can be used to manage any local administrative files. This section introduces you to NIS, showing what it does and a little of how it works.
What Is NIS?
Without NIS each UNIX process that needs access to the passwd, hosts, group, or other UNIX system administration files must open a local file on the host on which it is executing and read the information. This is performed via a standard set of C
library calls, but the system administrator must replicate this configuration information on every host in the network.
NIS replaces these local files with a central database containing the same information. Instead of making the changes on every host, you make the changes in one place and then let NIS make the data available to everyone.
NIS works by assigning hosts to domains via the domainname call. All hosts in the same domain share a common set of database files called maps. Within a domain one host is designated as the NIS master server. This host holds the configuration
files (passwd, group, hosts) that are used to build the maps. In addition to a master server there can be one or more slave servers. These servers get their updates from the master server. This pool of servers will answer NIS lookup requests for the all of
the systems in the domain.
When an NIS system starts up, it starts the NIS lookup daemon, ypbind. This daemon broadcasts a request asking who is a server for its domain. All the servers respond, and the first server it hears becomes the server for this NIS client. If a server is
heavily loaded, it will take a while to respond and a server that is less loaded usually will respond faster. This helps balance the NIS load. You can check which server is serving this client with the ypwhich command.
It is even common for the master server to bind to one of the slave servers as its NIS client. The master still controls the distribution of maps to each of the servers. It is only the lookup routines that will access the slave server.
You can determine who is the master with the ypwhich -m command.
If your NIS server becomes unreachable, the NIS system will take a time-out after about 90 seconds and then rebroadcast, asking for another server. If it finds one it continues as if nothing except the delay has happened. If it cannot find one, it will
freeze that process until it can find a server. Of course, as more processes need lookup services, those will also be frozen. The overall effect is for the entire system to appear to lock up.
The NIS Components
NIS provides a set of components that make up the NIS management. These include database administration, distribution, and lookup utilities, plus a number of daemons.
Database Administration Utilities
These build the database and receive update requests to some of the database files from remote processes. These utilities are located in the /usr/etc/yp directory and include the following:
- makedbm Converts the flat files into dbm database files
- mkalias Builds the sendmail aliases
- mknetid Builds the information used by the RPC system
- revnetgroup Builds the user-to-netgroup—mapping file
- stdethers Builds the ethers-to-name—mapping file
- stdhosts Builds the IP address-to-name—mapping file
- ypinit Creates a new NIS domain
Each of these is used in /var/yp/Makefile, which controls the build.
NIS Daemons
NIS daemons provide the lookup service at runtime. This includes:
- ypserv An NIS server—can be either a slave or a master server
- ypxfrd Handles transferring updated maps to the slave servers on request from the slaves
- rpc.yppasswdd Handles remote requests by users to change their own passwords
- ypbind An NIS database lookup daemon, run by both clients and servers
- rpc.ypupdated Runs on the master server to update the slave servers when the database is updated
Database Distribution Utilities
Database distribution utilities will cause the database to be updated or transferred on request. These include:
- yppoll Requests an update of a slave server from another server
- yppush Pushes the maps from the master to its slave servers
- ypset Forces a particular host to be the server for this host's ypbind
- ypxfr Transfers (copies) an individual map from one server to another
Database Lookup Utilities
Database lookup utilities are replacements for the C runtime library routines that automatically use the NIS database lookup methods instead of accessing the flat files. Some of the utilities access the flat files first and then when they hit a line
with a + in the first character, they switch to using the NIS database. This allows for overriding the NIS information on a single host by placing the override information before the line with the + in the appropriate file. The passwd and group files are
examples of files whose lookup routines use this method.
DB Files
The NIS database files reside in the directory /var/yp/'domainname' on every server. On the master server there is also a set of files that control the rebuilding of the database in the /var/yp directory, including a Makefile. Each of the files
is a DBM database that makes the lookups very efficient.
You rebuild the database by becoming root on the master server, changing to the /var/yp directory, and entering make.
To avoid having to change directories just enter make, build a shell script, which I like to call ypmake, and place it in the /etc directory with execute permission. Have it do the cd and make calls. Mine reads as follows:
#!/bin/sh # Rebuild the YP Database cd /var/yp make
This will allow you to stay in the same directory where the configuration file resides and still rebuild the database.
What Files Does NIS Control?
Each NIS installation controls all the maps found in the /var/yp/'domainname' directory. The default configuration includes the following:
- passwd Account and password information
- group UNIX group table
- hosts IP addresses
- ethers EtherNet-to-hostname mapping
- networks IP network number-to-name mapping
- rpc A bound RPC program
- services IP port names
- protocols IP protocol names
- netgroup User-to-netgroup mappings
- bootparams bootp parameters for each host
- aliases MTA (sendmail) aliases
- publickey RPC publickey security database
- netid The version number of the NIS maps (This is used by the servers to be sure they have the latest maps.)
- netmasks IP network number-to-netmask override file
- c2secure An optional C2 security database
- timezone Time zone name-to-time conversions
- auto.master Automounter configuration information
- auto.home Automounter indirect map for home directories
To add new maps you need to perform three steps:
- Modify the Makefile to add the commands to build the map.
- Build the map on the master server with the -DNOPUSH option.
- On each slave use ypxfr to request the map for the first time from the master.
From that point on the new map will be transferred automatically.
Automounting File Systems
Having NFS mounts always mounted has led to some problems. Since most NFS mounts are hard mounts when the server is unreachable it can cause client systems to freeze waiting for the server to become available again. Furthermore, every time you move
files around and change the layout, every fstab on every client needs to be redone. There is an easier way to handle both problems. Let UNIX automatically mount any needed directory.
The automounter also lets you specify multiple servers for a mount point. This allows the closest server handle the request. Of course this is most useful for read-only file systems, but many shared file systems via NFS fit this category (bin
directories, libraries, and so on). Then when the closest server is not available, a backup server is used automatically.
NFS includes a special daemon called automount. This daemon intercepts NFS requests for file systems that aren't mounted, sidesteps them for a moment, and requests that they be mounted, and then resubmits the request after the file system is mounted. It
then mounts the file system after there is no activity for a period of time.
The automount daemon mounts the file system in /tmp_mnt and creates a symbolic link to the desired access directory. When the directory is unmounted the daemon removes the link.
An additional feature of the automounter is that it can perform variable substitution on the mount commands, allowing different directories to be mounted in differing circumstances, while referencing the same path. As an example, if the path
/usr/local/bin were referenced, the actual mounted file system count be /usr/local/bin.'arch', where arch is replaced by the output of the arch command. This would allow different directories to be automatically mounted for different
architecture computers.
The Automounter Configuration File—/etc/auto.master
The automount daemon uses a map file to control its operations. This file can be distributed by NIS or it can be on a local file. The normal local configuration file is /etc/auto.master. However, this file often refers to other files, which allows for
segmenting the configuration.
Although there are many options available via the automounter, a simple auto.master looks like:
#Mount-point Map Mount-options /- /etc/auto.direct -ro,intr /home/users /etc/auto.home -rw,intr,secure
There are three columns. The first is the mount point to listen for. Any requests for files under /home/users, in this example, are managed by the automounter via the map /etc/auto.home. The mount commands generated will be performed with the options
listed in the third column.
The /- line specifies a direct map. Entries in this map file specify the full pathname of the mount point and are not relative to the mount point listed. Each entry in a direct map is a separate mount.
Indirect Map Files
The map file /etc/auto.home is considered an indirect map file because it is relative to /home/users. A sample auto.home includes:
#key mount-options location syd server:/home/server/syd
This specifies that the directory syd under /home/users should be mounted from the server's /home/server/syd directory. Any specific mount options to add to the options in the master map file can be listed between the key and the location.
Analyzing and Troubleshooting Utilities
Like in all aspects of a computer system, things can go wrong on the network. However, the network can be a bit harder to troubleshoot than other aspects because things happen across multiple computers. But there is a basic set of questions you can
start with:
- Is the network configured properly? Using ifconfig you can check to see if the interfaces are configured and up.
- Are the routes configured properly? Using netstat you can check routing.
- Can I talk to the other nodes? Using ping and traceroute you can verify connectivity.
- Is the process listening? Using netstat you can check the connections.
- Am I sending the right data and is it responding? Using etherfind or snoop you can listen in to the network and see what is being sent.
ifconfig
You configure and report on the configuration of the interfaces using ifconfig. It can set the IP address, netmask, broadcast address, MTU, a routing metric, and whether the interface is up and should be used or down and should be ignored. It also
reports on the current configuration of the interface and its EtherNet address. Running ifconfig-a from the shell yields:
# ifconfig -a
lo0: flags=849<UP,LOOPBACK,RUNNING,MULTICAST> mtu 8232
inet 127.0.0.1 netmask ff000000
le0: flags=863<UP,BROADCAST,NOTRAILERS,RUNNING,MULTICAST> mtu 1500
inet 190.109.252.34 netmask ffffffe0 broadcast 192.65.202.224
ether 8:0:20:1d:4e:1b
#
flags is a bitmask, and the meaning of each bit is explained in the words following the flag value. The important one is UP or DOWN. The interface should always be RUNNING. It's with the second line for each interface that you are most concerned. The
inet (IP) address should be correct for this interface for this host. The netmask must match, and the broadcast address should be all 1s in all the 0 bits of the netmask and it should match the IP address in the 1 bits.
A common mistake in initializing an interface is to get the order of the arguments to ifconfig incorrect. ifconfig processes its arguments left to right, and this matters if a + is used.
ifconfig can automatically determine the default netmask and broadcast address, but it does it for the current values at the time it sees the +. This leads to a different result, depending on the order of the arguments. As an example, the ifconfig
command
ifconfig le0 190.109.252.34 broadcast + netmask + up
would set the IP address correctly, the broadcast address to the default for 190.109, which is 190.109.255.255, and the netmask, using an override in the /etc/netmasks file, to 255.255.255.0. This is not what you wanted. Even specifying
ifconfig le0 190.109.252.34 broadcast + netmask 255.255.255.224 up
won't do what you want because the broadcast address will be controlled by the default netmask value. It is important that the order be
ifconfig le0 190.109.252.34 netmask 255.255.255.224 broadcast + up
netstat
The main reporting command for the network is netstat. The interface report will show you if the network is being used and if there are too many collisions. The route report will show you not only if the route is configured but also if it is being used.
The connection report will show what is using the network, and the various statistics show how much is being used.
netstat -i—Interfaces
The following is the interface status report:
# netstat -i Name Mtu Net/Dest Address Ipkts Ierrs Opkts Oerrs Collis Queue lo0 8232 loopback localhost 527854 0 527854 0 0 0 le0 1500 subnet1 ws1 965484 1 979543 1 6672 0 #
This report can be run showing the cumulative counts since boot, or with a repeat interval in seconds on the end of the command, which will show the delta in the counts every interval seconds.
When troubleshooting you are looking for three things in the output of netstat:
- The input and output counts are incrementing. This shows that the network is being accessed.
- The error counts are not incrementing. This shows that there is not likely to be a hardware error in wiring or the equipment.
- The collision count is staying small relative to the packet counts. No single node is hogging the network and the network is not overloaded. If the collisions are more than 1 to 2 percent of the delta in packet counts, you should be concerned.
netstat -r—Routes
The route is listed with netstat -r as in:
# netstat -r Routing Table: Destination Gateway Flags Ref Use Interface —————————— —————————— —— —— ——— ———— localhost localhost UH 0 109761 lo0 rmtnet ws2 UG 0 20086 rmtppp ws2 UG 0 1096 subnet1 ws1 U 3 1955 le0 224.0.0.0 ws1 U 3 0 le0 default gateway UG 0 16100 #
In the routing table you are looking for the existence of the proper routes and their flags. In addition, you should run the command more than once while traffic is supposed to be flowing to the sites you are looking at to see that the use count is
incrementing.
The flags show the status and how the route was created:
- U (up) The route is up and available.
- G (gateway) This route is not to a final destination, but to a host that will forward it. The gateway field should contain the address (name) of the next hop. If there is no G flag, the Gateway field should show your address (name).
- D (redirect) This route was created by a redirect. This is a cautionary note. Your routes were not correct and the TCP/IP code received an ICMP redirect message with the proper route. Things will work, but eventually you should fix your
configuration files with the proper route.
- H (host) Internal to the host. This should appear only on the loopback interface.
netstat -a—Connections
There are two formats of the connection list output. The first is from BSD and SVR4 UNIX's and the second is from Solaris 2. On BSD or SVR4, running the netstart connection report shows:
# netstat -a -f inet (BSD, SVR4) Active Internet connections Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp 0 0 gateway.smtp cunyvm.cuny.edu.60634 SYN_RCVD tcp 0 14336 gateway.1314 qms860.qmspr ESTABLISHED tcp 0 0 gateway.1313 qms860.qmspr TIME_WAIT tcp 0 0 gateway.1312 qms860.qmspr TIME_WAIT tcp 0 0 gateway.1295 NETNEWS.UPENN.ED.nntp ESTABLISHED tcp 0 0 gateway.nntp NETNEWS.UPENN.ED.2930 ESTABLISHED tcp 0 0 gateway.1242 eerie.acsu.buffa.nntp ESTABLISHED tcp 0 0 gateway.login dsiss2.1020 ESTABLISHED tcp 0 0 gateway.telnet xterm.1206 ESTABLISHED tcp 0 0 gateway.telnet xterm.1205 ESTABLISHED tcp 0 0 gateway.login photo.1022 ESTABLISHED tcp 0 80 gateway.login photo.1023 ESTABLISHED tcp 0 0 gateway.printer *.* LISTEN tcp 0 0 gateway.listen *.* LISTEN udp 0 0 gateway.nameserv *.* udp 0 0 localhost.nameserv *.* #
Under Solaris 2, running the netstat connection report shows:
# netstat -a -f inet (Solaris)
UDP
Local Address State
—————————— ———
*.sunrpc Idle
*.* Unbound
*.talk Idle
*.time Idle
*.echo Idle
*.discard Idle
*.daytime Idle
*.chargen Idle
ws1.syslog Idle
*.ntalk Idle
*.ntp Idle
localhost.ntp Idle
ws1.ntp Idle
*.nfsd Idle
TCP
Local Address Remote Address Swind Send-Q Rwind Recv-Q State
—————————— —————————— —— ——— —— ——— ———
*.* *.* 0 0 8576 0 IDLE
*.sunrpc *.* 0 0 8576 0 LISTEN
*.ftp *.* 0 0 8576 0 LISTEN
*.telnet *.* 0 0 8576 0 LISTEN
*.shell *.* 0 0 8576 0 LISTEN
*.login *.* 0 0 8576 0 LISTEN
*.systat *.* 0 0 8576 0 LISTEN
*.netstat *.* 0 0 8576 0 LISTEN
*.time *.* 0 0 8576 0 LISTEN
*.echo *.* 0 0 8576 0 LISTEN
*.discard *.* 0 0 8576 0 LISTEN
*.daytime *.* 0 0 8576 0 LISTEN
*.chargen *.* 0 0 8576 0 LISTEN
*.chalklog *.* 0 0 8576 0 LISTEN
*.lockd *.* 0 0 8576 0 BOUND
ws1.1019 gateway.login 4096 0 9216 0 FIN_WAIT_2
ws1.1023 gateway.login 4096 0 9216 0 ESTABLISHED
*.6000 *.* 0 0 8576 0 LISTEN
*.* *.* 0 0 8576 0 IDLE
ws1.34125 xterm.6000 8192 0 10164 0 ESTABLISHED
ws1.1018 pppgate.login 4096 0 9112 0 ESTABLISHED
*.ident *.* 0 0 8576 0 LISTEN
*.smtp *.* 0 0 8576 0 LISTEN
ws1.1022 gateway.login 4096 0 9216 0 ESTABLISHED
*.printer *.* 0 0 8576 0 LISTEN
*.listen *.* 0 0 8576 0 LISTEN
localhost.32793 localhost.32787 16340 0 16384 0 FIN_WAIT_2
localhost.32787 localhost.32793 16384 0 16340 0 CLOSE_WAIT
#
These listings provide similar information. In troubleshooting you are looking for three things:
- A process should be listening or connected on that port. You want to see a *.port with a LISTEN status for daemons or a host.port for TCP connections.
- Send-Q shouldn't be staying stable at any value other than 0. You want the system and the remote process to be reading the data. Seeing a non-zero send queue entry indicates that data is waiting to be sent and the remote TCP code has not acknowledged
enough prior packets to allow the sending of more data. That in itself is not a problem—it happens all the time on sockets that are continuously sending data and is a method of flow control. What should raise your concern is seeing it stay stable at
the same number all the time.
- Recv-Q should have a non-zero value. This nonzero value means that your local task is not reading the data from the socket. Your local task might be hung.
In addition, the state of the connection if it's not ESTABLISHED or LISTEN is worth noting. If a connection stays in FIN_WAIT or FIN_WAIT2 for long periods of time, the remote end is not acknowledging the close window packet. Being in CLOSE_WAIT is not
a problem. CLOSE_WAIT is a time-out—based state that waits to be sure all data is drained by tasks from the socket before allowing the port address to be reused. Controlling the use of a CLOSE_WAIT state is handled by an option when opening the socket
in the C code of programs.
netstat -s—Statistics
The format of the statistic output varies by the vendors of the TCP/IP driver stack. However, it always contains similar data. Here is a sample output:
# netstat -s
UDP
udpInDatagrams =6035056 udpInErrors = 0
udpOutDatagrams =10353333
TCP tcpRtoAlgorithm = 4 tcpRtoMin = 200
tcpRtoMax = 60000 tcpMaxConn = -1
tcpActiveOpens = 1749 tcpPassiveOpens = 722
tcpAttemptFails = 96 tcpEstabResets = 1964
tcpCurrEstab = 27 tcpOutSegs =2442096
tcpOutDataSegs =1817357 tcpOutDataBytes =1688841836
tcpRetransSegs = 6986 tcpRetransBytes =904977
tcpOutAck =624749 tcpOutAckDelayed =563849
tcpOutUrg = 25 tcpOutWinUpdate = 133
tcpOutWinProbe = 31 tcpOutControl = 5282
tcpOutRsts = 423 tcpOutFastRetrans = 11
tcpInSegs =2064776
tcpInAckSegs =1522447 tcpInAckBytes =1688826786
tcpInDupAck = 6299 tcpInAckUnsent = 0
tcpInInorderSegs =856268 tcpInInorderBytes =280335873
tcpInUnorderSegs = 564 tcpInUnorderBytes =293287
tcpInDupSegs = 15 tcpInDupBytes = 2314
tcpInPartDupSegs = 5 tcpInPartDupBytes = 1572
tcpInPastWinSegs = 0 tcpInPastWinBytes = 0
tcpInWinProbe = 3 tcpInWinUpdate =532122
tcpInClosed = 121 tcpRttNoUpdate = 6162
tcpRttUpdate =1514447 tcpTimRetrans = 24065
tcpTimRetransDrop = 1 tcpTimKeepalive = 369
tcpTimKeepaliveProbe= 193 tcpTimKeepaliveDrop = 0
IP ipForwarding = 2 ipDefaultTTL = 255
ipInReceives =7873752 ipInHdrErrors = 0
ipInAddrErrors = 0 ipInCksumErrs = 12
ipForwDatagrams = 0 ipForwProhibits = 0
ipInUnknownProtos = 0 ipInDiscards = 0
ipInDelivers =8098783 ipOutRequests =11669260
ipOutDiscards = 0 ipOutNoRoutes = 0
ipReasmTimeout = 60 ipReasmReqds =137309
ipReasmOKs =137309 ipReasmFails = 0
ipReasmDuplicates = 0 ipReasmPartDups = 0
ipFragOKs =211618 ipFragFails = 0
ipFragCreates =1062582 ipRoutingDiscards = 0
tcpInErrs = 15 udpNoPorts =496673
udpInCksumErrs = 0 udpInOverflows = 0
rawipInOverflows = 0
ICMP icmpInMsgs = 8555 icmpInErrors = 0
icmpInCksumErrs = 0 icmpInUnknowns = 0
icmpInDestUnreachs = 8516 icmpInTimeExcds = 22
icmpInParmProbs = 0 icmpInSrcQuenchs = 0
icmpInRedirects = 0 icmpInBadRedirects = 0
icmpInEchos = 6 icmpInEchoReps = 0
icmpInTimestamps = 0 icmpInTimestampReps = 0
icmpInAddrMasks = 11 icmpInAddrMaskReps = 0
icmpInFragNeeded = 44 icmpOutMsgs = 492
icmpOutDrops = 5 icmpOutErrors = 0
icmpOutDestUnreachs = 486 icmpOutTimeExcds = 0
icmpOutParmProbs = 0 icmpOutSrcQuenchs = 0
icmpOutRedirects = 0 icmpOutEchos = 0
icmpOutEchoReps = 6 icmpOutTimestamps = 0
icmpOutTimestampReps= 0 icmpOutAddrMasks = 0
icmpOutAddrMaskReps = 0 icmpOutFragNeeded = 0
icmpInOverflows = 0
IGMP:
0 messages received
0 messages received with too few bytes
0 messages received with bad checksum
0 membership queries received
0 membership queries received with invalid field(s)
0 membership reports received
0 membership reports received with invalid field(s)
0 membership reports received for groups to which we belong
0 membership reports sent
#
Of particular interest are any error counts. A large number of errors can indicate a hardware or wiring problem. In addition, comparing two outputs over time gives an indication of the overall loading on the network.
Seeing redirects in the ICMP section is a sign of a routing problem. However, time exceededs are most likely just the result of someone running a traceroute command.
nfsstat
NFS keeps many statistics that aid in checking the overall performance of the NFS system and in troubleshooting problems. They are reported via the nfsstat command. The two most useful options are -n and -m, shown in the following:
# nfsstat -m /files3 from ws2:/files3 Flags: hard,intr,dynamic read size=8192, write size=8192, retrans = 5 Lookups: srtt=7 (17ms), dev=3 (15ms), cur=2 (40ms) Reads: srtt=15 (37ms), dev=3 (15ms), cur=3 (60ms) Writes: srtt=28 (70ms), dev=6 (30ms), cur=6 (120ms) All: srtt=12 (30ms), dev=3 (15ms), cur=3 (60ms) /files2 from ws2:/files2 Flags: hard,intr,dynamic read size=8192, write size=8192, retrans = 5 Lookups: srtt=11 (27ms), dev=4 (20ms), cur=3 (60ms) All: srtt=11 (27ms), dev=4 (20ms), cur=3 (60ms) /files1 from ws2:/files1 Flags: hard,intr,dynamic read size=8192, write size=8192, retrans = 5 Lookups: srtt=8 (20ms), dev=4 (20ms), cur=3 (60ms) All: srtt=8 (20ms), dev=4 (20ms), cur=3 (60ms) # nfsstat -n Server nfs: calls badcalls 4162132 0 null getattr setattr root lookup readlink read 14 0% 694625 17% 33302 1% 0 0% 2579204 62% 12561 0% 167293 4% wrcache write create remove rename link symlink 0 0% 154051 4% 6310 0% 4870 0% 709 0% 1665 0% 0 0% mkdir rmdir readdir statfs 368 0% 367 0% 505799 12% 994 0% Client nfs: calls badcalls nclget nclcreate 26512 0 26512 0 null getattr setattr root lookup readlink read 0 0% 3771 14% 169 1% 0 0% 3775 14% 4 0% 6495 24% wrcache write create remove rename link symlink 0 0% 11643 44% 182 1% 74 0% 133 1% 0 0% 0 0% mkdir rmdir readdir statfs 0 0% 0 0% 124 0% 142 1% #
In the first set of output, note the srtt times. This is the smoothed round trip time or how responsive the server has been to NFS requests. Of course, the smaller the better, but the times shown in the example are pretty typical.
In the second set of output you can see what kinds of calls are being made. This will help you tune the system. Comparing periodic output of this second set of numbers can show you the load on your NFS servers.
arp
The correct arp table can be printed with the command:
# arp -a Net to Media Table Device IP Address Mask Flags Phys Addr ——— —————————— ——————— —— ——————— le0 xterm 255.255.255.255 00:80:96:00:0c:bd le0 gateway 255.255.255.255 00:00:c0:c7:f4:14 le0 ws2 255.255.255.255 08:00:20:0e:b9:d3 le0 ws4 255.255.255.255 00:00:c0:51:6f:5b le0 ws1 255.255.255.255 SP 08:00:20:1d:4e:1b le0 224.0.0.0 240.0.0.0 SM 01:00:5e:00:00:00 #
The arp command prints the current contents of the address resolution protocol cache. This is the table that maps IP addresses to EtherNet addresses. In troubleshooting you are looking to see that the proper EtherNet address is listed for the IP address
in question. If a second node is masquerading with an incorrect EtherNet address, the ARP table will show this. You can use the -d option to arp to delete an entry from the cache to see which system responds to that IP address translation request.
ping
ping has two uses. The first is to see if a host is reachable. It's not enough to say it sees if the host is up; ping also checks that you have a valid and operational route to the node. Both versions produce output as follows:
# ping gateway gateway is alive # # ping -s gateway 64 bytes from gateway (190.109.252.34): icmp_seq=0. time=3. ms 64 bytes from gateway (190.109.252.34): icmp_seq=1. time=1. ms 64 bytes from gateway (190.109.252.34): icmp_seq=2. time=3. ms 64 bytes from gateway (190.109.252.34): icmp_seq=3. time=1. ms ——gateway PING Statistics—— 4 packets transmitted, 4 packets received, 0% packet loss round-trip (ms) min/avg/max = 1/2/3 #
In the first case, ping was just used to check whether the host was reachable. This gives you confidence that the rest of the configuration is usable. The second output shows you whether packets are getting lost and the roundtrip time for the ICMP echo
ping uses.
If you see packet losses where sequence numbers are missing, look for hardware problems and overloaded networks.
traceroute
Packets can get lost from anywhere. Getting a host unreachable or network unreachable error really doesn't tell you much. You need to know how far the packets are getting before things go awry. Using the ICMP echo command along with a time-out field in
the packet, the traceroute command can cause each hop in the route to identify itself. Running trace route from your gateway to uunet's ftp host yields:
# /etc/traceroute ftp.uu.net traceroute to ftp.uu.net (192.48.96.9), 30 hops max, 40 byte packets 1 gateway (190.109.252.1) 5 ms 2 ms 2 ms 2 phl3-gw.PREPNET.COM (129.250.26.1) 6 ms 7 ms 6 ms 3 pgh4-gw.PREPNET.COM (129.250.3.2) 32 ms 28 ms 24 ms 4 psc-gw.PREPNET.COM (129.250.10.2) 68 ms 27 ms 25 ms 5 enss-e.psc.edu (192.5.146.253) 48 ms 48 ms 52 ms 6 t3-0.Cleveland-cnss41.t3.ans.net (140.222.41.1) 60 ms 53 ms * 7 mf-0.Cleveland-cnss40.t3.ans.net (140.222.40.222) 34 ms 29 ms 36 ms 8 t3-1.New-York-cnss32.t3.ans.net (140.222.32.2) 41 ms 39 ms 516 ms 9 * t3-1.Washington-DC-cnss56.t3.ans.net (140.222.56.2) 65 ms 72 ms 10 mf-0.Washington-DC-cnss58.t3.ans.net (140.222.56.194) 82 ms 85 ms * 11 t3-0.enss136.t3.ans.net (140.222.136.1) 89 ms * * 12 Washington.DC.ALTER.NET (192.41.177.248) 88 ms 87 ms 72 ms 13 Falls-Church1.VA.ALTER.NET (137.39.43.97) 106 ms 67 ms 77 ms 14 IBMpc01.UU.NET (137.39.43.34) 79 ms 97 ms 74 ms 15 ftp.UU.NET (192.48.96.9) 83 ms 75 ms 72 ms #
Just to send a packet to UUnet in Virginia from Philadelphia took 15 hops. Wherever you see a * is where no packet was received before the time-out. However, if the list stopped part way down and just listed each * from then on, or listed !H (host
unreachable) or !N (network unreachable), you know where to start looking for the problem.
snoop
When all else fails and you need to see exactly what is being transmitted over the network, it's snoop to the rescue. snoop places the EtherNet interface in promiscuous mode and listens to all traffic on the network. Then it uses its filtering abilities
to produce listings of the relevant traffic. It also can decode the data in the traffic for many of the IP subprotocols.
snoop has the ability to record and later analyze traffic capture files. Its arguments are too complex to cover here, but it is a good tool to use when everyone is claiming that a packet never did get sent.
Summary
UNIX and TCP/IP networking are very tightly bound together. A UNIX system can be run standalone, and it also seamlessly runs over a network. This chapter introduces the basics of UNIX networking. If you intend to program UNIX systems in C using the
networking calls, there is still much more to learn. However, what is presented here should provide a system administrator what he or she needs to know to understand how to configure and run the network.
The most important task of administering a network is to plan. Many of the problems you will run into later can easily be avoided by planning server placement, traffic flows, routers, and gateways, and especially security controls. The network is a back
door to every one of your systems. Your overall security is as secure or as weak as the weakest of all your systems. Don't let this scare you—it is quite possible to plan and install a secure network of systems. You need to plan where the firewalls
have to be placed and what access you are going to allow each system.
NFS will allow you to balance your disk requirements and your disk space availability across the entire network. Use of the automounter will allow this to be transparent to your users. Make generous use of both.
NIS will make your life easier by allowing you to maintain a single copy of the system administration files.
Finally, realize that others have also had to troubleshoot the network when things go wrong, so the tools are already there. Make use of them to find the problems.
Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451