Web based School


- Development of the Socket Programming Interface
- Socket Services
- Transmission Control Block
- Creating a Socket
- Binding the Socket
- Connecting to the Destination
- The open Command
- Sending Data
- Receiving Data
- Server Listening
- Getting Status Information
- Closing a Connection
- Aborting a Connection
- UNIX Forks
- Summary
- Q&A
- Quiz
— 14 —
The Socket Programming Interface
The Socket Programming Interface
Today I look at the last remaining aspect of TCP/IP this course covers: the socket interface for programming. This information is intended to convey the process needed to integrate an application with TCP/IP and as such involves some basic programming functions. It is not necessary to understand programming to understand this information. The functions involved in the socket programming interface help you understand the steps TCP/IP goes through when creating connections and sending data.
Understanding the socket interface is helpful even if you never intend to write a line of TCP/IP code, because all the applications you will work with use these principles and procedures. Debugging or troubleshooting a problem is much easier when you understand what is going on behind the user interface. Today I don't attempt to show the complete socket interface. Instead I deal only with the primary functions necessary to create and maintain a connection. This chapter is not intended to be a programming guide, either.
Because the original socket interface was developed for UNIX systems, today's text has a decidedly UNIX-based orientation. However, the same principles apply to most other operating systems that support TCP/IP.
Development of the Socket Programming Interface
TCP/IP is fortunate because it has a well-defined application programming interface (API), which dictates how an application uses TCP/IP. This solves a basic problem that has occurred on many other communications protocols, which have several approaches to the same problem, each incompatible with the other. The TCP/IP API is portable (it works across all operating systems and hardware that support TCP/IP), language-independent (it doesn't matter which language you use to write the application), and relatively uncomplicated.
The Socket API was developed at the University of California at Berkeley as part of their BSD 4.1c UNIX version. Since then the API has been modified and enhanced but still retains its BSD flavor. Not to be outdone, AT&T (BSD's rival in the UNIX market) introduced the Transport Layer Interface (TLI) for TCP and several other protocols. One of the strengths of the Socket API and TLI is that they were not developed exclusively for TCP/IP but are intended for use with several communications protocols. The Socket interface remains the most widespread API in current use, although several newer interfaces are being developed.
The basic structure of all socket programming commands lies with the unique structure of UNIX I/O. With UNIX, both input and output are treated as simple pipelines, where the input can be from anything and the output can go anywhere. The UNIX I/O system is sometimes referred to as the open-read-write-close system, because those are the steps that are performed for each I/O operation, whether it involves a file, a device, or a communications port.
Whenever a file is involved, the UNIX operating system gives the file a file descriptor, a small number that uniquely identifies the file. A program can use this file descriptor to identify the file at any time. (The same holds true for a device; the process is the same.) A file operation uses an open function to return the file descriptor, which is used for the read (transfer data to the user's process) or write (transfer data from the user process to the file) functions, followed by a close function to terminate the file operation. The open function takes a filename as an argument. The read and write functions use the file descriptor number, the address of the buffer in which to read or write the information, and the number of bytes involved. The close function uses the file descriptor. The system is easy to use and simple to work with.
TCP/IP uses the same idea, relying on numbers to uniquely identify an end point for communications (a socket). Whenever the socket number is used, the operating system can resolve the socket number to the physical connector. An essential difference between a file descriptor and a socket number is that the socket requires some functions to be performed prior to the establishment of the socket (such as initialization). In techno-speak, "a file descriptor binds to a specific file or device when the open function is called, but the socket can be created without binding them to a specific destination at all (necessary for UDP), or bind them later (for TCP when the remote address is provided)." The same open-read-write-close procedure is used with sockets.
The process was actually used literally with the first versions of TCP/IP. A special file called /dev/tcp was used as the device driver. The complexity added by networking made this approach awkward, though, so a library of special functions (the API) was developed. The essential steps of open, read, write, and close are still followed in the protocol API.
Socket Services
There are three types of socket interfaces defined in the TCP/IP API. A socket can be used for TCP stream communications, in which a connection between two machines is created. It can be used for UDP datagram communications, a connectionless method of passing information between machines using packets of a predefined format. Or it can be used as a raw datagram process, in which the datagrams bypass the TCP/UDP layer and go straight to IP. The latter type arises from the fact that the socket API was not developed exclusively for TCP/IP.
The presence of all three types of interfaces can lead to problems with some parameters that depend exclusively on the type of interface. You must always bear in mind whether TCP or UDP is used.
There are six basic communications commands that the socket API addresses through the TCP layer:
- open: Establishes a socket
- send: Sends data to the socket
- receive: Receives data from a socket
- status: Obtains status information about a socket
- close: Terminates a connection
- abort: Cancels an operation and terminates the connection
All six operations are logical and used as you would expect. The details for each step can be quite involved, but the basic operation remains the same. Many of the functions have been seen in previous days when dealing with specific protocols in some detail. Some of the functions (such as open) comprise several other functions that are available if necessary (such as establishing each end of the connection instead of both ends at once).
Despite the formal definition of the functions within the API specifications, no formal method is given for how to implement them. There are two logical choices: synchronous, or blocking, in which the application waits for the command to complete before continuing execution; and asynchronous, or nonblocking, in which the application continues executing while the API function is processed. In the latter case, a function call further in the application's execution can check the API functions' success and return codes.
The problem with the synchronous or blocking method is that the application must wait for the function call to complete. If timeouts are involved, this can cause a noticeable delay for the user.
Transmission Control Block
The Transmission Control Block (TCB) is a complex data structure that contains details about a connection. The full TCB has over fifty fields in it. The exact layout and contents of the TCB are not necessary for today's material, but the existence of the TCB and the nature of the information it holds are key to the behavior of the socket interface.
Creating a Socket
The API lets a user create a socket whenever necessary with a simple function call. The function requires the family of the protocol to be used with the socket (so the operating system knows which type of socket to assign and how to decode information), the type of communication required, and the specific protocol. Such a function call is written as follows:
socket(family, type, protocol)
The family of the protocol actually specifies how the addresses are interpreted. Examples of families are TCP/IP (coded as AF_INET), Apple's AppleTalk (AF_APPLETALK), and UNIX filesystems (AF_UNIX). The exact protocol within the family is specified as the protocol parameter. When used, it specifically indicates the type of service that is to be used.
The type parameter indicates the type of communications used. It can be a connectionless datagram service (coded as SOCK_DGRAM), a stream delivery service (SOCK_STREAM), or a raw type (SOCK_RAW). The result from the function call is an integer that can be assigned to a variable for further checking.
Binding the Socket
Because a socket can be created without any binding to an address, there must be a function call to complete this process and establish the full connection. With the TCP/IP protocol, the socket function does not supply the local port number, the destination port, or the IP address of the destination. The bind function is called to establish the local port address for the connection.
Some applications (especially on a server) want to use a specific port for a connection. Other applications are content to let the protocol software assign a port. A specific port can be requested in the bind function. If it is available, the software allocates it and returns the port information. If the port cannot be allocated (it might be in use), a return code indicates an error in port assignment.
The bind function has the following format:
bind(socket, local_address, address_length)
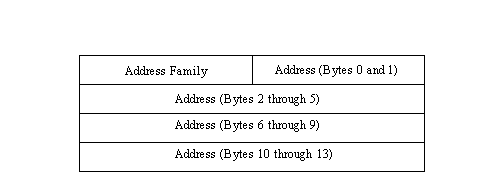
socket is the integer number of the socket to which the bind is completed; local_address is the local address to which the bind is performed; and address_length is an integer that gives the length of the address in bytes. The address is not returned as a simple number but has the structure shown in Figure 14.1.
Figure 14.1. Address structure used by the socket API.
The address data structure (which is called usually called sockaddr for socket address) has a 16-bit Address Family field that identifies the protocol family of the address. The entry in this field determines the format of the address in the following field (which might contain other information than the address, depending on how the protocol has defined the field). The Address field can be up to 14 bytes in length, although most protocols do not need this amount of space.
The use of a data structure instead of a simple address has its roots in the UNIX operating system and the closely allied C programming language. The formal structure of the socket address enables C programs to use a union of structures for all possible address families. This saves a considerable amount of coding in applications.
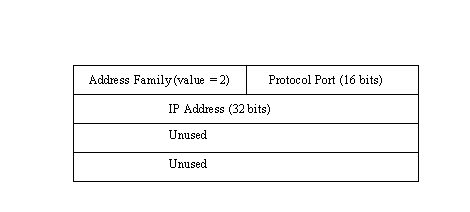
TCP/IP has a family address of 2, following which the Address field contains both a protocol port number (16 bits) and the IP address (32 bits). The remaining eight bytes are unused. This is shown in Figure 14.2. Because the address family defines how the Address field is decoded, there should be no problem with TCP/IP applications understanding the two pieces of information in the Address field.
Figure 14.2. The address structure for TCP/IP.
Connecting to the Destination
After a local socket address and port number have been assigned, the destination socket can be connected. A one-ended connection is referred to as being in an unconnected state, whereas a two-ended (complete) connection is in a connected state. After a bind function, an unconnected state exists. To become connected, the destination socket must be added to complete the connection.
To establish a connection to a remote socket, the connect function is used. The connect function's format is
connect(socket, destination_address, address_length)
The socket is the integer number of the socket to which to connect; the destination_address is the socket address data structure for the destination address (using the same format as shown in Figure 14.1); and the address_length is the length of the destination address in bytes.
The manner in which connect functions is protocol-dependent. For TCP, connect establishes the connection between the two endpoints and returns the information about the remote socket to the application. If a connection can't be established, an error message is generated. For a connectionless protocol such as UDP, the connect function is still necessary but stores only the destination address for the application.
The open Command
The open command prepares a communications port for communications. This is an alternative to the combination of the functions shown previously, used by applications for specific purposes. There are really three kinds of open commands, two of which set a server to receive incoming requests and the third used by a client to initiate a request. With every open command, a TCB is created for that connection.
The three open commands are an unspecified passive open (which enables a server to wait for a connection request from any client), a fully specified passive open (which enables a server to wait for a connection request from a specific client), and an active open (which initiates a connection with a server). The input and output expected from each command are shown in Table 14.1.
|
Type |
Input |
Output
| Unspecified
| local port
| local connection name
| passive open
| Optional: timeout, precedence, security, maximum segment size
| local connection name
| Fully specified passive open
| local port, remote IP address, remote port Optional: timeout, precedence, security, maximum segment size
| local connection name
| Active open
| local port, destination IP address, destination port Optional: timeout, precedence, security, maximum segment size
| local connection name |
When an open command is issued by an application, a set of functions within the socket interface is executed to set up the TCB, initiate the socket number, and establish preliminary values for the variables used in the TCB and the application.
The passive open command is issued by a server to wait for incoming requests. With the TCP (connection-based) protocol, the passive open issues the following function calls:
- socket: Creates the sockets and identifies the type of communications.
- bind: Establishes the server socket for the connection.
- listen: Establishes a client queue.
- accept: Waits for incoming connection requests on the socket.
The active open command is issued by a client. For TCP, it issues two functions:
- socket: Creates the socket and identifies the communications type.
- connect: Identifies the server's IP address and port; attempts to establish communications.
If the exact port to use is specified as part of the open command, a bind function call replaces the connect function.
Sending Data
There are five functions within the Socket API for sending data through a socket. These are send, sendto, sendmsg, write, and writev. Not surprisingly, all these functions send data from the application to TCP. They do this through a buffer created by the application (for example, it might be a memory address or a character string), passing the entire buffer to TCP. The send, write, and writev functions work only with a connected socket because they have no provision to specify a destination address within their function call.
The format of the send function is simple. It takes the local socket connection number, the buffer address for the message to be sent, the length of the message in bytes, a Push flag, and an Urgent flag as parameters. An optional timeout might be specified. Nothing is returned as output from the send function. The format is
send(socket, buffer_address, length, flags)
The sendto and sendmsg functions are similar except they enable an application to send a message through an unconnected socket. They both require the destination address as part of their function call. The sendmsg function is simpler in format than the sendto function, primarily because another data structure is used to hold information. The sendmsg function is often used when the format of the sendto function would be awkward and inefficient in the application's code. Their formats are
sendto(socket, buffer_address, length, flags, destination, address_length) sendmsg(socket, message_structure, flags)
The last two parameters in the sendto function are the destination address and the length of the destination address. The address is specified using the format shown in Figure 14.1. The message_structure of the sendmsg function contains the information left out of the sendto function call. The format of the message structure is shown in Figure 14.3.
Figure 14.3. The message structure used by sendmsg.
The fields in the sendmsg message structure give the socket address, size of the socket address, a pointer to the iovector, which contains information about the message to be sent, the length of the iovector, the destination address, and the length of the destination address.
The iovector is an address for an array that points to the message to be sent. The array is a set of pointers to the bytes that comprise the message. The format of the iovector is simple. For each 32-bit address to a memory location with a chunk of the message, a corresponding 32-bit field holds the length of the message in that memory location. This format is repeated until the entire message is specified. This is shown in Figure 14.4. The iovector format enables a noncontiguous message to be sent. In other words, the first part of the message can be in one location in memory, and the rest is separated by other information. This can be useful because it saves the application from copying long messages into a contiguous location.
Figure 14.4. The iovector format.
The write function takes three arguments: the socket number, the buffer address of the message to be sent, and the length of the message to send. The format of the function call is
write(socket, buffer_address, length)
The writev function is similar to write except it uses the iovector to hold the message. This lets it send a message without copying it into another memory address. The format of writev is
writev(socket, iovector, length)
where length is the number of entries in iovector.
The type of function chosen to send data through a socket depends on the type of connection used and the level of complexity of the application. To a considerable degree, it is also a personal choice of the programmer.
Receiving Data
Not surprisingly, because there are five functions to send data through a socket, there are five corresponding functions to receive data: read, readv, recv, recvfrom, and recvmsg. They all accept incoming data from a socket into a reception buffer. The receive buffer can then be transferred from TCP to the application.
The read function is the simplest and can be used only when a socket is connected. Its format is
read(socket, buffer, length)
The first parameter is the number of the socket or a file descriptor from which to read the data, followed by the memory address in which to store the incoming data, and the maximum number of bytes to be read.
As with writev, the readv command enables incoming messages to be placed in noncontiguous memory locations through the use of an iovector. The format of readv is
readv(socket, iovector, length)
length is the number of entries in the iovector. The format of the iovector is the same as mentioned previously and shown in Figure 14.4.
The recv function also can be used with connected sockets. It has the format
recv(socket, buffer_address, length, flags)
which corresponds to the send function's arguments.
The recvfrom and recvmsg functions enable data to be read from an unconnected socket. Their formats include the sender's address:
recvfrom(socket, buffer_address, length, flags, source_address, address_length) recvmsg(socket, message_structure, flags)
The message structure in the recvmsg function corresponds to the structure in sendmsg. (See Figure 14.3.)
Server Listening
A server application that expects clients to call in to it has to create a socket (using socket), bind it to a port (with bind), then wait for incoming requests for data. The listen function handles problems that could occur with this type of behavior by establishing a queue for incoming connection requests. The queue prevents bottlenecks and collisions, such as when a new request arrives before a previous one has been completely handled, or two requests arrive simultaneously.
The listen function establishes a buffer to queue incoming requests, thereby avoiding losses. The function lets the socket accept incoming connection requests, which are all sent to the queue for future processing. The function's format is
listen(socket, queue_length)
where queue_length is the size of the incoming buffer. If the buffer has room, incoming requests for connections are added to the buffer and the application can deal with them in the order of reception. If the buffer is full, the connection request is rejected.
After the server has used listen to set up the incoming connection request queue, the accept function is used to actually wait for a connection. The format of the function is
accept(socket, address, length)
socket is the socket on which to accept requests; address is a pointer to a structure similar to Figure 14.1; and length is a pointer to an integer showing the length of the address.
When a connection request is received, the protocol places the address of the client in the memory location indicated by the address parameter, and the length of that address in the length location. It then creates a new socket that has the client and server connected together, sending back the socket description to the client. The socket on which the request was received remains open for other connection requests. This enables multiple requests for a connection to be processed, whereas if that socket was closed down with each connection request, only one client/server process could be handled at a time.
One possible special occurrence must be handled on UNIX systems. It is possible for a single process to wait for a connection request on multiple sockets. This reduces the number of processes that monitor sockets, thereby lowering the amount of overhead the machine uses. To provide for this type of process, the select function is used. The format of the function is
select(num_desc, in_desc, out_desc, excep_desc, timeout)
num_desc is the number of sockets or descriptors that are monitored; in_desc and out_desc are pointers to a bit mask that indicates the sockets or file descriptors to monitor for input and output, respectively; excep_desc is a pointer to a bit mask that specifies the sockets or file descriptors to check for exception conditions; and timeout is a pointer to an integer that indicates how long to wait (a value of 0 indicates forever). To use the select function, a server creates all the necessary sockets first, then calls select to determine which ones are for input, output, and exceptions.
Getting Status Information
Several status functions are used to obtain information about a connection. They can be used at any time, although they are typically used to establish the integrity of a connection in case of problems or to control the behavior of the socket.
The status functions require the name of the local connection, and they return a set of information, which might include the local and remote socket names, local connection name, receive and send window states, number of buffers waiting for an acknowledgment, number of buffers waiting for data, and current values for the urgent state, precedence, security, and timeout variables. Most of this information is read from the Transmission Control Block (TCB). The format of the information and the exact contents vary slightly, depending on the implementation.
The function getsockopt enables an application to query the socket for information. The function format is
getsockopt(socket, level, option_id, option_result, length)
socket is the number of the socket; level indicates whether the function refers to the socket itself or the protocol that uses it; option_id is a single integer that identifies the type of information requested; option_result is a pointer to a memory location where the function should place the result of the query; and length is the length of the result.
The corresponding setsockopt function lets the application set a value for the socket. The function's format is the same as getsockopt except that option_result points to the value that is to be set, and length is the length of the value.
Two functions provide information about the local address of a socket. The getpeername function returns the address of the remote end. The getsockname function returns the local address of a socket. They have the following formats:
getpeername(socket, destination_address, address_length) getsockname(socket, local_address, address_length)
The addresses in both functions are pointers to a structure of the format shown in Figure 14.1.
Two host name functions for BSD UNIX are gethostname and sethostname, which enable an application to obtain the name of the host and set the host name (if permissions allow). Their formats are as follows:
sethostname(name, length) gethostname(name, length)
The name is the address of an array that holds the name, and the length is an integer that gives the name's length.
A similar set of functions provides for domain names. The functions setdomainname and getdomainname enable an application to obtain or set the domain names. Their formats are
setdomainname(name, length) getdomainname(name, length)
The parameters are the same as with the sethostname and gethostname functions, except for the format of the name (which reflects domain name format).
Closing a Connection
The close function closes a connection. It requires only the local connection name to complete the process. It also takes care of the TCB and releases any variable created by the connection. No output is generated.
The close function is initiated with the call
close(socket)
where the socket name is required. If an application terminates abnormally, the operating system closes all sockets that were open prior to the termination.
Aborting a Connection
The abort function instructs TCP to discard all data that currently resides in send and receive buffers and close the connection. It takes the local connection name as input. No output is generated. This function can be used in case of emergency shutdown routines, or in case of a fatal failure of the connection or associated software.
The abort function is usually implemented by the close() call, although some special instructions might be available with different implementations.
UNIX Forks
UNIX has two system calls that can affect sockets: fork and exec. Both are frequently used by UNIX developers because of their power. (In fact, forks are one of the most powerful tools UNIX offers, and one that most other operating systems lack.) For simplicity, I deal with the two functions as though they perform the same task.
A fork call creates a copy of the existing application as a new process and starts executing it. The new process has all the original's file descriptors and socket information. This can cause a problem if the application programmer didn't take into account the fact that two (or more) processes try to use the same socket (or file) simultaneously. Therefore, applications that can fork have to take into account potential conflicts and code around them by checking the status of shared sockets.
The operating system itself keeps a table of each socket and how many processes have access to it. An internal counter is incremented or decremented with each process's open or close function call for the socket. When the last process using a socket is terminated, the socket is permanently closed. This prevents one forked process from closing a socket when its original is still using it.
Summary
Today you have seen the basic functions performed by the socket API during establishment of a TCP or UDP call. You have also seen the functions that are available to application programmers. Although the treatment has been at a high level, you should be able to see that working with sockets is not a complex, confusing task. Indeed, socket programming is surprisingly easy once you have tried it.
Not everyone wants to write TCP or UDP applications, of course. However, understanding the basics of the socket API helps in understanding the protocol and troubleshooting. If you are interested in programming sockets, one of the best guides on the subject is UNIX Network Programming, by W. Richard Stevens (Macmillan).
Q&A
What is the socket interface used for?
The socket interface enables you to write applications that make optimal use of the TCP/IP family of protocols. Without it, you would need another layer of application to translate your program's calls to TCP/IP calls.
What is the difference between blocking and nonblocking functions?
A blocking function waits for the function to terminate before enabling the application to continue. A nonblocking function enables the application to continue executing while the function is performed. Both have important uses in applications.
What does binding do?
Binding makes a logical connection between a socket and the application. Without it, the application couldn't access the socket.
What happens when an active open command is executed?
An active open command creates a socket and binds it, then issues a connect call to identify the IP address and port. The active open command then tries to establish communications.
What is the difference between an abort and a close operation?
A close operation closes a connection. An abort abandons whatever communications are currently underway and closes the connection. With an abort, any information in receive buffers is discarded.
Quiz
- What are the six basic socket commands?
- A Transmission Control Block performs what function?
- What is the difference between an unspecified passive open and a fully specified passive open?
- What command displays status information about a socket?
- What is a fork?

Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451




{kind=link}
{kind=link}
{kind=link}
{kind=link}