Web based School
Chapter 1
An Introduction to CGI and Its Environment
- The Common Gateway Interface (CGI)
- HTML, HTTP, and Your CGI Program
- The Directories on Your Server
- File Privileges, Permissions, and Protection
- WWW Servers
- The CGI Programming Paradigm
- Preventing the Most Common CGI Bugs
- Learning Perl
- Summary
- Q&A
Welcome to Teach Yourself CGI Programming with Perl 5 in a Week, 2E! This is going to be a very busy week. You will need all seven days, but at the end of the week you will be ready to create interactive Web sites using your own CGI programs. This guide does not assume that you have experience with the programming language Perl and makes very few assumptions about prior programming experience.
This guide does assume that you already have been on the Internet and that you understand the definition of a Web page. You do not have to be a Web page author to understand this guide. A basic understanding of HTML is helpful, however. This guide spends significant time explaining how to use the HTML Form tag and its components to create Web forms for getting information from your Web clients.
As new topics are introduced throughout the guide, most will include an example. And with each new programming example will come a detailed analysis of the new CGI features in that example. CGI programming is a mixture of understanding and using the HyperText Markup Language (HTML) and the HyperText Transport Protocol (HTTP), as well as writing code. You must follow the HTML and HTTP specifications, but you can use any programming language with which you are comfortable. For most applications, I recommend Perl.
This guide is written primarily for the UNIX environment. Because Perl works on any platform and the HTTP and HTML specifications can work on any platform, you can apply what you learn from this guide to non-UNIX operation systems.
Most of the Net right now is UNIX based. "Why is that?" you might ask. Well, it has a lot to do with UNIX's more than 20 years of dominance in networked environments. Like everything else in the computer industry, I'm sure this will change, but UNIX is the platform of choice for Internet applications-at least for now. This guide therefore assumes that you are programming on a UNIX server. Your WWW server probably is ncSA, CERN, or some derivative of these two-such as Apache. If you are using some other server (such as Netscape's secure server or a Windows NT server), don't despair. Most of this guide also applies to your environment.
In this chapter, you will learn the basics of how to install your CGI programs, and you will get an overview of how they work with your server. You also will learn how to avoid some of the common mistakes that come up when you are starting out with CGI programming.
In particular, you will learn about the following:
- The Common Gateway Interface (CGI)
- How HTML, HTTP, and your CGI program work together
- What is required to make your CGI program work
- Why the CGI program is different from most other programming techniques
- The most common reasons your first CGI program does not work
By the way, you should read each chapter of this guide sequentially. Each chapter builds on the knowledge of the preceding chapter.
The Common Gateway Interface (CGI)
What is CGI programming anyway? What is the BIG DEAL?? And why the heck is it called a gateway?
Very good questions. Ones that bugged me early on and ones that still seem to be asked quite frequently.
CGI programming involves designing and writing programs that receive their starting commands from a Web page-usually, a Web page that uses an HTML form to initiate the CGI program. The HTML form has become the method of choice for sending data across the Net because of the ease of setting up a user interface using the HTML Form and Input tags. With the HTML form, you can set up input windows, pull-down menus, checkboxes, radio buttons, and more with very little effort. In addition, the data from all these data-entry methods is formatted automatically and sent for you when you use the HTML form. You learn about the details of using the HTML form in Chapters 4, "Using Forms to Gather and Send Data," and 5, "Decoding Data Sent to Your CGI Program."
CGI programs don't have to be started by a Web page, however. They can be started as the result of a Server Side Include (SSI) execution command (covered in detail in Chapter 3 "Using Server Side Include Commands"). You even can start a CGI program from the command line. But a CGI program started from the command line probably will not act the way you expect or designed it to act. Why is that? Well, a CGI program runs under a unique environment. The WWW server that started your CGI program creates some special information for your CGI program, and it expects some special responses back from your CGI program.
Before your CGI program is initiated, the WWW server already has created a special processing environment for your CGI program in which to operate. That environment includes translating all the incoming HTTP request headers (covered in Chapter 2 "Understanding How the Server and Browser Communicate") into environment variables (covered in Chapter 6 "Using Environment Variables in Your Programs") that your CGI program can use for all kinds of valuable information. In addition to system information (such as the current date), the environment includes information about who is calling your CGI program, from where your program is being called, and possibly even state information to help you keep track of a single Web visitor's actions. (State information is anything that keeps track of what your program did the last time it was called.)
Next, the server tries to determine what type of file or program it is calling because it must act differently based on the type of file it is accessing. So, your WWW server first looks at the file extension to determine whether it needs to parse the file looking for SSI commands, execute the Perl interpreter to compile and interpret a Perl program, or just generate the correct HTTP response headers and return an HTML file.
After your server starts up your SSI or CGI program (or even HTML file), it expects a specific type of response from the SSI or CGI program. If your server is just returning an HTML file, it expects that file to be a text file with HTML tags and text in it. If the server is returning an HTML file, the server is responsible for generating the required HTTP response headers, which tell the calling browser the status of the browser's request for a Web page and what type of data the browser will be receiving, among other things.
The SSI file works almost like a regular HTML file. The only difference is that, with an SSI file, the server must look at each line in the file for special SSI commands. If it finds an SSI command, it tries to execute it. The output from the executed SSI command is inserted into the returned HTML file, replacing the special HTML syntax for calling an SSI command. The output from the SSI command will appear within the HTML text just as if it were typed at the location of the SSI command. SSI commands can include other files, execute system commands, and perform many useful functions. The server uses the file extension of the requested Web page to determine whether it needs to parse a file for SSI commands. SSI files typically have the extension .shtml.
If the server identifies the file as an executable CGI program, it executes the program as appropriate. After the server executes your CGI program, your program normally responds with the minimum required HTTP response headers and then some HTML tags. If your CGI program is returning HTML, it should output a response header of Content-Type: text/html. This gives the server enough information to generate any other required HTTP response headers.
After all that explanation, what is CGI programming? CGI programming is writing the programs that receive and translate data sent via the Internet to your WWW server. CGI programming is using that translated data and understanding how to send valid HTTP response headers and HTML tags back to your WWW client.
The big deal in all this is a brand new dynamic programming environment. All kinds of new commerce and applications are going to occur over the Internet. You can't do this with just HTML. HTML by itself makes a nice window, but to do anything more than look pretty requires programming, and that programming must understand the CGI environment.
Finally, just why is it called gateway? Quite often, your program acts as a gateway or interface program between other, larger applications. CGI programs often are written in scripting languages such as Perl. Scripting languages really are not meant for large applications. You might create a program that translates and formats the data being sent to it from applications such as online catalogs, for example. This translated data then is passed to some type of database program. The database program does the necessary operations on its database and returns the results to your CGI program. Your CGI program then can reformat the returned data as needed for the Internet and return it to the online catalog customer, thus acting as a gateway between the HTML catalog, the HTTP request/response headers, and the database program. I'm sure that you can think of other, cooler examples, but this one probably will be pretty common in the near future.
You already can see a lot of interaction between the HTTP request/response headers, HTML, and your CGI programs. Each of these topics is covered in detail in this guide, but you should understand how these pieces fit together to create the entire CGI environment.
HTML, HTTP, and Your CGI Program
HTML, HTTP, and your CGI program have to work closely together to make your online Internet application work. The HTML code defines the way the user sees your program interface, and it is responsible for collecting user input. This frequently is referred to as the Human Computer Interface code; it is the window through which your program and the user interact. HTTP is the transport mechanism for sending data between your CGI program and the user. This is the behind-the-scenes director that translates and sends information between your Web client and your CGI program. Your CGI program is responsible for understanding both the HTTP directions and the user requests. The CGI program takes the requests from the user and sends back valid and useful responses to the Web client who is clicking away on your HTML Web page.
The Role of HTML
HTML is designed primarily for formatting text. It is basically a typesetting language that specifies the shape of the text, the color, where to put it, and how large to make it. It's not much different from most other typesetting languages, except that it doesn't have as many typesetting options as most simple What You See Is What You Get (WYSIWYG) editors, such as Microsoft Word. So how does it get involved with your CGI program? The primary method is through the HTML Form tags. Your CGI program does not have to be called through an HTML form, however; it can be invoked through a simple hypertext link using the anchor (<a>) tag-something like this:
<a href="A CGI program"> Some text </a>
The CGI program in this hypertext reference or link is called (or activated) in a manner similar to that used when being called from an HTML form.
You even can use a hypertext link to pass extra data to your CGI program. All you have to do is add more information after the CGI program name. This information usually is referred to as extra path information, but it can be any type of data that might help identify to your CGI program what it needs to do.
The extra path information is provided to your CGI program in a variable called PATH_INFO, and it is any data after the CGI program name and before the first question mark (?) in the href string. If you include a question mark (?) after the CGI program name and then include more data after the question mark, the data goes in a variable called the QUERY_STRING. Both PATH_INFO and QUERY_STRING are covered in Chapter 6.
So to put this all into an example, suppose that you create a link to your CGI program that looks like this:
<a href=www.practical-inet.com/cgiguide/chap1/program.cgi/ extra-path-info?test=test-number-1> A CGI Program </a>
Then when you select the link A CGI program, the CGI program named program.cgi is activated. The environment variable PATH_INFO is set to extra-path-info and the QUERY_STRING environment variable is set to test=test-number-1.
Usually, this is not considered a good way to send data to your CGI program. First, it's harder for the programmer to modify data that is hard-coded in an HTML file because it cannot be done on-the-fly. Second, the data is easier to modify for the Web page visitor who is a hacker. Your Web page visitor can download the Web page onto his own computer and then modify the data your program is expecting. Then he can use the modified file to call your CGI program. Neither of these scenarios seems very pleasant. Many other people felt the same way, so this is where the HTML form comes in. Don't completely ignore this method of sending data to your program. There are valid reasons for using the extra-path-info variables. The imagemap program, for example, uses extra-path-info as an input parameter that describes the location of mapfiles. Imagemaps are covered in Chapter 9 "Using Imagemaps on Your Web Page."
The HTML form is responsible for sending dynamic data to your CGI program. The basics outlined here are still the same. Data is passed to the server for use by your CGI program, but the way you build your HTML form defines how that data is sent, and your browser does most of the data formatting for you.
The most important feature of the HTML form is the capability of the data to change based on user input. This is what makes the HTML Form tag so powerful. Your Web page client can send you letters, fill out registration forms, use clickable buttons and pull-down menus to select merchandise, or fill out a survey. With a clear understanding of the HTML Form tag, you can build highly interactive Web pages. Because this topic is so important, it is covered in Chapters 4 and 5, and the hidden field of the HTML form is explained in Chapter 7 "Building an Online Catalog."
So, to sum up, HTML and, in particular, the HTML Form tag, are responsible for gathering data and sending it to your CGI program.
The HTTP Headers
If HTML is responsible for gathering data to send to your CGI program, how does it get there? The data gathered by the browser gets to your CGI program through the magic of the HTTP request header. The HTML tags tell the browser what type of HTTP header to use to talk to the server-your CGI program. The basic HTTP headers for beginning communication with your CGI program are Get and Post.
If the HTML tag calling your program is a hypertext link, the default HTTP request method Get is used to communicate with your CGI program, as in this example:
<a href="www.domain.com/program.cgi">, call a CGI program </a>
If, instead of using a hypertext link to your program, you use the HTML Form tag, the Method attribute of the Form tag defines what type of HTTP request header is used to communicate with your CGI program. If the Method field is missing or is set to Get, the HTTP method request header type is Get. If the Method attribute is set to Post, a Post method request header is used to communicate with your CGI program. (The Get and Post methods are covered in Chapters 4 and 5.)
After the method of sending the data is determined, the data is formatted and sent using one of two methods. If the Get method is used, the data is sent via the Uniform Resource Identifier (URI) field. (URI is covered in Chapter 2.) If the Post method is used, the data is sent as a separate message, after all the other HTTP request headers have been sent.
After the browser determines how it is going to send the data, it creates an HTTP request header identifying where on the server your CGI program is located. The browser sends to the server this HTTP request header. The server receives the HTTP request header and calls your CGI program. Several other request headers can go along with the main request header to give the server and your CGI program useful information about the browser and this connection.
Your CGI program now performs some useful function and then tells the server what type of response it wants to send back to the server.
So where are we so far? The data has been gathered by the browser using the format defined by the HTML tags. The data/URI request has been sent to the server using HTTP request headers. The server used the HTTP request headers to find your CGI program and call it. Now your CGI program has done its thing and is ready to respond to the browser. What happens next? The server and your CGI program collaborate to send HTTP response headers back to the browser.
What about the data-the Web page-your CGI program generated? Well, that's why the HTTP response headers are used. They describe to the browser what type of data is being returned to the browser.
Your CGI program can generate all the HTTP response headers required for sending data back to the client/browser by calling itself a non-parsed header CGI program. If your CGI program is an NPH-CGI program, the server does not parse or look at the HTTP response headers generated by your CGI program; they are sent directly to the requesting browser, along with data/HTML generated by your CGI program.
The more common method of returning HTTP response headers is for your CGI program to generate the minimum required HTTP request headers; usually, just a Content-Type HTTP response header is required. The server then parses, or looks for, the response header your CGI program generated and determines what additional HTTP response headers should be returned to the browser.
The Content-Type HTTP response header identifies to the browser the type of data that will be returned to the browser. The browser uses the Content-Type response header to determine the types of viewers to activate so that the client can view things like inline images, movies, and HTML text.
The server adds the additional HTTP response headers it knows are required, bundles up the set of the headers and data in a nice TCP/IP package, and then sends it to the browser. The browser receives the HTTP response headers and displays the returned data as described by the HTTP response headers to your customer, the human.
So now you have the whole picture (which you will learn about in detail throughout the guide), made up of the HTML used to format the data and the HTTP request and response headers used to communicate between the browser and server what type of data is being sent back and forth. Among all this is your very cool CGI program, aware of what is going on around it and driving the real applications in which your Web client really is interested.
Your CGI Program
What about your CGI program? What is it and how does it fit into this scenario? Well, your CGI program can be anything you can imagine. That is what makes programming so much fun. Your CGI program must be aware of the HTTP request headers coming in and its responsibility to send HTTP response headers back out. Beyond that, your CGI program can do anything and work in any manner you choose.
For the purposes of this guide, I concentrate on CGI programs that work on UNIX platforms, and I use the Perl programming language. I focus on the UNIX platform because that is the platform of choice on the Net at this time. The most popular WWW servers are the ncSA httpd, CERN, Apache, and Netscape servers; all these Web servers sit most comfortably on UNIX operating systems. So, for the moment, most platforms on which CGI programs are developed are UNIX servers. It just makes sense to concentrate on the operating system on which most of the CGI applications are required to run.
But why Perl? Well, wouldn't it be nice to work with a language that you didn't have to compile? No messing with painful linker commands. No compilation steps at all. Just type it in and it's ready to go. What about a language that is free? Easy to get a hold of and available on just about any machine on the Net? How about a language that works well with and even looks like C, arguably the most popular programming language in the world? And wouldn't it be nice if that language worked well with the operating system, making each of your system calls easy to implement? And what about a programming language that works on almost any operating system? That way, if you change platforms from UNIX to Windows, NT, or Mac, your programs still run. Heck, why not just ask for a language that's easy to learn and for which a ton of free technical help is available? Ask for it. You've got it! Did that sound like an advertisement? And no, I don't have any vested interest in Perl.
Perl is rapidly becoming one of the most popular scripting languages anywhere because it really does satisfy most of the needs outlined here. It's free, works on almost any platform, and runs as soon as you type it in. As long as you don't have any bugs…
Perl is an excellent choice for all these reasons and more. The more is probably what makes the language so popular. If Perl could do all those wonderful things and turned out to be hard to work with, slow, and not secure, it probably would have lost the popularity war. But Perl is easy to work with, has built-in security features, and is relatively fast.
In fact, Perl was designed originally for working with text, generating reports, and manipulating files. It does all these things fairly well and fairly easily. Larry Wall and Randal L. Schwartz of Programming perl state that "The pattern matching and textual manipulation capabilities of Perl often outperform dedicated C programs."
In addition, Perl has a lovely data structure called the associative array that you can use for database manipulation. The designers of Perl also thought of security when they built the language. It has built-in security features like data-flow tracing, which enables you to find out where data that is not secure originated. This capability often prevents nonsecure operations before they can occur.
Most of these features are not covered in this guide. This guide does take the time to show you how to use Perl to develop CGI programs, however, which you will find helpful if you have never used Perl or are new to programming. After you get the basics from this guide, you should be able to understand other Perl CGI programs on the Net. As an added bonus, by learning Perl, you get an introduction to UNIX and C for free. These reasons were enough to make me want to learn Perl and are the reasons why you will use Perl throughout this guide.
At this point, you have a good overview of CGI programming and how the different pieces fit together. As you go through the guide, you will see that most of the topics in these first two sections are covered again in more detail and with specific examples. The next steps now are for you to learn more about your server, how to install CGI programs, and what makes CGI programming so different from other programming paradigms.
The Directories on Your Server
The first thing you need to learn is how to get around on your server. If you have a personal account with an Internet service provider, your personal directory should be based on your username. In my case, I have a personal account with an Internet service provider and a business account from which I manage multiple business Web pages. Your personal account probably is similar to mine; I can build Web pages for Internet access under a specific directory called public-web. The name isn't really important-just the concept of having a directory where specific operations are allowed.
Usually, you will find that your server is divided into two directory trees. A directory tree consists of a directory and the subdirectories below the main directory. Most UNIX Web servers separate their users from the system administrative files by creating separate directory trees called the server root and the document root.
The Server Root
The server root contains all the files for which the Webmaster or System Administrator is responsible. You probably will not be able to change these files, but there are several of them you will want to be aware of, because they provide valuable information about where your programs can run and what your CGI programs are allowed to do. Below the server root are two subdirectories that you should know about. Those directories, located on the ncSA server, usually are called the log directory and the conf directory. If you are not working on an ncSA server, you will find that the CERN and other servers have a similar directory structure with slightly different names.
The Log Directory
The log directory is where all the log files are kept. Within the log directory are your error log files. Error log files keep track of each command from your CGI, SSI commands, and HTML files that generates some type of error. When you are having problems getting something to work, the error log file is an excellent place to start your debugging. Usually, the file begins with err. On my server, the error log file is called error.log. Another log file you can make good use of is the access.log file. This file contains each file that was accessed by a user. This file often is used to derive access counts for your Web page. Building counters is discussed in Chapter 10, "Keeping Track of Your Web Page Visitors." Also in your log directory is a list of each of the different types of browsers accessing your Web site. On my server, this file is called the referer.log. You can use this information to direct a specific browser to Web pages written just for browsers that can or can't handle special HTML extensions. Redirecting a browser based on the browser type is discussed in Chapter 2. In addition to the log files are the configuration files below the conf directory.
The conf Directory
The conf directory contains, in addition to other files, the access.conf and srm.conf files. Understanding these files helps you understand the limitations (or lack of limitations) placed on your CGI programs. Both these files are covered in more detail in Chapter 12, "Guarding Your Server Against Unwanted Guests." This introduction is only intended to familiarize you with their purposes and general layouts.
The access.conf file is used to define per-directory access control for the entire document root. Any changes to this file require the server to be restarted in order for the changes to take effect. Each of the file's command sets is contained within a
<DIRECTORY directory_path> ... </DIRECTORY>
command. Each
<DIRECTORY directory_path > ... </DIRECTORY>
command affects all the files and subdirectories for a single directory tree, defined by the directory_path. Remember that a directory tree is just a starting path to a directory and all the directories below that directory.
The srm.conf file controls the server after it has started up. Inside this file, you will find the path to the document root and an alias command telling the server where to hunt for CGI scripts. The srm.conf file is used to enable SSI commands and to tell the server about new file extensions that aren't part of the basic MIME types. One file type that you should be particularly interested in is the x-parsed-html-type file type, which tells the server which files to look in for the SSI commands.
This brief introduction to your configuration files should just whet your appetite for the many things you can learn by understanding how your server configuration files work.
The Document Root
You normally will be working in a directory tree called the document root. The document root is the area where you put your HTML files for access by your Web clients. This probably will be some subdirectory of your user account. On my server, the document root for each user account is public-web. Users who want to create public Web pages must place those Web pages in the public-web subdirectory below their home directory. You can create as many subdirectories below the public-web directory as you want. Any subdirectory below the public-web directory is part of the document root tree.
How do you find out what the document root is? It is easy, even if you aren't a privileged user. Just install the HTML Print Environment Variables program or the Mail Environment Variables program (described in Chapter 6), and you will see right away what the document root directories are on your server. To find out what the server root is, you need to contact your Webmaster or System Administrator.
File Privileges, Permissions, and Protection
After you figure out where to put your HTML, SSI commands, and CGI files, the next thing you need to learn is how to enable them so that they can be used by the WWW server.
When you create a file, the file is given a default protection mask set up by one of your login files. This normally is done by a command called umask. Before you learn how to use the umask command, you should learn a bit about file-protection masks.
File protections also are referred to as file permissions. The file permissions tell the server who has access to your file and whether the file is a simple text file or an executable program. There are three main types of files: directories, text files, and executable files. Because you will be using Perl as your scripting language, your executable CGI programs will be both text and executable files. Directory files are special text files that are executable by the server. These files contain special directives to the server describing to the server where a group of files is located.
Each of these file types has three sets of permissions. The permissions are Read, Write, and Execute. The Read permission allows the file to be opened for reading, but it cannot be modified. The Write permission allows the file to be modified but not opened for reading. The Execute permission is used both to allow program execution and directory listings. If anyone (including you) is going to be able to get a listing or move to a directory, the Execute permission on the directory file must be set. The Execute permission also must be set for any program you want the server to run for you. Regardless of the file extension or the contents of a file, if the Execute permission is not set, the server will not try to run or execute the file when the file is called.
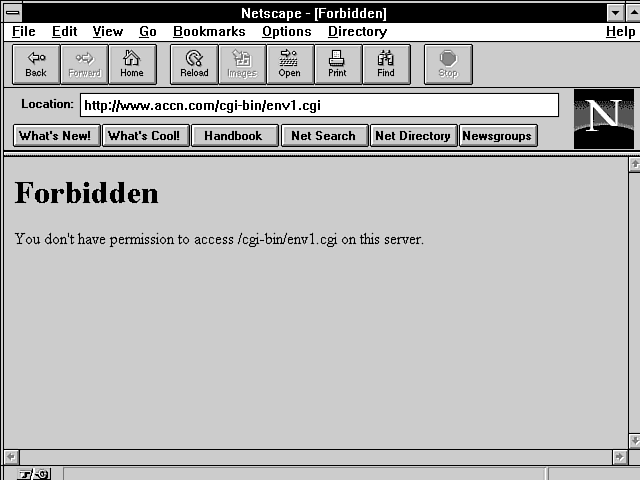
This is probably one of the most common reasons for CGI programs not working the first time. If you are using an interpretive language like Perl, you never run a compile and link command, so the system doesn't automatically change the file permissions to Execute. If you write a perfectly good Perl program and then try to run it from the command line, you might get an error message like Permission denied. If you test out your CGI program from your Web browser, however, you are likely to get an error like the one shown in Figure 1.1-an Internet file error with a status code of 403. This error code seems kind of ominous the first time you see it, and it really doesn't help you very much in figuring out what the problem is.
Figure 1.1 : The Forbidden error message.
Remember that there are three types of file permissions: Read, Write, and Execute. Each of these file permissions is applied at three separate access levels. These access levels define who can see your files based on their username and groupname.
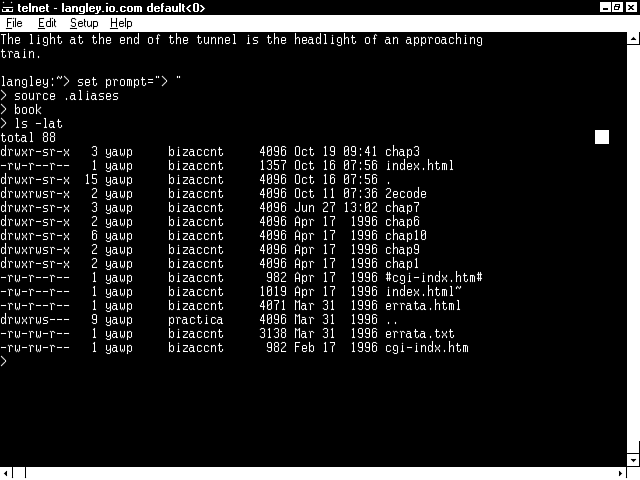
When you create a file, it is created with your username and your groupname as the owner and groupname of the file. The file's Read, Write, and Execute permissions are set for the owner, the group, and other (sometimes referred to as world). This is very important because your Web page is likely to be accessed by anybody in the world. Usually, your Web server runs as user Nobody. This means that when your CGI program is executed or your Web page is opened for reading a process with a groupname different than the groupname you belong to, someone else will be accessing your files. You must set your file-access permissions to allow your Web server access to your files. This usually means setting the Read and Execute privileges for the world or other group. Figure 1.2 shows a listing of the files in one of my business directories. You can see that most of the files have rw privileges for the owner and Read privileges only for everyone else. Notice that the owner is yawp (that's my personal user name) and the group is bizaccnt. You can see that directories start with a d, as in the drwxr-xr-x permissions set. The d is set automatically when you use the mkdir command.
Figure 1.2 : A directory listing showing file permissions.
In order for your Web page to be opened by anyone on the Net, it must be readable by anyone in the world. In order for your CGI program to be run by anyone on the Net, it must be executable by your Internet server. Therefore, you must set the permissions so that the server can read or execute your files, which usually means making your CGI programs world executable. You set your file permissions by using a command called chmod (change file mode). The chmod command accepts two parameters. The first parameter is the permissions mask. The second parameter is the file for which you want to change permissions. Only the owner of a file can change the file's permissions mask.
The permissions mask is a three-digit number; each digit of the number defines the permission for a different user of the file. The first digit defines the permissions for the owner. The second digit defines the permissions for the group. The third digit defines the permissions for everyone else-usually referred to as the world or other, as in other groups. Each digit works the same for each group of users: the owner, group, and world. What you set for one digit has no effect on the other two digits. Each digit is made up of the three Read, Write, and Execute permissions. The Read permission value is 4, the Write permission value is 2, and the Execute permission is 1. You add these three numbers together to get the permissions for a file. If you want a file to be only readable and not writable or executable, set its permission to 4. This works the same for Write and Execute. Executable only files have a permission of 1. If you want a file to have Read and Write permissions, add the Read and Write values together (4+2) and you get 6-the permissions setting for Read and Write. If you want the file to be Read, Write, and Execute, use the value 7, which is derived from adding the three permissions (4+2+1). Do this for each of the three permission groups and you get a valid chmod mask.
Suppose that you want your file to have Read, Write, and Execute permissions (4+2+1) for yourself; Read and Execute (4+1) for your group; and Execute only (1) for everyone else. You would set the file permissions to 751 by using this command:
chmod 751 (filename)
Table 1.1 shows several examples of setting file permissions.
| Command | Meaning |
| chmod 777 filename | The file is available for Read, Write, and Execute for the owner, group, and world. |
| Chmod 755 filename | The file is available for Read, Write, and Execute for the owner; and Read and Execute only for the group and world. |
| Chmod 644 filename | The file is available for Read and Write for the owner, and Read only for the group and world. |
| Chmod 666 filename | The file is available for Read and Write for the owner, group, and world. I wonder if the 666 number is just a coincidence. Anybody can create havoc with your files with this wide-open permissions mask. |
| Tip |
| If you want the world to be able to use files in a directory, but only if they know exactly what files they want, you can set the directory permission to Execute only. This means that intruders cannot do wild-card directory listings to see what type of files you have in a directory. But if someone knows what type of file he wants, he still can access that file by requesting it with a fully qualified name (no wildcards allowed). |
When you started this section, you were introduced to a command called umask, which sets the default file-creation permissions. You can have your umask set the default permission for your files by adding the umask command to your .login file. The umask command works inversely to the chmod command. The permissions mask it uses actually subtracts that permission when the file is created. Thus, umask stands for unmask. The default umask is 0, which means that all your files are created so that the owner, group, and world can read and write to your files, and all your directories can be read from and written to. A very common umask is 022. This umask removes the Write privilege for group and other users from all the files you create. Every file can be read and all directories are executable by anyone. Only you can change the contents of files or write new files to your directories, however.
WWW Servers
Now that you have a feel for how to move around the directories on your server, let's back up for a moment and examine the available servers on the Net. This guide definitely leans toward the UNIX world, but only because that is where all the action is right now. Because everything on the Net is changing so fast, moving out of the mainstream into a quieter world that may be more comfortable is a major risk. The problems of today will be solved or worked around tomorrow, and if your server isn't able to stay up with the rush, you will find yourself left behind. "What is your point?" you might ask. The comfort factor gained from working in a familiar environment might not be worth the risk of being left behind. When choosing one of the servers outlined in the next sections, make one of your selection criteria the server's capability to keep pace with the changes on the Net.
MS-Based Servers
Servers are available right now for Windows 3.1, Windows NT, and Windows 95. The Windows 3.1 server is available at
http://www.city.net/win-httpd/
This server is written by Robert Denny, who is also the author of the Windows NT and Windows 95 servers known as Website. The Website server is available at
http://website.ora.com
Each of these servers implements all or almost all of the major features of the ncSA httpd 1.3 server for UNIX. They are easy to configure, and the Windows NT/95 version uses a graphical user interface (GUI) for configuration. These servers have hooks to allow the server to work with other Microsoft products as well. Because they provide a familiar environment for many MS-based pc users, they might seem like a good system to choose.
If you choose an MS-based server, however, you definitely will be swimming out of the mainstream. The two most popular Web servers on the Net are the original Web server CERN, created by the European High Energy Physics Lab Group, and the ncSA httpd Web server, created by the National Center for Super Computing Applications. The CERN server was the first Web server-the starting point for the World Wide Web. It still is the test site for many of the experimental features being tried each day. Even though the CERN Web server is no longer the most popular server on the Net, it has one feature that you cannot get anywhere else right now. If you are trying to create a really secure site and you want to use a Web server as the proxy host, the CERN server is the way to go.
The CERN Server
The CERN server enables you to implement a firewall to protect your network from intruders while still allowing Internet WWW access from inside the firewall. Firewalls are great security barriers for preventing unwanted guests from getting into your secure network. A firewall typically works by allowing only a select set of trusted machines access to the network. A machine called a proxy is used to screen incoming and outgoing connections.
The problem with this setup is that it usually prevents machines on the inside of the firewall from accessing the WWW. If you set up the CERN server as a proxy server, however, your Web browser on the inside of the firewall can request WWW documents from the CERN proxy, and the CERN proxy forwards the request to the correct domain. When the domain server responds with the requested Web page, the CERN proxy passes the response to your browser. This lets your internal Net see the outside WWW while still providing the security of a firewall. As you would expect, this does slow down your access to Internet documents somewhat. Passing the information through the intermediary proxy server adds overhead and takes more time. If you don't need a proxy server, the most popular server on the Net by far is the ncSA server called httpd.
You can learn more about the CERN server at
http://www.w3.org/pub/www/daemon/overview.asp
The ncSA Server
The ncSA server usually is referred to by its version number. The current version of this server is the ncSA httpd 1.5.2 server. The 1.5.2 version of the ncSA server provides excellent execution speeds-sometimes equivalent to the commercial servers on the Net. The ncSA server provides support for SSI commands (something the CERN server does not provide) and security based on a general directory tree, per-directory access, or remote IP addresses. Because this server is by far the most popular server on the Net and most of its features are available on the other servers on the Net, this guide uses the ncSA server as the basis for most of the examples and descriptions. You can find more information about the ncSA httpd server at
http://hoohoo.ncsa.uiuc.edu/docs/Overview.asp
The Netscape Server
Finally, a brief mention of the commercial Netscape server. This server comes in two versions: the FastTrackserver and the Enterprise server. Both servers provide excellent speed and support for their users. The Netscape Enterprise server is designed for secure commerce over the Internet. You can get more information about the Netscape servers at
http://home.netscape.com/comprod/server_central/index.asp
For the most part, I will be dealing with the ncSA httpd server. This is the server that is setting the standard for the Net-if you can call a target moving at the speed of light a standard. But I would rather try to stay with this fast-moving target than get left behind during one of the most exciting rides of the decade.
The CGI Programming Paradigm
Probably the two most common questions about CGI programming are, "What is CGI programming?" and "Why is CGI programming different from other programming?" The first question is the harder question to answer and certainly is the combination of all the pages in this guide, but there is a short answer: CGI programming is writing applications that act as interface or gateway programs between the client browser, Web server, and a traditional programming application.
The second question, "Why is CGI programming different from other programming?" requires a longer answer. The answer really needs to be broken up into three parts. Each part describes a different section of the CGI program's environment, and it is the environment that the CGI program operates under that makes it so different from other programming paradigms. First, a CGI program must be especially concerned about security. Next, the CGI programmer must understand how data is passed to other programs and how it is returned. And finally, the CGI programmer must learn how to develop software in an environment where his program has no built-in mechanisms to enable it to remember what it did last.
CGI Programs and Security
Why does your CGI program have to be so concerned about security? Unfortunately, your main concern is hackers. Your CGI programs operate in a very insecure environment. By their nature, your programs must be usable by anyone in the world. Also by their nature, they can be executed at any time of the day. And, they can be run over and over again by people looking for security holes in your code. Because the Net is a place where anyone and everyone has the freedom to search, play, and explore to his heart's content, your programs are bound to be tested eventually by someone with at least an overabundance of curiosity. This means that you must spend extra time thinking about how your program could be broken by a hacker. In addition, because many applications are written in an interpretive language like Perl, your program source code is easier to access. If a hacker can get at your source code, your code is at much greater risk.
The Basic Data-Passing Methods of CGI
The way data is sent back and forth across the Internet is one of the most unique aspects of CGI programming. Gathering data and decoding data are the subjects of Chapters 4 and 5, respectively, but a brief introduction is warranted. Your CGI program cannot be designed without first understanding how data is built using the HTML hypertext link or the HTML Form fields. Both mechanisms create a unique environment in which data is encoded and passed based on both user input and statically defined data structures. When you design your CGI program, you first must design the user input format. This format is fixed in two data-passing mechanisms: the Get and Post methods. Both these methods use HTTP headers to communicate with your CGI program and to send your CGI program data. As you design your CGI program, you must be aware of the limitations of both these methods.
In addition, your CGI programs must be able to deal with the multiple input engines on the Internet, which have an impact on the format of the data your CGI program can return. Your CGI program can be called from all types of browsers-from the text-only Lynx program, the HTML 1.0-capable browsers, or the browsers like Netscape that include data (such as the cookie) that isn't even included in the HTTP specification. It is up to you to design your CGI program to deal with this multiplicity of client/browsers! Each will be sending different information to your CGI program, describing itself and its capabilities in the HTTP request headers discussed in Chapter 2.
After you have the data from these myriad sources, your CGI program must be able to figure out what to do with it. The data passed to your CGI program is encoded so that it will not conflict with the existing MIME protocols of the Internet. You will learn about decoding data in Chapter 5. After your CGI program decodes the data, it must decide how to return information to the calling program. Because not all browsers are created equal, your CGI program might want to return different information based on the browser software calling it. You will learn how to do this in the last part of Chapter 2.
CGI's Stateless Environment
The implementation of the HTTP stateless protocol has a profound effect on how you design your CGI programs. Each new action is performed without any knowledge of previous actions, and multiple copies of your CGI program can execute at the same time. This has a dramatic effect on how your program accesses files and data. Database programming alone can be complicated, but if you add parallel processing on top of it, you have an even more complicated problem.
Traditional programming paradigms use sequential logic to solve problems. The data you set up 100 lines of code ago is expected to be available when you need it to pass to a subroutine or write to a file. Usually, when you run one program in a traditional environment, it gets to run to completion without fear of another copy of itself modifying the same data.
Neither of these conditions is true for your CGI programs. If you are building a multipaged site where the information on one page can affect the actions of another page, you have a complication for which you must design. Unless you take special steps, what happened on Web page 12 is not available the next time Web page 12 or any other page in your site is accessed. Each new Web page access creates a brand new call to your CGI program. This means that your CGI program has to take special measures to keep track of what happened the last time. One common means is for your CGI program to save information from the last event into a file. That method still has limitations, however, because your program can be executed simultaneously by several clients. You need to know which client is calling you.
To get around these special problems, the HTML form-input type of Hidden was created. The Hidden Input type enables your program to return data in the called Web pages that aren't displayed to the Web client. When the client calls the next Web page on your site, the Hidden Input type is returned as data to your CGI program. This way, your CGI program has a chance to remember what happened last time.
This approach has at least one major problem. Hidden data is visible as soon as your Web client uses the View Source button on his browser. This means that he can change the data returned to your CGI program.
To complicate things even further, because your CGI program can be called from multiple browsers simultaneously, your program can be modifying a file at the same time another copy of the same program is modifying the same file. Unless you take special precautions to deal with this situation, some of your data is going to get lost. In the case in which two programs have the same file open, the program that closes the file last wins! The data saved by the earlier program is lost, overwritten by the changes made by the program that closed the file last. How do you solve this problem? You have to design a special database handle that locks the file for writing whenever any code in your CGI program has the file out for updating.
These are just the most obvious problems. It is your job as a CGI programmer to think about these potential problems and to come up with effective solutions.
One solution to the problem that hidden data is visible using the View Source button is the experimental HTTP header called a cookie. This cookie acts something like a hidden field, but it cannot be accessed by the user. Only your CGI program and the browser can see this field. This gives you a second and more secure means of keeping track of what is happening at your Web site. The HTTP cookie is discussed in Chapters 6 and 7.
Preventing the Most Common CGI Bugs
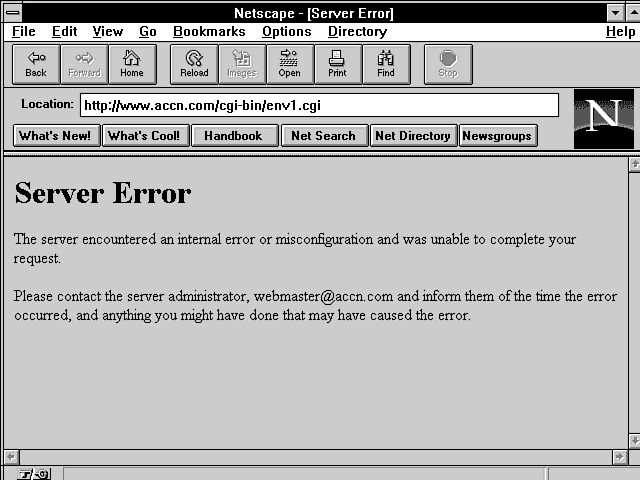
I suspect that you would prefer to just get your first CGI program working. If you can prevent the common CGI errors described in this section, you will be well on your way to getting your first CGI program working. What happens when you try to run your first CGI program and you see a Server Error (500) message such as the one shown in Figure 1.3?
Figure 1.3 : The Server Error message.
It seems like such an ominous error message. Drop everything and write your System Administrator a message describing exactly what you did to break the server. And what about the Forbidden (403) error message in Figure 1.1? Is the System Administrator going to cut off your programming privileges? DOES ANYONE KNOW? Can you just not tell anyone and it will go AWAY??!! Well, yes and no.
First of all, I suspect that you realize that all these error messages are generated automatically by your Web server, so nobody "knows" and, in most cases, nobody cares, but the error doesn't go away. Your Web server logs into an error log file every error it sees. This file is a marvelous source for figuring out what went wrong with your program. The error log file your server uses is probably in the server root document tree described earlier.
Usually, you will have read-only privileges for the files on the server root. This means that you can read what's in the error log files, but you can't change it. The error log files also are used by your System Administrator to watch for potential security risks on her server because each access to the system is logged into these files.
Tell the Server Your File Is Executable
There is one way to keep your programs from showing up in the
error log files: Never make any mistakes! Because I've never been
able to be successful with that advice, I've followed the more
practical advice of always (well, okay, almost always) executing
my CGI programs from the command line before trying to test them
from my Web browser. Just enter the filename of your program from
the prompt. If everything is okay, your CGI program executes as
expected and you should see the HTML your CGI program generated
on-screen.
| Tip |
| If you have an error, Perl usually is very good about helping you find what is wrong. Perl tells you the line where the error is located and suggests what it thinks the problem might be. I suggest fixing one or two errors at a time and then retrying your program from the command line. Quite often, one error contributes to and creates lots of other errors. That's why I suggest that you fix just a couple of bugs at a time. |
One of the first things you are likely to forget is to tell the system under which language to run your script. Setting the file extension to .pl doesn't do it. The thing that tells the system how to run your CGI program is the first line of a Perl script. The first line should look something like this:
#! /usr/local/bin/perl
The line must align flush with the left margin, and the path to the Perl interpreter must be correct. If you don't know where Perl is on your server, the following exercise will help you figure it out.
Finding Things on Your System
One way to figure out where stuff is on your system is to use the whereis command. From the command line, type whereis perl. The system searches for the command (perl) in all the normal system directories where commands can be found and returns to you the directory in which the Perl interpreter resides.
If this doesn't work for you, try typing the which command. Type which perl from the command line. The which command searches all the paths in your path variable and returns the first match for the command.
If neither of these methods works, try using the find command. Change directories to one of the top-level directories (starting at /usr/local, for example).
At the prompt cd /usr/local, type find . -name perl -print. This command searches all the directories under the current directory, looking for a file that matches the file in the -name switch end.
Make Your Program Executable
After you tell the system which interpreter to run and where it is, what next? Well, the next most common mistake is forgetting to set the file permissions correctly. Is your program executable? Even if everything else about the program is right, if you don't tell the server that your program is executable, it will never work! You might know that it's a program, but you're not supposed to keep it a secret from the server.
Enter ls -l at the command line. If you see the following message, you forgot to change the file permissions to executable:
-rw-rw-rw- program.name
Don't be too chagrined by this; I wouldn't mention it if it didn't happen all the time. It's really frustrating when you've been doing this for 10 years and you still forget to set the file permissions correctly. What's embarrassing, though, is asking someone why your program doesn't work, and the first thing she checks are your file permissions. The look you get from your Web guru when your file isn't executable just makes you want to go hide under a rock. Don't do this one to yourself; always check your file permission before asking someone else what is wrong with your program. Then set your program's file permissions to something reasonable like this:
> chmod 755 program.name
| Tip |
|
If you have a lot of output from your program and want to save it to a file so that you can study it a little easier, try this. From the command line, pipe the output from your program into a file by using the redirection symbol (>). Enter your program
like this:
program.name 2> output-filename All the program's output and its error messages will be sent to output-filename. |
If you've done all of this, you now are testing from your Web browser, and you still are getting one of those ominous server error messages, check for this common mistake: Make sure that your CGI program is printing a valid Content-Type response header and that the last response header your CGI program prints consists of two newline (\n) characters immediately after the response header.
Most of your CGI programs can use a print line just like this:
print "Content-Type: text/html\n\n";
The \n at the end of the HTTP response header prints a newline character. The server knows that your CGI program has sent its last response header when it finds a blank line after an HTTP response header. After that blank line, it is expecting to find the content type your program described in the Content-Type response header.
There is still one bug that usually bites the more experienced programmers more often than the inexperienced folks. The filename extension must be correct. We experienced (old) guys and gals know that the filename extensions don't really mean anything, so we are more likely to ignore the file-naming convention of filename.cgi for CGI programs. This is a big mistake! The Web server really does use that filename extension to determine what it is supposed to do with the file requested by the browser. So use the correct file extension! It's probably .cgi, but check the srm.conf file found below the server root directory in the configuration directory because it has the correct file extension. Look for something like this:
AddType application/x-httpd-cgi .cgi
You will save a great deal of debugging time if you always check these things first:
- Always check your file permissions; your CGI program should be executable.
- Always try your program first from the command line.
- Make sure that you are sending a blank line after your last response header.
- Make sure that the filename extension on your CGI program matches the one in the srm.conf file.
Learning Perl
Each "Learning Perl" section teaches you a new Perl fundamental. In this section, you'll work through a complete Perl programming example. It's just two lines of Perl so that you can concentrate on the things that make a program work. Lots of times, when you're working with a programming language, you miss the basics of making a program work because you get lost in the syntax of the programming language. Hello World is a simple and complete example of implementing a Perl program on your computer and moving it to your Internet service provider for testing.
Also in this section, you will be introduced to Perl's basic storage containers: variables. Variables are explained in a language that the non-programmer can understand. This section is rounded out with an exercise in using the first and simplest of Perl's storage containers: the scalar variable.
Hello World
Because your programs often act as interfaces to other, larger programs (such as databases), your gateway program's job is to interface between the larger programs and HTML. Your interface or gateway program performs this task by translating the incoming HTML data to database queries and the outgoing database results into HTML. Perl is an excellent tool for doing this type of data translation because it makes file, text, and other data manipulations easy.
Let's start with something simple. This program doesn't have any CGI in it-it's just straight Perl. Type the following code in your regular editor and then save it to a file named Hello.pl:
01: #!/usr/local/bin/perl 02: print "Hello World\n";
The first line of Hello.pl tells your computer where the Perl interpreter is located. You should change this line to the directory path where Perl is located on your computer. If you don't know where Perl is on your computer, you can find out by asking your System Administrator or by using one of the UNIX commands (whereis, which, or find), which are explained later in Exercise 1.1.
The second line of the program tells your computer to print to the screen Hello World.
In the next portion of this section, you will learn how to make the program print Hello World to your computer screen.
First, you must be logged onto a computer that has Perl on it. Telnet into your Internet service provider and, using FTP, copy the file from your computer to your user account's home directory. Alternatively, you can have Perl installed on the computer you normally use. In either case, after you are on a machine with Perl installed and you are in the same directory as your Hello.pl file, type the following:
perl Hello.pl
That's all there is to it. You can make this even simpler by making Hello.pl executable. Type the following:
> chmod 777 Hello.pl
Now just type this:
>Hello.pl
You should see the same Hello World
on your screen as before. If you don't see Hello
World, read on to get a better understanding of CGI
and UNIX. Don't forget the "Q&A" section at the
end of this chapter for some possible solutions if your Hello.pl
file does not work.
| Tip |
| When you copy files between UNIX and MS-Windows 95 or 3.1, set the FTP mode to ASCII. Usually, you transfer files in binary mode so that the computer doesn't change the file between two computers. But when moving text files between UNIX and Microsoft machines, you want the computer to modify the files. UNIX and Microsoft use different formats for defining the end of a line. If you transfer your HTML and Perl files using ASCII mode, the FTP transfer will format the end-of-line character(s) to the correct format for the receiving computer. |
The Hello World example showed you how easy it is to get Perl to work for you. Now you will learn how easy Perl makes it for you to work with and print data.
Exercise 1.1. Working with Perl variables
In this Perl exercise, you will learn how to use variable names in your Perl program. Variable names in programs are like different types of storage containers. My wife just got back from the container store with hundreds, thousands, millions of different types of boxes, racks, and containers to straighten out all our stuff. It was just too much for my feeble programming mind, and I ran screaming from the house. Well, not really, but she did buy lots of different styles of containers for storing our STUFF. Some programming languages are like that-they have lots of different storage containers, called variables, for storing your programming data. Sometimes that's helpful, but sometimes it's confusing. Perl takes the simple approach: it gives you three basic containers to store your data in-kind of like having only a shoe box, water can, and a file box to store all your household STUFF. This frustrates some and pleases others. For most of your programming tasks, you'll find Perl's three containers simple, understandable, and completely adequate.
Imagine for a moment that you were trying to use your shoe box,
water can, and file box for storing STUFF. You could put your
shoes into your watering can, and water your plants using your
file box, and lots of people use shoe boxes to store their important
papers, but it's usually a better idea to use storage containers
for their intended purpose.
| Tip |
One of the confusing yet powerful features of Perl is its capability to distinguish between variable names based on the beginning character of the variable. All variables in Perl begin with a dollar sign ($), at sign (@), or percent sign
(%). You also can use the ampersand (&) to begin subroutine calls. The asterisk (*) is a wildcard and refers to any variable. Definitions for these variables follow:
|
Exercise 1.2. Using the scalar variable
In this exercise, you'll learn about Perl's simplest variable: the scalar variable. It's kind of like the shoe box. You can use it effectively to hold all kinds of data, numbers (usually referred to as numeric data), and text (usually referred to as strings or character data). Listing 1.1 takes the Hello World example and personalizes it a bit.
Listing 1.1. Personalizing the Hello World example.
1: #!/usr/bin/local/perl 2: $first_name = "Eric"; 3: $middle_initial = "C"; 4: $last_name = "Herrmann"; 5: 6: print "Hello World\n"; 7: print "This program was written by "; 8: print "$first_name $middle_initial $last_name\n";
Now take a moment to examine this program. Lines 2-4 are called assignment statements. The data on the right-hand side of the equal sign (=) is stored in the variable on the left-hand side, just like a shoe box. A variable is created in Perl the first time something is stored in it. The variables in lines 2-4 are called scalar variables because only one thing can be stored in them at a time.
You can store two basic types of data in scalar variables: numbers
and text. As described earlier, text data usually is referred
to as strings or character data. Numbers, luckily,
are referred to as numbers or numeric data. Text
data should be surrounded by quotation marks (single quotes or
double quotes), as shown in lines 2-4. You learn about the mysteries
of the different types of quotation marks in Chapter 4. For the
moment, accept that your string data-the stuff you're going to
put into your shoe box-must have double quotation marks around
it.
| Note |
| When using quotation marks to store data, you must begin and end with the same types of quotation marks, and they always must be in matching pairs. The first quotation mark defines where the data to be stored starts, and the second quotation mark defines where the data to be stored stops. |
On line 8, the data you stored earlier is printed. This is just
a simple look inside the shoe box to show you that the data is
still there. Before you go on, take a close look at the variable
names in Listing 1.1. Perl is very sensitive about spelling and
uppercase versus lowercase letters. When dealing with variables,
$First_Name is not the same
shoe box as $first_name,
or any other mixing of upper- and lowercase letters. Think of
Perl's case sensitivity as different sizes on a shoe box. The
box looks similar, but what's inside is different.
| Tip |
|
You should establish a style of naming variables that you're comfortable with and then stick with that style. Different people like different styles, but the most important thing is to use the same style throughout your program. It makes your program
easier to read, and it makes your variables easier to find. Here are several styles that are common:
All uppercase: $FIRSTNAME
All lowercase: $firstname
Placing an underscore between words: $first_name, $FIRST_NAME, $First_Name Starting each word with an uppercase letter: $FirstName Pick a style that you like and use it consistently in your programs. It's a very simple thing you can do to help keep errors from creeping into your programs. |
Summary
I covered a lot of territory in this chapter, and a lot of it still might seem confusing. Don't worry-the purpose of this chapter is to get you thinking about the concepts of CGI programming. The remainder of this guide explains these concepts in detail. In this chapter, you learned that CGI programming is a lot more than just another programming language. It is really a programming paradigm-something that defines how you program and not what you program.
CGI programming is not a single language or application; it is making applications work in that wonderful WWW environment. In this chapter, you learned about the three main keys to your CGI program: HTML, HTTP, and your server. Each of these impacts how your program is structured to satisfy the needs of each application. You also learned about the structure of your server and where to find the different parts of your server directories.
Finally, you learned some of the common CGI programming mistakes to avoid as you begin to build your own CGI program applications.
Q&A
| Where should I put my CGI programs? | |
| Ultimately, your System Administrator or Webmaster has control over where you can install your CGI program. If you are on an ncSA server, you can create and run your CGI program from any directory. It's usually a good idea to keep your CGI programs in a common directory, however. That way, you can find a program when you need to modify it. A lot of systems create a single directory called the cgi-bin directory. If your server is set up this way, you might need to have your Webmaster install each CGI program you create. Because this is such a time-consuming process, however, you usually can be added to the groupname that has privileges to write to the cgi-bin directory. Check with your server's System Administrator. | |
| Are CGI programs only interface programs? | |
| There are absolutely no restrictions on what your CGI program can be. The only limitation on a CGI program is the requirement that it must understand the HTTP request/response headers and that it usually will be dealing with HTML in some manner. Frequently, CGI applications are small, quickly built programs that perform some simple task. As the Web grows more sophisticated, however, CGI applications will become larger and more complex. | |
| What is per-directory access? | |
| Each of the directories within your public-directory tree can be password protected. The access.conf file defines the overall structure of directory access, but you can add a similar file (usually called .htaccess) that creates special directory protection for the directory tree in which it is installed. You learn more about per-directory access in Chapter 12. | |
| How can I tell whether a variable exists? | |
| Perl provides a function called defined. The syntax for defined follows:
defined($variable); Defined returns True if the variable has data stored in it; False is returned if neither a valid string nor numeric data is stored in the variable. | |
| Couldn't I store my name in one scalar variable? | |
| Sure. Using multiple scalar variables for your name was just a convenience for Exercise 1.2. You could substitute the following for lines 2-4 of Exercise 1.2:
$name = "Eric C. Herrmann"; |


Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451




{kind=link}
{kind=link}
{kind=link}