Web based School



- 8
- SQL*Loader
- Introduction
- Basic SQL*Loader Components
- Physical Versus Logical Records
- Concatenated Records
- SQL*Loader Paths
- Parallel Data Loading
- Control File Syntax
- OPTIONS Clause
- UNRECOVERABLE/RECOVERABLE Clause
- LOAD DATA Clause
- INFILE Clause
- Table Loading Methods
- CONCATENATION Clause
- INTO TABLE Clause
- Figure 8.13. Column specifications.
- Command-Line Options and Parameter Files
- Summary
8
SQL*Loader
Introduction
One of the many challenges DBAs face today is the problem of migrating data from external sources into the Oracle database. This task has increased in complexity with the introduction of data warehousing; the demand has gone from migrating megabytes of
data to gigabytes, and in some cases, even terabytes. Oracle addresses this need with the SQL*Loader utility, a very versatile tool that loads external data into Oracle database tables. SQL*Loader is very flexible, and it is configurable to the point that
you often can avoid development of 3GL procedures with embedded SQL. Whenever you face the task of converting foreign data into the Oracle format, first consider the use of SQL*Loader before resorting to other alternatives.
The purpose of this chapter is to provide an overview of SQL*Loader's functionality, highlight its capabilities, describe commonly used syntax, and provide practical examples. For additional information and in-depth reference material, refer to the
Oracle7 Server Utility User's Guide.
Basic SQL*Loader Components
SQL*Loader requires two types of input: the external data, which can reside on disk or tape, and control information (contained in the control file), which describes the characteristics of the input data and the tables and columns to load.
The outputs, some of which are optional, include the Oracle table(s), log file, bad file(s) and discard file(s). Figure 8.1 illustrates the components.
Figure 8.1. SQL*Loader components.
The Input Data
SQL*Loader can process practically any type of data file, and it supports native data types for almost any platform. Data is usually read from one or more data files; however, data also may be embedded in the control file, after the control information.
The data file can exist as a fixed or variable format.
In fixed format, the data exists in fixed-length records that all have the same format. The fields for fixed-format files are defined by starting and ending positions within the record, and the fields contain the same data type and length
throughout the file. (see Figure 8.2.) Binary data must be in a fixed-format file, as SQL*Loader cannot handle it in a variable format.
Figure 8.2. Fixed-format records.
In variable-format files, the data exists in records that may vary in length, depending on the length of the data in the fields. The fields are only as long as necessary to contain the data. Fields in variable-format files may be separated by
termination characters (such as commas or white space), enclosed by delimiter characters (such as quotation marks), or both. (See Figure 8.3.)
Figure 8.3. Variable-format records.
Through the Oracle National Language Support (NLS), SQL*Loader has the capability to interpret and convert data with different character encoding schemes from other computer platforms and countries. For example, SQL*Loader can load an EBCDIC file into a
database on an ASCII platform, or it can load an Asian character-set file into an American character-set database.
The Control File
Before SQL*Loader can process the data in the data file(s), you must define the data specifications to SQL*Loader. You use the control file to define the physical data file specifications, as well as the format of the data in the file(s). The control
file is a free-format file that also contains additional control data, instructing SQL*Loader how to process the data. The details concerning the control file are described in a later section.
The Log File
Upon execution, SQL*Loader creates a log file containing detailed information about the load, including these items:
- Names of the input data file(s), control file, bad file(s), and discard file(s)
- Input data and associated table specifications
- SQL*Loader errors
- SQL*Loader results
- Summary statistics
See Figure 8.4 for a sample log file.
Discard and Bad Files
SQL*Loader has the built-in functionality, through specifications in the control file, to format the input data and include or exclude the input record based on record-selection criteria. If SQL*Loader includes the record for processing, it is passed to
the Oracle kernel for insertion into the database table. Figure 8.5 shows the record-filtering process.
Figure 8.5. Record-filtering process.
If SQL*Loader rejects the record due to a format error, or the Oracle kernel cannot insert the record into the database table(s) for any reason, the input record is written to the BAD file, in the same format as the original input data file. If
SQL*Loader rejects the record due to an exclusion based on the record-selection criteria, the input record is written to the DISCARD file (providing it was specified in the control file), also in the same format as the original input data file. Because
both the BAD and DISCARD files are written in the same format as the original input data file, they can be edited, if necessary, and used as input data files to another SQL*Loader session.
Physical Versus Logical Records
Physical records are the individual lines in the input data file as they were created by the operating system on the platform from which the file originated. Physical records are terminated by a record-terminator character (like a carriage
return). Logical records correspond to a row in a database table. A physical record can have a one-to-one association with a logical record. (See Figure 8.6.) SQL*Loader also enables you to create a many-to-one association between physical and
logical records through the use of the CONCATENATE or CONTINUEIF clause in the control file. You may create a one-to-many relationship by splitting one physical record into multiple logical records.
Figure 8.6. Physical versus logical records.
Concatenated Records
SQL*Loader can concatenate records either by specifying the number of physical records that form one logical record or by specifying conditional evaluations based on character occurrences within the data. If the number of physical records that comprise
a logical record varies, then you must base the concatenation on conditional evaluations. The CONCATENATE and CONTINUEIF clauses in the control file facilitate physical record concatenation.
SQL*Loader Paths
SQL*Loader provides two paths for loading data:
- The conventional path
- The direct path
The Conventional Path
The conventional path generates a SQL INSERT command with the array processing interface to load the data into the table(s). Because of this interface, SQL*Loader competes with all other Oracle processes for buffer cache resources; Oracle looks for and
tries to fill partially filled blocks on each insert. (See Figure 8.7.) If you are loading small amounts of data, this method is usually acceptable; however, with large volumes of data, this technique becomes too time consuming and resource-intensive.
Figure 8.7. Conventional loader path.
These conditions exist when you load data with the conventional path:
- Other users and Oracle processes can be accessing the table concurrently with SQL*Loader.
- Indexes are updated as the rows are inserted into the table.
- All referential and integrity constraints are enforced as the data is loaded into the table.
- Database Insert triggers fire as the rows are inserted into the table.
- You can apply SQL functions to the input data as it is being loaded.
- Data can be loaded into a clustered table.
- Data can be loaded with SQL*Net.
The Direct Path
In contrast to the conventional path, the direct path is optimized for bulk data loads. Instead of using the buffer cache to obtain and fill the database blocks, the direct path option uses the extent manager to get new extents and adjust the high water
mark. Direct path creates formatted database blocks and writes them directly to the database. (See Figure 8.8.)
Figure 8.8. Direct loader path.
The direct path has several significant advantages:
- You can load and index large amounts of data into empty or non-empty table(s) in a relatively short period of time.
- If loading data into empty tables, you can load presorted data and eliminate the sort and merge phases of the index build, thereby significantly increasing performance.
- You can load data in parallel, which enables multiple SQL*Loader sessions to perform concurrent direct path loads into the same table.
- You can specify that a direct path load be done in an UNRECOVERABLE mode, which bypasses Oracle's redo logging activity and significantly increases performance.
Although the direct path significantly increases performance, it does have some limitations:
- The table(s) and index(es) into which you are loading data are exclusively locked at the start of the load and not released until the load is finished; the table(s) cannot have any active transactions on them and are not available to other users or
processes until the load is completed.
- Indexes are put into a direct load state at the start of the load and need to be rebuilt, either automatically or manually, after the load is completed. If the SQL*Loader session does not complete successfully, the indexes are left in the direct load
state and need to be rebuilt manually. Any PRIMARY KEY or UNIQUE constraints are not validated until after the load is complete and the index rebuild occurs; you may have duplicate keys and need to correct them through the use of the exceptions table
before you can rebuild the index.
- The NOT NULL constraint is the only constraint checked at insertion time. All other integrity and referential constraints are re-enabled and enforced after the load is complete. If any violations exist, they are placed into the exceptions table, which
you should specify when you create the constraint. The exceptions table must be created before the load session.
- Database Insert triggers do not fire. Any application functionality that relies on them must be accomplished through some other method.
- You cannot apply SQL functions to the input data as it is being loaded.
- Data cannot be loaded into a clustered table.
- Only in the case where both computer systems belong to the same family, and both are using the same character set, can data be loaded through SQL*Net. You should not use SQL*Net for direct path loads, as the direct path should be used only for large
amounts of data. Network overhead offsets any performance gains associated with the direct path.
- DEFAULT column specifications are not available with the direct path.
- Synonyms that exist for the table(s) being loaded must point directly to the table; they cannot point to another synonym or view.
Parallel Data Loading
Oracle version 7.1 introduced the functionality of performing direct path loads in parallel. This feature gives SQL*Loader nearly linear performance gains on multi-processor systems. By using the parallel option, you can load multiple input files
concurrently into separate tablespace files, with each file belonging to the tablespace in which the table resides. Maximum throughput is achieved by striping the tablespace across different devices and placing the input files on separate devices, and
preferably separate controllers. (See Figure 8.9.)
Figure 8.9. Striping parallel loads.
When using the parallel option, SQL*Loader creates temporary segments, sized according to the NEXT storage parameter specified for the table, in the tablespace file specified in the OPTIONS clause of the control file.
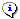 The specified file must be in the tablespace in which the table resides, or you get a fatal error.
The specified file must be in the tablespace in which the table resides, or you get a fatal error.
Upon completion of the SQL*Loader session, the temporary segments are merged (with the last extent trimmed of any free space) and added to the existing table in the database, above the high water mark for the table.
You should drop indexes, primary key constraints, and unique key constraints on the table before doing a parallel load. Oracle version 7.1 introduced parallel index creation, but you may use it only with a CREATE INDEX statement, not within an ALTER
TABLE CREATE CONSTRAINT statement. Therefore, the best method is to create the indexes first, using the parallel option, then create the primary key and unique constraints, which use the previously created indexes.
Your goal is to have concurrent SQL*Loader sessions each process an input file and place the output in a separate tablespace file, thereby maximizing throughput. Each SQL*Loader session creates one temporary segment, in its specified tablespace file, with the extent size being the size of the data file. When the session completes, SQL*Loader trims the excess space from the temporary extent (because it has only one extent) and adds it above the table's high water mark.
Using this method, you are evenly distributing the data across devices, thereby maximizing database I/O, minimizing the number of extents for the table, and maximizing SQL*Loader performance.
Control File Syntax
The control file is in free format; however, it does have a few rules:
- White space, carriage returns, tabs, and so on are allowed at any position in the file.
- As in Oracle, the contents of the file are case insensitive except for quoted (single or double) strings.
- You can include comments anywhere, except within the data(assuming the data is contained in the control file), by prefacing them with two hyphens; SQL*Loader ignores anything from the double hyphen to the end of the line.
- You may use reserved words for table or column names; however, the words must be enclosed in double quotation marks.
The control file is logically organized into seven sections:
- OPTIONS clause
- UNRECOVERABLE/RECOVERABLE clause
- LOAD DATA clause
- INFILE clause
- Table loading method
- CONCATENATION clause
- INTO TABLE clause
Listings 8.1, 8.2, and 8.3 help illustrate some of the syntax described in this section.
Listing 8.1 is a sample control file for a direct path parallel load using a fixed-format input file. This control file was used to test SQL*Loader results using the direct path parallel option in an unrecoverable mode. For illustration purposes only,
the SQL*Loader functions CONSTANT, SEQUENCE, SYSDATE, and RECNUM were used to populate column data.
OPTIONS (direct=true, parallel=true) UNRECOVERABLE LOAD DATA INFILE'/data01/ORACLE/TEST/fixed_data.dat' BADFILE'fixed_data.bad' DISCARDFILE'fixed_data.dis' INSERT INTO TABLE loader_test OPTIONS (FILE='data02/ORACLE/TEST/test1_TEST_01.dbf') (loader_constant CONSTANT "A" loader_sequence sequence (1,1), loader_sysdate sysdate, loader_recnum recnum, loader_desc POSITION (01:30) char loader_col1 POSITION (31:40) char, loader_col2 POSITION (41:50) char, loadr col3 POSITION (51:60) char, loader_col4 POSITION (61:70) char)
Listing 8.2 is a sample control file for a conventional path load using a variable-format file.
LOAD DATA
INFILE'data04/ORACLE/TEST/prod'
BADFILE'prod.bad'
INSERT INTO TABLE pord'
FIELDS TERMINATED BY','OPTIONALLY ENCLOSED BY ""
trailing nullcols
(
PROD_CODE,
PROD_DESCR,
PROD_CLASS,
PROD MKTG_CODE
terminated by whitespace)
Listing 8.3 is a sample control file for loading a binary EBCDIC file into a USASCII database, using the conventional path. Note that the file also is using packed decimal fields.
LOAD DATA CHARACTERSET WE8EBCDIC500
INFILE 'data01ORACLE/TEST/prod_detail'"FIX 28"
INSERT INTO TABLE prod_detail
(
PROD_CODE position(01:04) char,
SALES_MTD_LY position(05:10) decimal(11,2),
SALES_YTD_LY position(11:16) decimal(11,2),
SALES_MTD position(17:22) decimal(11,2),
SALES_YTD position(23:28) decimal(11,2)
)
OPTIONS Clause
The OPTIONS clause, which enables you to specify some of the run-time arguments in the control file rather than on the command line, is optional. This clause is particularly useful if the length of the command line exceeds the maximum command-line
length for your operating system. The arguments you can include in the OPTIONS clause are described in Table 8.1. Even if you specify the arguments in the OPTIONS clause, the command-line specifications override them.
Argument Description
|
SKIP = n |
Logical records to skip |
|
LOAD = n |
Logical records to load (default all) |
|
ERRORS = n |
Errors to allow before termination |
|
ROWS = n |
Rows in bind array (conventional); rows between saves (direct) |
|
BINDSIZE = n |
Size of bind array in bytes |
|
SILENT = {HEADER|FEEDBACK | |
|
ERROR|DISCARDS|ALL} |
Messages to suppress |
|
DIRECT = {TRUE|FALSE} |
Load path method |
|
PARALLEL = {TRUE|FALSE} |
Multiple concurrent sessions |
UNRECOVERABLE/RECOVERABLE Clause
These options apply only to direct path loads; all conventional loads are by definition recoverable. When the database is in archivelog mode, if RECOVERABLE is specified, the loaded data is written to the redo logs. Specifying UNRECOVERABLE bypasses
writing to the redo logs, which improves performance (by about 100%) but forces you to drop and re-create the loaded data if media recovery is required.
LOAD DATA Clause
The LOAD DATA clause is the main statement in the control file. Only comments, the OPTIONS clause, and the RECOVERABLE clause can precede LOAD DATA in the control file. LOAD DATA is followed by phrases and clauses that further qualify it. For the
complete syntax of the control file, refer to the Oracle7 Server Utilities User's Guide.
The LOAD DATA clause begins with the keyword LOAD, optionally followed by the keyword DATA. Note in Listing 8.3 that the keyword CHARACTERSET followed by the character set name is required if the input data file(s) is from a foreign character set, in
this case EBCDIC. The control file may have only one LOAD DATA clause.
INFILE Clause
To specify the input file containing the data to be loaded, specify the INFILE or INDDN keyword, followed by the filename and an optional O/S-dependent file-processing specifications string. Note in 8.4 that the string "FIX 28" follows the
complete file pathname for a UNIX system. Listing 8.4 contains some examples of file specifications from other platforms.
INFILE myfile.dat
INFILE 'c\\loader\\input\\march\\sales.dat'
INFILE '/clinical/a0004/data/clin0056.dat'
"recsize 80 buffers 10"
BADFILE '/clinical/a0004/logs/clin0056.bad'
DISCARDFILE '/clinical/a004/logs/clin0056.dsc'
DISCARDMAX 50
INFILE 'clin_a4:[data]clin0056.dat'
DISCARDFILE 'clin_a4:[log]clin0056.dsc'
DISCARDMAX 50
If the operating system uses a single backslash to specify an escape character, then use a double backslash in directory structures.
Filename specifications and the file-processing specifications string are generally not portable between platforms and may need to be rewritten if you are migrating to a different platform.
Following the INFILE statement is the optional bad file specification, which begins with the keyword BADFILE or BDDN followed by the filename. If no name is specified by the bad file, the name defaults to the name of the data file followed by a .BAD
extension. A bad file is created only if records were rejected because of formatting errors, or the Oracle kernel returned an error while trying to insert records into the database.
Following the BADFILE statement is the optional discard file specification, which begins with the keyword DISCARDFILE or DISCARDDN and is followed by the filename. Next comes a DISCARDS or DISCARDMAX keyword, with an integer specification. SQL*Loader
may create a discard file for records that do not meet any of the loading criteria specified in the WHEN clauses in the control file. If no discard file is named, and the DISCARDS and DISCARDMAX keywords are not specified, a discard file is not created
even if records were discarded. However, if the DISCARDS or DISCARDMAX keyword is specified on the command line or in the control file, with no discard filename specified, a default file is created with the name of the data file followed by a .DSC
extension.
The DISCARDS or DISCARDMAX clause limits the number of records to be discarded for each data file. If a limit is specified, processing for the associated data file stops when the limit is reached.
If the file is created, it overwrites any existing files with the same name.
If the file is not created, and a file with the same name already exists, it remains intact.
Table Loading Methods
The table loading method keyword specifies the default global method for loading the tables. You may use one of four methods:
- INSERT
- APPEND
- REPLACE
- TRUNCATE
INSERT is the default method and requires the table to be empty before loading the data file. SQL*Loader terminates with an error if the table is not empty.
APPEND adds new rows to the table, even if the table is empty.
REPLACE uses the SQL DELETE command to delete all rows from the table, performs a commit, then loads the new data into the table.
TRUNCATE uses the SQL TRUNCATE command to remove the rows from the table, performs a commit, then loads the new data into the table. All referential constraints must be disabled before the SQL*Loader session begins, otherwise SQL*Loader terminates with
an error.
When you use the REPLACE or TRUNCATE keyword, all rows are removed from the table before data begins loading into the table. If this result was not your intent, you may need to restore the table from a backup.
In addition to specifying a global table load method, you can specify a method for each table in the INTO TABLE clause.
CONCATENATION Clause
You can create one logical record from multiple physical records by using the CONCATENATE or the CONTINUEIF keyword.
If the number of records to combine remains constant throughout the data file, you can use the CONCATENATE keyword, followed by an integer, which indicates the number of records to combine. An example of CONCATENATE is shown in Figure 8.10.
Figure 8.10. An example of CONCATENATE.
If the number of physical records varies, then you must use the CONTINUEIF keyword, followed by a condition that is evaluated for each record as it is processed.
Examples of CONTINUEIF are shown in Figure 8.11.
Figure 8.11. Examples of CONTINUEIF.
In all three cases, with the THIS, NEXT, and LAST keywords, the condition is evaluated in the current physical record. If the condition is true, SQL*Loader reads the next physical record, concatenating it to the current physical record, continuing until
the condition is false. If the condition evaluates to false in the current physical record, then it becomes the last physical record of the current logical record.
The continuation fields are removed from the physical records before the logical record is created when you use the THIS and NEXT keywords.
The continuation character is not removed from the physical record when you use the LAST keyword; it remains a part of the logical record.
Any trailing blanks in the physical record are part of the logical record.
INTO TABLE Clause
The INTO TABLE clause is the section of the LOAD DATA statement that contains the bulk of the control file syntax. The INTO TABLE clause contains these items:
- Table name into which the data is to be loaded
- Table-specific loading method
- Table-specific OPTIONS clause
- WHEN clause
- FIELDS clause
- TRAILING NULLCOLS clause
- Index options
- Field conditions
- Relationship between data file fields and database columns
The INTO TABLE clause begins with the keywords INTO TABLE, followed by the name of the table into which the data is to be loaded. (You must have previously created the table.)
Table-Specific Loading Method
You may include a table-specific loading method in the INTO TABLE clause. If you use the INSERT, APPEND, REPLACE, or TRUNCATE method, it overrides the global table-loading method you specified previously in the control; the override is valid only for
the table referenced in the INTO TABLE clause.
Table-Specific OPTIONS Clause
You may include a table-specific OPTIONS clause in the INTO TABLE clause. The OPTIONS clause is valid only for parallel loads, and it overrides the FILE specification (the only option you can specify at the table level) in the global OPTIONS clause at
the beginning of the control file.
WHEN Clause
You specify record selection criteria through the use of a WHEN clause, which is followed by field condition(s). The WHEN clause can contain multiple comparisons; they must be separated by an AND. SQL*Loader determines the values of the fields in the
logical record, then evaluates the WHEN clause. The row is inserted only if the WHEN clause evaluates to true. Examples of usage of the WHEN clause are shown in Figure 8.12.
Figure 8.12. Examples of the WHEN clause.
FIELDS Clause
Fixed-format input data file fields are usually defined by explicit byte position notation, (start:end), whereas variable-format input data file fields are usually relative to each other and separated by field termination characters. You can define the
default field termination character for the file in the FIELDS clause. You can override the default at the field level by specifying the field termination character after the column name. An example of the usage of the FIELDS clause is shown in Listing
8.6.
INFO TABLE emp
WHEN empno > 1000
FIELDS TERMINATED BY WHITESPACE
TRAILING NULLCOLS
(
emp position(1) integer external terminated by '',
ename char terminated by whitespace,
deptno integer external terminated by ''
)
TRAILING NULLCOLS Clause
When more fields are specified in the control file than are present in the physical record, you must instruct SQL*Loader to either treat the missing fields as null columns or generate an error. When you use relative positioning, the record may end
before all the fields are found. The TRAILING NULLCOLS clause instructs SQL*Loader to treat any relatively positioned columns not present in the record as null columns. See the Listing 8.6 for usage of the TRAILING NULLCOLS clause.
Index Options
If you loaded the data using the direct path, and the data file has been presorted on indexed columns, you can specify the SORTED INDEXES clause, followed by the name(s) of the index(es) in parentheses. The index(es) listed in the SORTED INDEXES clause
must be created before you begin the direct load, or SQL*Loader returns an error. If you specify an index in the SORTED INDEXES clause, and the data was not properly sorted for that index, the index is left in the direct load state at the end of the load.
You must drop and recreate the index before you can use it.
Field Conditions
A field condition is an expression about a field in a logical record that evaluates to true or false. You use field conditions with the NULLIF and DEFAULTIF keywords, as well as the WHEN clause. NULLIF sets the column to null if the expression evaluates
to true, whereas DEFAULTIF sets the column to zero or blank. The BLANKS keyword enables you to easily compare any length field to determine if it is entirely blank. Examples of NULLIF and DEFAULTIF are shown in Listing 8.7.
dept no POISITION (1:2) integer external
NULLIF (dept = BLANKS)
comm POSITION (50:57) integer external
DEFAULTIF (hiredate > '01-jan-94')
Column Specifications
The data type specifications in the column specification of the control file tell SQL*Loader how to interpret the data in the data file. The column definition in the data dictionary defines the data type for each column in the database. The link between
the data in the data file and the database column is the column name specified in the control file.
Any number of a table's columns may be loaded, providing the unloaded columns were not created with NOT NULL constraints. Columns defined for the table, but not specified in the control file, are assigned null values when the row is inserted.
The column specification is the column name, followed by a specification for the value to be put into the column. The list of columns is enclosed by parentheses and separated by commas. Each column name must correspond to a column in the table that was
named in the INTO TABLE clause. Examples of column specifications are shown in Figure 8.13.
Figure 8.13. Column specifications.
Setting the Column Values
You can set the column value in one of two ways. The value can be read from the data file by specifying either an explicit position notation (start:end) for fixed-format files, or a relative position notation for variable-format files. The second way is
to generate the value using SQL*Loader functions CONSTANT, RECNUM, SYSDATE, or SEQUENCE. You can use these SQL*Loader functions for both the conventional path and the direct path. The syntax for the SQL*Loader functions is shown in Figure 8.14.
Figure 8.14. SQL*Loader functions.
The function CONSTANT, followed by a value, generates the fixed value for every row inserted into the table. SQL*Loader interprets the value as a character, but does convert it, if necessary, to the database column type. The value may be enclosed in
quotation marks.
The RECNUM function, which has no specified value associated with it, sets the column value to the number of the logical record from which the row was loaded. The records are counted sequentially from the beginning of the data file, beginning with
record 1. The value is incremented for each logical record, even if the record was discarded, skipped, or rejected. If you are using the parallel option to load multiple data files concurrently, each SQL*Loader session generates duplicate values, because
each session begins with 1.
The SYSDATE function gets the current system date for each array of records when using the conventional path, and for each block of records when using the direct path. The format of the date is the same as the SQL SYSDATE function. The database column
must be a type of VARCHAR, CHAR, or DATE.
The SEQUENCE SQL*Loader function (which is not the same as the database object SEQUENCE) increments, by the specified increment value specified, for each logical record that is loaded or rejected. This function does not increment for discarded or
skipped records. The starting value for the SEQUENCE, based on your specification, is:
- The specified integer
- COUNT, which is the number of rows in the table, plus the increment
- MAX, which is the current maximum value for the column, plus the increment
If you are using the parallel option, the SEQUENCE function is the only option available to you to in SQL*Loader to generate unique numbers; all other options require SQL functions, which you cannot use in a direct path load.
Specifying the Data Type
SQL*Loader extracts data from a field in the data file, according to the data type specification in the control file, and sends it to the RDBMS to be stored in the appropriate database column. The RDBMS automatically attempts to perform any data
conversion. If the data conversion cannot be done, an error is returned and the record is rejected.
Oracle interprets both character and binary (native) data. Character data is human-readable data you can produce in a text editor, whereas binary data is usually generated programatically. SQL*Loader supports these character types:
CHAR
DATE
NUMERIC EXTERNAL
SQL*Loader supports these binary (native) data types:
|
INTEGER |
ZONED |
|
SMALLINT |
VARCHAR |
|
FLOAT |
GRAPHIC |
|
DOUBLE |
GRAPHIC EXTERNAL |
|
BYTEINT |
VARGRAPHIC |
|
packed DECIMAL |
RAW |
Refer to the ORACLE7 Server Utility User's Guide for a complete description of the various character and binary data types that SQL*Loader supports.
Using SQL Functions
You may apply SQL functions to the field data by using a SQL string. The string may contain any combination of SQL expressions that return a single value. The string appears after any other specifications for a given column and must be enclosed in
double quotation marks. If the string contains a syntax error, the load terminates with an error. If the syntax in the string is correct but causes a database error, the row is rejected, but processing continues. You can reference field names in the SQL
string by prefacing them with a colon. Here are some examples of the usage of SQL functions.
my_field position(1:18) integer external
"TRANSLATE (RTRIM(my_field),'N/A','0')"
my_string CHAR terminated by ","
"SUBSTR (:my_string,1,10)"
my_number position(1:9) DECIMAL EXTERNAL(8)
":field/1000"
Multiple Table Statements
You have the ability with SQL*Loader to specify multiple INTO TABLE statements. Using multiple statements, you can perform these tasks:
- Extract multiple logical records from one physical record.
- Distinguish different record formats.
- Load data into different tables.
Listing 8.8 illustrates a case where you may want to use the values from different fields to populate a column, depending on conditions within the data.
Listing 8.8. Example of using field conditions to populate columns.
INFO TABLE proj
WHEN projno ! = ' '
(empo position(1:4) integer external,
projno position(29:31) integer external)
INFO TABLE proj
WHEN PROJNO ! = ' '
(empno position(1:4) integer external
projno position(33:35) integer external)
Listing 8.9 illustrates a case where you may want to use the same data within a physical record to load the data into multiple tables.
INFO TABLE dept
WHEN deptno < 100
(deptno POSITION(1:4) INTEGER EXTERNAL
(dname POSITION(6:19) CHAR)
INFO TABLE emp
WHEN empno > 1000
(empno POSITION(1:4) INTEGER EXTERNAL,
ename POSITION(6:15) CHAR.
deptno POSITION(17:18) INTEGER EXTERNAL)
Figure 8.15 illustrates a case where multiple tables are populated based on WHEN conditions.
Figure 8.15. Populating multiple tables based on WHEN conditions.
Command-Line Options and Parameter Files
The name of the SQL*Loader executable is operating-system dependent; refer to the Installation and Configuration Guide for your operating system to determine the executable filename.
By invoking SQL*Loader with no arguments, you see the following summary of the command-line arguments and their default values:
|
userid |
ORACLE username/password |
|
control |
Control file name |
|
log |
Log file name |
|
bad |
Bad file name |
|
data |
Data file name |
|
discard |
Discard file name |
|
discardmax |
Number of discards to allow (Default all) |
|
skip |
Number of logical records to skip (Default 0) |
|
load |
Number of logical records to load (Default all) |
|
errors |
Number of errors to allow (Default 50) |
|
rows |
Number of rows in conventional path bind array or between direct path data saves (Default: Conventional path 64, Direct path all) |
|
bindsize |
Size of conventional path bind array in bytes (Default 65536) |
|
silent |
Suppress messages during run (header,feedback,errors,discards) |
|
direct |
Use direct path (Default FALSE) |
|
parfile |
Parameter file: name of file that contains parameter specifications |
|
parallel |
Do parallel load (Default FALSE) |
|
file |
File from which to allocate extents |
For a complete description of the command-line arguments, refer to the Oracle7 Server Utility User's Guide.
You also can specify command-line arguments in the OPTIONS clause of the control file, or from a PARFILE, which makes arguments much easier to maintain. See Listing 8.10 for an example of using a PARFILE.
SQLLOAD parfile=weekly.par
WEEKLY.PAR
userid = scott/tiger
control = weekly.ctl
log = weekly.log
errors = 25
direct = true
Command-line arguments specified in the control file or a parfile still can be overridden from the command line.
Summary
You have probably noticed by now that SQL*Loader is a very robust utility. You can use SQL*Loader to load very small or very large amounts of data into an Oracle database. SQL*Loader supports a wide variety of external files and gives you a great deal of flexibility in loading your tables. With the parallel option, SQL*Loader is ready to support your data warehousing applications!
Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451



