Web based School



- 35 — File System Administration
- Formatting a Disk
- Preparing a File System
- Choosing a File System Type
- s5—The System V File System
- ufs—The UNIX File System (Formerly the Berkeley Fast File System)
- vxfs—The Veritas Extent-Based File System
- Choosing File System Parameters
- Making File Systems with newfs
- Making File Systems with mkfs
- The lost+found Directory
- Mounting File Systems
- Where to Mount
- How Permissions of the Underlying Mount Point Affect the Mounted File System
- Mounting a File System One Time
- Mounting a File System Every Time at Boot
- Unmounting a File System
- Checking File Systems
- The fsck Utility
- What Is a Clean (Stable) File System?
- Where Is fsck?
- When Should I Run fsck?
- How Do I Run fsck?
- What Do I Do After fsck Finishes?
- Dealing with What Is in lost+found
- Finding and Reclaiming Space
- What Takes Space
- Determining Who Is Using Up the Disk
- The System Administrator's Friend The find Utility
- Reorganizing the File System Hierarchy
- Summary
- From the top of the tree (/), showing each directory from the root to the file, called an absolute pathname
/usr/bin/cat
- From the current directory, going up or down the hierarchy to the file, called a relative pathname
bin/cat - File. A collection of bytes on the disk. Its characteristics are specified by the inode in the file system that describes it. Its name is specified by the directory entries that point to that inode. It has no structure but is just a collection
of bytes.
- Directory. A file with a special meaning overlaid on top of the collection of bytes. The contents of the file are a list of filenames and inode numbers. These are the files in this directory. Although there is a one-to-one mapping of inode to
disk blocks, there can be a many-to-one mapping from directory entry to inode. Thus, the directory contains the list of items in this directory, but those items might also appear in a different directory.
- Device. A device is a special type of inode entry. It describes a driver in the UNIX kernel. Using this entry, the system performs the I/O via the device driver. These types of entries are used to access the raw underlying disk drive. The UNIX
device driver makes a device pointed to by these entries appear as a stream of bytes, just like any other file.
- Link (Hard Link). A link is the name given to a directory entry. It links the directory entry to the inode that describes the actual item (file, device, and so on). This physical linking is a map directly to the inode, and the inode describes
space on this file system. Thus, the link can be a file only on this file system. Each file has one or more links. (When a file is removed from a directory, the link count is decremented. When it reaches zero, the inode and the disk space it points to are
freed, causing the data to be deleted.) The number of links to a given inode is shown in the ls -l output.
-
How UNIX Uses Disks
35 — File System Administration
35 — File System Administration
By Sidney Weinstein
In DOS, the primary division of file storage space is disk drives. These are further broken down into directories. UNIX uses a slightly different system that is also a bit more flexible. The primary division of file storage space is the file system.
File systems can be placed anywhere in the directory hierarchy, enabling the tree to be expanded wherever space is needed.
In DOS, a disk drive is divided into partitions, each of which is a logical drive letter. In UNIX, a disk drive is divided into slices, each one of which can be a file system. Both are dividing the disk into logical disks for use by their respective
operating systems.
This chapter walks you through adding, administering, checking, and backing up UNIX file systems. From a basic review of where UNIX places things, to how to install, configure, and use disk drives, you will see how UNIX deals with disk devices. The file
system section describes how to administer and maintain the files and free space. Finally, I cover protecting your data from destruction from hardware failure, software failure, and pilot error by performing regular backups using the backup tools built
into each UNIX system.
How UNIX Uses Disks
UNIX views all disks as a continuous hierarchy starting at /, the root. It doesn't matter whether they are on the same disk drive, of the same file system type, or even on the same computer. What makes this possible is the file system. Each file system
is independent of the others and allows UNIX to make them all look the same. Before I delve into creating and administering the disk space, some definitions and introduction are in order.
The Pathname
A UNIX file is addressed by its pathname. This is the collection of directories starting in one of two places:
Each element between the pathname delimiters (/) is a directory, and the last element is the item being addressed, which in this case is a file.
Some Definitions
I created a directory, t, and made three empty directories underneath it to show how UNIX makes use of links to tie the file system hierarchy together. The empty directories are a, b, and c. Here is an ls -liR output of the tree, starting at t:
total 40
23 drwxr-xr-x 5 syd users 91 Feb 26 10:18 .
2 drwxrwxrwx 5 root root 408 Feb 26 10:18 ..
27 drwxr-xr-x 2 syd users 37 Feb 26 10:18 a
31 drwxr-xr-x 2 syd users 37 Feb 26 10:18 b
33 drwxr-xr-x 2 syd users 37 Feb 26 10:18 c
./a:
total 16
27 drwxr-xr-x 2 syd users 37 Feb 26 10:18 .
23 drwxr-xr-x 5 syd users 91 Feb 26 10:18 ..
./b:
total 16
31 drwxr-xr-x 2 syd users 37 Feb 26 10:18 .
23 drwxr-xr-x 5 syd users 91 Feb 26 10:18 ..
./c:
total 16
33 drwxr-xr-x 2 syd users 37 Feb 26 10:18 .
23 drwxr-xr-x 5 syd users 91 Feb 26 10:18 ..
The first number on each line is the inode number, followed by the permission mask. The next number is the hard link count. This is the number of times that this inode appears in a directory entry. The last column is the filename (remember, directories
are just files with special characteristics). The file . is the current directory, which is pointed to by inode 23. The file .. is the parent of this directory, and for the directory t, it is inode 2, the root of this file system. Notice how in directories
a, b, and c, the .. entries are also inode 23. By mapping the name .. to the same inode as the parent directory, UNIX has built the reverse link in the file system. This listing shows four entries with the inode number 23, yet the link count on each is 5.
The fifth link is the entry in the root directory for t, this directory itself.
23 drwxr-xr-x 5 syd users 91 Feb 26 10:18 t
- Symlink (Soft Link). A symlink or symbolic link is a file whose contents are treated as a pathname. This pathname is used whenever the symlink is referenced. Because it is just a pathname (relative or absolute), it can cross file system
boundaries. Unlike links, creating a symlink does not require the existence of the file it points to, and removing the symlink does not remove the file. It is merely a pointer to the file to be used whenever this symlink is referenced.
- Mount Point. This is the directory entry in the file system hierarchy where the root directory of a different file system is overlaid over the directory entry. UNIX keeps track of mount points and accesses the root directory of the mounted file
system instead of the underlying directory. A file system can be mounted at any point in the hierarchy, and any type of file system can be mounted—it doesn't have to be the same type as its parent.
- Inode. This is the building block of the UNIX file system. Each file system contains an array of inodes. They contain a complete description of the directory entry, including the following:
mode Permission mask and type of file. The bit mask in this field defines whether the file is an ordinary file, directory, device, symlink, or other special type of entry. It also describes the permissions. This is the field that is decoded into the drwxr-xr-x string by the ls command.
link count The number of links to this file (the number of directories that contain an entry with this inode number).
user ID User ID of the owner of the file.
group ID Group ID of the owner of the file, used to map the group access permissions in mode.
size Number of bytes in the file.
access time Time (in UNIX time format) that the file was last accessed.
mod time Time (in UNIX time format) that the file was last modified.
inode time Time (in UNIX time format) that the inode entry was last modified. This does not include changes to the size or time fields.
block list A list of the disk block numbers of the first few blocks in the file. Only the first few (10—12, it varies depending on file system type) are kept directly in the inode.
indirect list A list of the disk block numbers holding the single, double, and triple indirect blocks.
Figure 35.1. ufs disk allocation block layout.
|
no indirects |
12´8192 = 96 KB or 98,304 bytes |
|
only single |
no indirect + 2048´8192 = 16,480 KB or 16,875,520 bytes |
|
only double |
single indirect + 2048´2048´8192 = 32,784 MB or 34,376,613,888 bytes |
|
with triple |
double indirect + 2048´2048´2048´8192 = 67,141,648 MB or 70,403,120,791,552 bytes (if you could find a disk that large) |
In UNIX, the inode, not the directory entry, contains all the information about the file. The only information in the directory is the filename and its inode number. This indirection from the filename to inode entry is what allows for links.
- Super-block. The controlling block of a file system. It contains the information about the file system and the heads of several lists, including the inode list, the free inode list, and the free block list. This block is cached in memory for all
mounted file systems and is periodically also written to the disk.
The System V Release 4 File System Layout
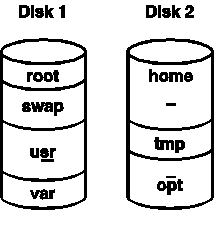
As installed in Chapter 33, the files in a UNIX installation are split into several file systems. One typical layout is shown in Figure 35.2.
Figure 35.2. Typical UNIX System V Release 4 file system layout.
Formatting a Disk
Adding a disk to a UNIX system requires the following three steps:
- Low level formatting—Writing the sector addresses to the disk
- Labeling—Writing the slice information to the disk
- Making file systems—Writing the file system header information to a slice
The first two are covered in this section and making file systems is covered in the next section.
Low-Level Format
Before any operating system can use a disk, it must be initialized. This low-level format writes the head, track, and sector numbers in a sector preamble and a checksum in the postamble to every sector on the disk. At the same time, any sectors that are
unusable due to flaws in the disk surface are so marked and, depending on the disk format, an alternate sector might be mapped in place to replace the flawed sector.
Low-level disk formatting is performed differently for the three types of disk drives used by UNIX systems.
Formatting ESDI, MFM, or SMD Drives
UNIX cannot format these drives while it is running. Instead, a stand-alone format program is used. It is usually provided by the manufacturer of the computer or the disk controller board. On PC hardware, this formatter runs either in 'Debug' mode
(before the operating system is loaded) or as an MS-DOS utility. Follow the manufacturer's directions for formatting these drives and be sure to have the drive mark the flawed sectors into the flaw map. UNIX will make use of this flaw map when creating its
alternate track list.
IDE
These drives are found on PC systems and extend the PC's ISA bus directly into the disk drive. They were designed to reduce the cost of MS-DOS PCs, and they come preformatted from the factory. Most format utilities are unable to low-level format these
drives.
SCSI
Most current UNIX systems are designed for SCSI disks. These disks come preformatted from the factory and normally do not need to be reformatted in the field. They also handle bad sector remapping internally. There is no reason to scan these disks for
flawed sectors.
If you do need to reformat these disks, you generally have three options:
- Use the UNIX vendor's format utility. Most workstation vendors include such a utility. SCSI disks do their own formatting when sent a format command. Just select the format menu option, and the SCSI disk will do the rest. Because the disk does its own
formatting, there is normally no progress indication. Low-level formatting can take from several minutes to an hour or so.
- Use a third-party disk management utility. These applications, such as SpeedStor for UNIX, provide a button on their window to directly format the SCSI disk.
- Use the disk controller's MS-DOS utility. For PCs, where most UNIX vendors have not provided a utility to format the disk, boot MS-DOS and use the disk controller vendor's format utility to format the disk.
Dealing with Flawed Sectors
As I mentioned, UNIX expects the disks to be flawless. However, this is rarely true. It is too expensive to build large disks with no flaws. By allowing for a relatively small number of flaws, the price of drives can be much lower. UNIX can deal with
flawed sectors in several ways:
- Alternate sectors per track. In this scheme, one or two sectors per track are reserved for use in remapping flawed sectors. If a sector is flawed, its sector ID is instead written to the mapped sector. This reduces the overall storage capacity of the
drive by some fixed percentage, to allow for flaws. This method has a problem if the track has more than the reserved number of bad sectors. This method is used mostly on SMD disks.
- Alternate tracks. In this scheme, several tracks are set aside, and whenever a track has a flawed sector, the operating system substitutes one of these tracks for the flawed track. Again, the storage space on all of the alternate tracks is lost. This
method has a problem in that a single flaw wastes an entire track.
- Letting the disk controller map out bad blocks. In this scheme, the disk controller handles remapping the blocks, and the disk appears flawless. This is the method used by SCSI disks, where the disk controller is actually on the disk itself and the
controller in the computer is really a SCSI bus controller.
Factory Flaw Map
In either of the first two cases, the factory performs tests on the disk and writes to a special location on the disk the list of sectors found to be flawed or weak. This is referred to as the factory flaw map. Every sector on this map should be entered
as flawed, even if it passes the UNIX bad sector test. This is because some of them might be weak and intermittently change over time. SCSI disks automatically access the factory flaw map when they perform their internal format. For non-SCSI disks, you
will either access the factory flaw map with the formatting utility or enter it by hand from a table that is either attached to the top of the drive or enclosed with it when it is shipped.
Newly Developed Flaws After Formatting
Disk sectors can also go bad for several reasons after formatting. Sometimes there is a hardware problem and the formatting information for that sector is ruined. Other times the sector was weak to begin with or gets physically damaged. Either way, the
disk is no longer flawless. This causes a problem because UNIX expects flawless disks.
You will see this problem when UNIX reports to the console log that it had an Unrecoverable Read or Unrecoverable Write error on a disk block. A warning about an upcoming problem would be a set of recoverable errors. You will need to map this block
number to an absolute disk block. UNIX reports the block number, starting with block 0 at the beginning of each logical device. To convert the block number to absolute, you need to add the starting block number to the number reported in the log. To perform
this conversion, you must meet the following requirements:
- logical disk starting sector = starting cylinder of the logical slice ´ number of heads ´ number of sectors/track
- logical disk starting block = logical disk starting sector / number of sectors per block
- absolute block = logical disk starting block + reported block number from error message
You will then need to repair or map the flawed sector.
Non-SCSI Disks
To repair a formatting problem, if your format utility allows it, just reformat the sectors that were damaged. Perform a nondestructive scan for unflawed defective sectors and reformat only those sectors.
If your format utility does not support repairing a single sector, you can flaw the sector, causing it to remap. Most formatting utilities provide an option to perform this automatically on the nondestructive scan.
Lastly, you can reformat the entire disk. Of course, this will lose all the data on the disk. You will have to re-install UNIX or restore from backup after this kind of repair.
SCSI Disks
Older SCSI disks required reformatting to add flaws. Newer disks fall into two categories:
- Automatic repair: Most newer SCSI disks automatically detect the problem and remap the sector on the fly. These generally do not even report a problem.
- Manual Repair: There is a SCSI command to ask the disk to repair the sector. This command is activated by the vendor's disk utility.
Your last resort is to reformat the entire disk. Of course, this will lose all the data on the disk. You will have to re-install UNIX or restore from backup after this kind of repair.
Labeling the Disk
Once the disk is formatted, it needs to have a special block, called the label, written to it. This block describes the geometry of the disk (heads, tracks, sectors) and how to split the disk into multiple logical disks (virtual table of contents).
On UNIX, it is often convenient to use multiple file systems. These provide protection from overruns and changes and can increase performance. However, it is expensive to place each file system on its own disk drive. Some are too small to warrant a
drive, and requiring eight or ten disk drives would be too expensive. UNIX works around this by splitting the disk into logical disks. The label records how the disk is split.
PC Partitions Versus UNIX Slices
On a PC-based system, to be compatible with DOS, disks 0 and 1 are first labeled with the DOS fdisk partition table. The UNIX partition is marked NON-DOS and active. The fdisk partition table can be written by the DOS utility fdisk, by the disk
controller vendor's formatting utility, or during the UNIX disk add sequence (by the UNIX command fdisk).
The UNIX label is not the same thing as the DOS fdisk partition table. Instead, it is written to the first block of the UNIX partition along with the UNIX boot block.
On non-PC systems, the label is written directly to the first block of the disk along with the UNIX boot block.
UNIX Slices
The virtual table of contents in the label is used to split the disk into 8 or 16 logical disks. (Some UNIX vendors allow for 8, some for 16—you don't make the choice yourself.) Once the system boots, each of these logical disks looks like a
complete disk to UNIX. By convention, one of the slices is used to refer to the entire physical disk drive, and the remaining slices are left for you to configure.
Configuring the Slices
When you installed the system (see Chapter 33), you were prompted to enter the configuration information for each slice. When adding a disk, you will have to do the same thing. SVR4 will walk you through this using the adddisk option of the System
Administrator shell (sysadm). Other systems require you to run a command to define the virtual table of contents (format on Solaris or SunOS, disksetup on Unixware).
Adding a Disk Using the Solaris format Command
By convention, disk drives on Solaris are set at SCSI target addresses 0—3. Targets 4 and 5 are for tape drives, and target 6 is for the CD-ROM drive. Configure the disk to an unused SCSI, target it, and add it to the SCSI chain. Then reboot the
system. Once booted, log in and become root. Then run the format command and select the new disk from the list of available disks, as follows:
# format
Searching for disks...done
AVAILABLE DISK SELECTIONS:
0. c0t1d0 <SUN1.05 cyl 2036 alt 2 hd 14 sec 72>
/iommu@f,e0000000/sbus@f,e0001000/espdma@f,400000/esp@f,800000/sd@1,0
1. c0t2d0 <DEC DSP5350 cyl 2343 alt 2 hd 25 sec 119>
/iommu@f,e0000000/sbus@f,e0001000/espdma@f,400000/esp@f,800000/sd@2,0
2. c0t3d0 <SUN1.05 cyl 2036 alt 2 hd 14 sec 72>
/iommu@f,e0000000/sbus@f,e0001000/espdma@f,400000/esp@f,800000/sd@3,0
Specify disk (enter its number): 0
selecting c0t1d0
[disk formatted]
FORMAT MENU:
disk - select a disk
type - select (define) a disk type
partition - select (define) a partition table
current - describe the current disk
format - format and analyze the disk
repair - repair a defective sector
label - write label to the disk
analyze - surface analysis
defect - defect list management
backup - search for backup labels
verify - read and display labels
save - save new disk/partition definitions
inquiry - show vendor, product and revision
volname - set 8-character volume name
quit
If the disk is already labeled, its label type will be show on the selection list. Otherwise, the disk will be shown with the type unknown.
format> type
AVAILABLE DRIVE TYPES:
0. Auto configure
1. Quantum ProDrive 80S
2. Quantum ProDrive 105S
3. CDC Wren IV 94171-344
. . .
16. other
Specify disk type (enter its number)[12]: 16
Enter number of data cylinders: 2034
The number of data cylinders is set to the number of cylinders minus the number of alternate cylinders for bad block mapping. The default number of cylinders for bad block mapping in Solaris is 2, so set this to the number of cylinders reported by the
drive minus 2 cylinders.
Enter number of alternate cylinders[2]: Enter number of physical cylinders[2036]: Enter number of heads: 14 Enter physical number of heads[default]: Enter number of data sectors/track: 72 Enter number of physical sectors/track[default]: Enter rpm of drive[3600]: Enter format time[default]: Enter cylinder skew[default]: Enter track skew[default]: Enter tracks per zone[default]: Enter alternate tracks[default]: Enter alternate sectors[default]: Enter cache control[default]: Enter prefetch threshold[default]: Enter minimum prefetch[default]: Enter maximum prefetch[default]: Enter disk type name (remember quotes): "New Disk Type"
Assign the drive a name that matches the manufacturer and model of the drive. Use the other drive names shown in the selection list as examples. It is best to take the default values for the SCSI parameters—the system will fetch them from the SCSI
pages in the drive.
Next you have to define the slices (partitions). This is performed from the partition menu, as follows:
format> par
PARTITION MENU:
0 - change '0' partition
1 - change '1' partition
2 - change '2' partition
3 - change '3' partition
4 - change '4' partition
5 - change '5' partition
6 - change '6' partition
7 - change '7' partition
select - select a predefined table
modify - modify a predefined partition table
name - name the current table
print - display the current table
label - write partition map and label to the disk
quit
Partition 2 is the Sun convention for the entire disk. The remaining partitions on a non-boot disk can be used for any section of the disk.
partition> 0
Part Tag Flag Cylinders Size Blocks
0 unassigned wm 0 0 (0/0/0)
Enter partition id tag[unassigned]: ?
Expecting one of the following: (abbreviations ok):
unassigned boot root swap
usr backup var home
If you are unsure of an answer, you can type ?, and the system will prompt you for the choices. The types of partition IDs are as follows:
|
unassigned |
This partition entry will not be used; the starting cylinder and size should be 0 |
|
boot |
Stand-alone boot images |
|
backup |
The entire disk, used to back up the disk in image format |
|
root |
The root file system |
|
swap |
Swap partition |
|
var |
System partition for local data |
|
usr |
System partition for system files |
|
home |
Any partition for user files |
Enter partition id tag[unassigned]: home
Enter partition permission flags[wm]: ?
Expecting one of the following: (abbreviations ok):
wm - read-write, mountable
wu - read-write, unmountable
rm - read-only, mountable
ru - read-only, unmountable
Mountable partitions hold file systems; unmountable ones are for raw data, such as databases.
Enter partition permission flags[wm]: Enter new starting cyl[0]:
Although partitions can sometimes overlap, if they are to be used at the same time, they cannot overlap. Normally, set the starting cylinder for each new partition to the starting cylinder + the number of cylinders in the prior partition.
Enter partition size[0b, 0c, 0.00mb]: ? Expecting up to 2052288 blocks, 2036 cylinders, or 1002.09 megabytes Enter partition size[0b, 0c, 0.00mb]: 1024c
Repeat the prior step until all the partitions are completed. Then use the p (print) command to check that it is correct. No partitions should overlap, except where you intend to use one or the other of them. Of course, partition 2, being the entire
disk, will overlap everything.
When you are satisfied that the information is correct, label the disk
partition> label
and quit the format program.
Adding a Disk Using the Unixware disksetup Command
Configure the disk to an unused SCSI target that is higher than the target ID of the boot disk and add it to the SCSI chain. Then reboot the system. Unixware will detect the new device on boot and automatically create all the device entries. Once
booted, log in and become root. Then run the fdisk command to add a partition table to the new disk drive. The argument to fdisk is the raw device entry for slice 0 on the disk. This is determined by taking the string /dev/rdsk/ and entering the controller
and target numbers as cNtM. Slice 0 is always d0s0.
# fdisk /dev/rdsk/c0t1d0s0 The recommended default partitioning for your disk is: a 100% "UNIX System" partition. To select this, please type "y". To partition your disk differently, type "n" and the "fdisk" program will let you select other partitions. y
Unless you intend to place a DOS partition onto the drive, answer yes and let Unixware default the entire disk to UNIX. Then run disksetup, which takes the same argument as fdisk.
# disksetup -I /dev/rdsk/c0t1d0s0 Surface analysis of your disk is recommended but not required. Do you wish to skip surface analysis? (y/n) y
You will now be queried on the setup of your disk. After you have determined which slices will be created, you will be queried to designate the sizes of the various slices. How many slices/filesystems do you want created on the disk (1 - 13)? 2
Unixware supports 16 slices per disk. However, it reserves three of them for its own use to hold the boot track, the bad track map, and the alternate sector tracks.
Please enter the absolute pathname (e.g., /usr3) for slice/filesystem 1 (1 - 32 chars)? /opt
This is the mount point for the file system. Non-file-system partitions can have an identifier entered here to remind you of the usage of this partition, because it won't be used in a mount command.
Enter the filesystem type for this slice (vxfs,ufs,s5,sfs), type 'na' if no filesystem is needed, or press <ENTER> to use the default (vxfs): Specify the block size from the following list (1024, 2048, 4096, 8192), or press <ENTER> to use the first one: Should /opt be automatically mounted during a reboot? Type "no" to override auto-mount or press enter to enable the option: Please enter the absolute pathname (e.g., /usr3) for slice/filesystem 2 (1 - 32 chars)? /home
Enter the filesystem type for this slice (vxfs,ufs,s5,sfs), type 'na' if no filesystem is needed, or press <ENTER> to use the default (vxfs): Specify the block size from the following list (1024, 2048, 4096, 8192), or press <ENTER> to use the first one: Should /home be automatically mounted during a reboot? Type "no" to override auto-mount or press enter to enable the option: You will now specify the size in cylinders of each slice. (One megabyte of disk space is approximately 1 cylinder.) How many cylinders would you like for /opt (0 - 638)? Hit <ENTER> for 0 cylinders: 320 How many cylinders would you like for /home (0 - 318)? Hit <ENTER> for 0 cylinders: 318 You have specified the following disk configuration: A /opt filesystem with 320 cylinders (320.0 MB) A /home filesystem with 318 cylinders (318.0 MB) Is this allocation acceptable to you (y/n)? y Filesystems will now be created on the needed slices Creating the /opt filesystem on /dev/rdsk/c0t1d0s1 Allocated approximately 81888 inodes for this file system. Specify a new value or press <Enter> to use the default: WARNING: This file system will be able to support more than 65,536 files. Some older applications (written for UNIX System V Release 3.2 or before) may not work correctly on such a file system, even if fewer than 65,536 files are actually present. If you wish to run such applications (without recompiling them), you should restrict the maximum number of files that may be created to fewer than 65,536.
Your choices are: 1. Restrict this file system to fewer than 65,536 files. 2. Allow this file system to contain more than 65,536 files (not compatible with some older applications). Press '1' or '2' followed by 'ENTER': 2 Creating the /home filesystem on /dev/rdsk/c0t1d0s2 Allocated approximately 81376 inodes for this file system. Specify a new value or press <Enter> to use the default: WARNING: This file system will be able to support more than 65,536 files. Some older applications (written for UNIX System V Release 3.2 or before) may not work correctly on such a file system, even if fewer than 65,536 files are actually present. If you wish to run such applications (without recompiling them), you should restrict the maximum number of files that may be created to fewer than 65,536. Your choices are: 1. Restrict this file system to fewer than 65,536 files. 2. Allow this file system to contain more than 65,536 files (not compatible with some older applications). Press '1' or '2' followed by 'ENTER': 1
Other systems are similar to either the Solaris or Unixware examples.
Partition Uses
Partitions can be used for file systems or as raw data areas. Uses of raw data areas include the following:
- Swap space. Swap space can be split across several drives. This is normally done if the system grows and RAM is added, making more swap space necessary.
- Backup staging area. Perform your backups to disk and then copy them to tape at high speed after they complete. Then the backup is also available online for immediate access.
- Database devices. Many UNIX databases perform faster and more reliably if they do not have to use the UNIX file system cache.
Preparing a File System
Once the disk is partitioned and labeled with its slices, you are ready to make a file system. The Unixware disksetup utility combined this with the labeling step, but it allowed only the default values for most of the parameters, allowing you a choice
only of file system type and number of inodes. In addition, it does not help you build a file system after the disk is already labeled. For that you still have to use the traditional methods of building a file system.
UNIX supports several file system types, and each of them has several tuning options. The steps in preparing a file system follow:
- Choose the type of file system.
- Select the proper cluster size, block size, and number of inodes.
- Use mkfs or newfs to build the file system.
Choosing a File System Type
Of the many types of file systems supported under UNIX, the first three listed here are normally used:
- s5 The older System V file system. A low overhead file system useful for removable media.
- ufs The new name for the Berkeley Fast File System.
- vxfs The Veritas Extent-Based File System.
- pcfs MS-DOS FAT-based File System. Used to access DOS floppies and hard disk partitions. Although this file system type is compatible with DOS, it is not as robust as the UNIX formats and should be used only for exchange media with DOS systems.
- hsfs High Sierra File System. Used by ISO-9660 CD-ROMs. Often used with the Rock Ridge extensions to map UNIX filenaming conventions to the ISO-9660 standard layout.
- cfs Cached File System. A local storage area for caching an NFS file system. See Chapter 37 for further information on Network File Systems.
- bfs A very simplistic file system used to hold stand-alone boot images. It supports only contiguous files and is not intended for use beyond the system boot images.
- tmpfs A RAM-based file system used for the /tmp directory. It shares paging space with the swap partition. It is available on only a small number of UNIX systems.
s5—The System V File System
Before System V Release 4 adopted the ufs file system, this was the de facto standard for UNIX. It is a low overhead file system that supports only 14-character filenames and a restricted number of inodes (65536). In addition, it is prone to
fragmentation, which can slow down access to the disk. It is currently used when sharing removable media between older systems and current ones is desired, and for floppies where the overhead of ufs wastes too much space. Except for backward compatibility
uses, it should be limited to file systems of 2 MB or less.
ufs—The UNIX File System (Formerly the Berkeley Fast File System)
This file system is based on cylinder groups. It groups files together to reduce access times and reduce fragmentation. To achieve this, it extracts a 10—20 percent space overhead on the drive. It supports long filenames and is not restricted as to
the number of inodes. This is the default file system type on Solaris. The ufs file system is the only one that supports disk quotas, restricting the amount of disk space a user can use.
vxfs—The Veritas Extent-Based File System
s5 and ufs file systems rely on the full structural verification check in the fsck utility to recover from system failures. This takes several minutes per disk after a system crash. Normally not much is lost, usually just what was still in the file
system cache in RAM, but the delay on boot can be large. On a file server it can add over an hour to the boot time.
The vxfs file system provides recovery in seconds after a system failure by using a tracking feature called intent logging. The fsck utility scans this log and needs to check only those intents that were not yet completed. In addition, the vxfs uses
extent-based allocation to further reduce fragmentation.
The file system is going to consist of many small short-lived files.
You are going to have a set of files that will be growing, causing many extents to be needed.
You need to enforce quotas.
The file system is static and read-only.
Use an s5 file system in the following circumstances:
Backward compatibility is required.
The removable media is small and the overhead of vxfs and ufs use too much of the available space.
Choosing File System Parameters
Most of the time the default parameters chosen by disksetup or newfs are sufficient. This section will explain the meaning of these parameters in case you ever have to tune them. The most common ones to tune are
- Number of inodes
- Number of cylinders per group (ufs only)
Number of Inodes
Each file takes one inode. Each inode also takes space: 128 bytes. There is a trade-off between the number of inodes and the size of the partition. If your average file is many megabytes long, the default of 1 inode per 4 KB will generate many more
inodes than needed, wasting space on the file system. On the other hand, if the partition is full of small files, such as a USENET Network News partition, you might run out of inodes before you run out of space. If you know how many files to expect, you
can tune this parameter to wring more space out of the slice.
Block Size
For ufs file systems, this should be the same as the page size of the memory management system: either 4 KB or 8 KB. There is little reason to change this. However, if a disk will be moved between systems with 4 KB and 8 KB page sizes, it is best to use
4 KB for the partition. The larger the block size, the large the amount of data per I/O. However, small files will also need more fragmentation space.
For s5 file systems, this is both the I/O block size and the file allocation increment. If the media is small, consider making this 512 bytes to squeeze as much as you can on the disk. The default value is tuned more toward performance at 2 KB.
Expected Fragmentation/Fragment Size
On ufs file systems, the last block of the file is usually not full. Rather than wasting 4 KB or 8 KB for the last block, it places multiple fragments of files into one block. If you have a large number of very small files, make this parameter small to
avoid wasting so much space. It defaults to 1 KB but can be set as low as 512 bytes. The default of 1 KB is sufficient in almost all cases.
Cylinder Size
In ufs file systems, files are grouped together into cylinder groups to reduce seeks. A cylinder group consists of 1 to 32 cylinders. If you set it to 1 cylinder, the file systems do very little seeking while reading a single file. The trade-off is
space overhead. Each cylinder group has a set of structures including a backup copy of the super-block in case the main one gets damaged. Increasing the number of cylinders reduces overhead but also increases seeks. It is the classic trade-off of space
versus performance. The default of 16 is normally adequate. It is usually changed only to wring the last bit of space out of a file system.
Rotational Delay
To optimize disk performance, the system tries to slip the sector usage from cylinder to cylinder to compensate for the track-to-track seek time of the disk. By starting each cylinder on a different sector number, it can try to avoid a complete rotation
after a seek to an adjacent track. On modern SCSI disks, there is little or no correlation between block number and the actual layout of the disk. This is due to using a variable number of sectors per track to increase the storage capacity of the drive.
For SCSI disks, this parameter should be 0. For ESDI, MFM, and SMD disks, vary this parameter while writing a large file to try to achieve the optimum performance from the drive.
Making File Systems with newfs
So you have decided on an appropriate file system type for the slice and have determined approximately what order of magnitude of inodes will be required. Now it is time to actually make the file systems. This task is controlled by the newfs utility on
Solaris. newfs uses the information in the label to choose appropriate defaults for the file system.
# newfs -Nv /dev/rdsk/c0t3d0s7 /dev/rdsk/c0t3d0s7:
newfs reports the name of the partition you passed to it and its size from the label. It then passes the arguments to mkfs. Because it is computing all of the arguments, it passes them as a direct vector in a compact format. mkfs does allow a simpler
argument format if you have to run it yourself.
mkfs -F ufs -o N /dev/rdsk/c0t3d0s7 228816 72 14 8192 1024 16 10 90 2048 t 0 -1 8 -1
228816 sectors in 227 cylinders of 14 tracks, 72 sectors
111.7MB in 15 cyl groups (16 c/g, 7.88MB/g, 3776 i/g)
super-block backups (for fsck -F ufs -o b=#) at:
32, 16240, 32448, 48656, 64864, 81072, 97280, 113488, 129696,
145904, 162112, 178320, 194528, 210736, 226944,
See the next section on mkfs for the meaning of the output from mkfs.
Making File Systems with mkfs
Unixware does not use the newfs command; it was a Berkeley-derived command. It requires you to directly invoke mkfs. This isn't as bad as it seems because most of the parameters shown in the prior section on newfs would have been computed by default by
mkfs anyway.
Making ufs File Systems
The only required options to mkfs are the file system type, character special device name, and the size in sectors of the file system to be built. The remaining options will all default. However, these defaults do not come from the label. Running the
same partition through mkfs with default values yields the following:
# mkfs -F ufs -o N /dev/rdsk/c0t3d0s7 228816
Warning: 48 sector(s) in last cylinder unallocated
/dev/rdsk/c0t3d0s7:
228816 sectors in 447 cylinders of 16 tracks, 32 sectors
111.7MB in 28 cyl groups (16 c/g, 4.00MB/g, 1920 i/g)
Notice that it chose the default values of 16 tracks per cylinder (heads) and 32 sectors per track. To make the layout optimum for the disk, use the parameters nsect and ntrack.
# mkfs -F ufs -o N,nsect=72,ntrack=14 /dev/rdsk/c0t3d0s7 228816
/dev/rdsk/c0t3d0s7:
228816 sectors in 227 cylinders of 14 tracks, 72 sectors
111.7MB in 15 cyl groups (16 c/g, 7.88MB/g, 3776 i/g)
super-block backups (for fsck -F ufs -o b=#) at:
32, 16240, 32448, 48656, 64864, 81072, 97280, 113488, 129696,
145904, 162112, 178320, 194528, 210736, 226944,
This produces the same output as the newfs command.
As the caution states, one of the important pieces of output produced by mkfs is the list of backup super-blocks. If some disk error destroys or corrupts the primary super-block, the file system would be totally lost without backup copies. To avoid this
catastrophe, ufs file systems place backup copies of the super-block in every cylinder group header. The file system check utility, fsck, can use these backup copies to restore the master super-block and recover the file system if needed. The reason for
saving a paper copy is that if the master super-block is destroyed, it will not be possible to get the system to print out the block numbers of the backup super-block. Of course, one backup is always available at block number 32, but if you overwrite the
front of the disk slice, you will probably lose the primary super-block and that backup copy as well, so store the paper copy for safe keeping.
Making vxfs File Systems
The vxfs file system requires less tuning from the default values than ufs file systems. There is little reason to change the block size or allocation unit parameters. The only two parameters worth tuning are as follows:
- ninode. Number of inodes to allocate. vxfs file systems allow direct entry of the number of inodes. The default value is computed using the formula
ninode = number of sectors / (block size * 4)
The L option can be used to prevent being asked the question about having more than 65536 inodes. The C option can be used to force no more that 65536 inodes when the default formula is used.
- logsize. The number of blocks of size blocksize to use for the log region. Large, actively changing file systems might want to increase this parameter by a factor of 2 from its default value. For most file systems, the default value is sufficient.
The mkfs command for vxfs file systems reads
# mkfs -F vxfs -o N,L,ninode=128000 /dev/rdsk/c0t3d0s7 228816
The lost+found Directory
When you make a new file system, mkfs automatically creates a directory in it called lost+found. The lost+found directory is a placeholder. It is space that you set aside to hold pointers to inodes whose directory entries are corrupted. When the
file system checks utility, fsck runs and detects a problem with an inode; if it cannot patch up the directory entries pointing to that inode, it clears them and makes a new directory entry in the lost+found directory. Because it doesn't know the proper
name for the file, it calls it #inode-number.
Rather than lose the files entirely, when fsck detects some problems, it reconnects the inode into the lost+found directory. If this directory does not exist, fsck does not want to risk writing over blocks that might mistakenly be on the free list to
create it. Then the files would be lost instead of reconnected.
The name comes from those files that have been disconnected from all directories (lost) and still have data blocks allocated to them. They are found and returned to the lost+found department in that directory.
If the file is a directory, all of the files in the directory will still have their proper names. The owner of the directory can usually tell you what its name should have been. Then just remake the directory and move its contents back to where they
belong and delete the directory entry in lost+found. Although you could do a mvdir command to move the entry back where it belongs, remaking it will also reorder and compact the directory.
Mounting File Systems
You've now built the file system, but no one can use it until it is made part of the file hierarchy. This is called mounting the file system. The new file system is placed on top of an existing directory in the hierarchy and replaces that directory.
Thus file systems can be seamlessly grafted anywhere in the hierarchy.
Where to Mount
The first decision is where to place the new file system. Sometimes this decision is very simple. If you create a file system to hold the X11 utilities, the logical mount point is /usr/X. But if it is a general-purpose file system, to be shared by many
projects and users, where do you mount it?
A file system can be mounted anywhere in the hierarchy. However, it does hide the directory it replaces. Mounting a new file system at the root (/) would be useless because the entire system would then be hidden.
There is no single correct place to mount file systems. However, just using them to extend directories in the hierarchy that run out of space can needlessly fragment the hierarchy. Instead, consider placing several large file systems near the top of the
hierarchy, perhaps in the root directory, and then using symbolic links to link them into places in the hierarchy that need additional space. For example:
/home/users/john -> /files1/john
/home/users/tim -> /files1/tim
/home/users/bob -> /files2/bob
/proj/development -> /files2/development
In this example, two file systems are created and mounted as /files1 and /files2. Rather than mount them as /home/users or /proj, they are mounted in the root directory. Then symbolic links are created from the home/users and /proj directories to these
file systems as space is needed. This way, if development outgrew the space available on /files2, it could easily be moved to a new file system, /files3, just by copying the files and changing the symlink to
/proj/development -> /files3/development
Everyone would still refer to the files as /proj/development.
How Permissions of the Underlying Mount Point Affect the Mounted File System
Every directory on UNIX has a permission mask. This indicates who is allowed to create and remove files in the directory (the w bits), see which files are in the directory (the r bits), and use this directory as part of a pathname (the x bits). This is
just as true for the root directory of a file system. However, the UNIX system adds one more restriction. It ands the two permission bit masks. Thus, if the underlying mount point directory is
drwxrwxr-x (775)
allowing all access but file creation or destruction to the public, and the permissions of the root directory of the file system is
drwxrwx-wx (773)
allowing all access but seeing what files are in the directory to the public, the permission when mounted would be
drwxrwxr-x & drwxrwx-wx or (775 & 773) = drwxrwx—x (771)
This would allow the public to use this directory only in a search path and not create or destroy files or see what is in the directory.
Mounting a File System One Time
You decided where to mount it, created the mount point's directory if it didn't already exist, and are now ready to mount the file system. It is time to use the mount command. There are two ways to use mount: one specifies everything, the other uses the
file /etc/vfstab to determine how to mount the file system.
- Doing the mount manually
If you are just checking the mount point, or mounting a file system in a different place temporarily, perhaps to copy the files to a new disk, you enter three parameters to the mount command: type of file system, block special device of the slice, and the mount point
mount -F vxfs /dev/dsk/c0t3d0s7 /opt
If you wish only to look and want to prevent changes to the file system, you can mount it in read-only mode by adding an -r option
mount -F vxfs -r /dev/dsk/c0t3d0s7 /opt - Using /etc/vfstab
If the file system is already defined in /etc/vfstab, then the mount command can be shortened to just the mount point.
mount /opt
Likewise, for read-only mounting it would be
mount -r /opt
To add a manually mounted file system to /etc/vfstab, see the next section, but set the mount at boot time column to no.
Mounting a File System Every Time at Boot
The system will mount at boot time all file systems specified in the virtual file system table, or /etc/vfstab. This file specifies all the parameters it needs for mounting local and remote file systems. (See Chapter 37 for more information on remote
file systems.) The file is just a text file and can be edited with any text editor. The Unixware command disksetup automatically adds the slices it creates to this file if you specify boot time mounting.
The file consists of seven columns of data separated by white space (usually tabs).
#device device mount FS fsck mount mount #to mount to fsck point type pass at boot options # /dev/dsk/c0t3d0s0 /dev/rdsk/c0t3d0s0 / ufs 1 no - /dev/dsk/c0t3d0s6 /dev/rdsk/c0t3d0s6 /usr ufs 2 no - /dev/dsk/c0t3d0s7 /dev/rdsk/c0t3d0s7 /var ufs 4 no - /dev/dsk/c0t2d0s6 /dev/rdsk/c0t2d0s6 /files ufs 5 yes - /dev/dsk/c0t2d0s7 /dev/rdsk/c0t2d0s7 /files4 ufs 6 yes - /dev/dsk/c0t1d0s2 /dev/rdsk/c0t1d0s2 /opt ufs 11 yes - /dev/dsk/c0t3d0s5 /dev/rdsk/c0t3d0s5 /usr/openwin ufs 12 yes - /dev/dsk/c0t3d0s1 - - swap - no -
The preceding comment lines explain pretty well all of the columns except fsck pass and mount options.
fsck pass is designed for allowing fsck to run on multiple disk drives in parallel. The fsck passes are executed in order, and any file systems with the same pass number are allowed to be executed in parallel.
Running in parallel might not be any faster if the SCSI channel is close to saturation or the system does not have enough RAM to buffer all the structures. It can cause slowdowns as it pages the structures out to swap space on the disk.
Mount options are passed to the mount command as part of the -o option and are entered here exactly as they would be entered in the -o option list of the mount command. Mark read-only file systems as ro, not -r, because the -o flag for read-only is -o
ro.
Unmounting a File System
A file system must be unmounted to check it, and if it is a removable media, it must be unmounted before it is removed. The umount command is used to unmount file systems, as in
umount /opt
No options are needed on the umount command.
/opt: busy
back from the umount command, it means that some processes are still using the file system. The first thing to check is that you don't have your current directory set to somewhere within that file system. If you do, change back to the root file system and try again. If it still reports as busy, use the fuser command to determine which processes are still using the file system.
# fuser -cu /opt
/opt: 1189t(syd) 1105t(syd) 871to(syd) 838t(syd)
229to(root) 164t(root)
The number is the process ID that is using the file system; the letter is as follows:
c—has a current directory on the file system
o—has an open file on the file system
r—has its root directory on the file system
t—has a program running from the file system (needs access to the file system to handle page faults)
The name in parentheses is the owner of the process.
If necessary, you can then send the kill signal to any processes that are using the file system to get it unmounted.
Checking File Systems
Sooner or later it happens. Someone turns off the power switch. The power outage lasts longer than your UPS's batteries and you didn't shut down the system. Someone presses the reset button. Someone overwrites part of your disk. A critical sector on the
disk develops a flaw. If you run UNIX long enough, eventually a halt occurs where the system did not write the remaining cached information (sync'ed) to the disks.
When this happens, you need to verify the integrity of each of the file systems. This is necessary because if the structure is not correct, using them could quickly damage them beyond repair. Over the years, UNIX has developed a very sophisticated file
system integrity check that can usually recover the problem. It's called fsck. Of course, if it cannot handle the problem, the gurus out there can always try fsdb, the file system debugger.
The fsck Utility
The fsck utility takes its understanding of the internals of the various UNIX file systems and attempts to verify that all the links and blocks are correctly tied together. It runs in five passes, each of which checks a different part of the linkage and
each of which builds on the verifications and corrections of the prior passes.
fsck walks the file system, starting with the super-block. It then deals with the allocated disk blocks, pathnames, directory connectivity, link reference counts, and the free list of blocks and inodes.
The Super-Block
Every change to the file system affects the super-block, which is why it is cached in RAM. Periodically, at the sync interval, it is written to disk. If it is corrupted, fsck will check and correct it. If it is so badly corrupted that fsck cannot do its
work, find the paper you saved when you built the file system and use the -b option to fsck to give it an alternate super-block to use. The super-block is the head of each of the lists that make up the file system and maintains counts of free blocks and
inodes.
Inodes
fsck validates each of the inodes. It makes sure that each block in the block allocation list is not on the block allocation list in any other inode, that the size is correct, and that the link count is correct. If the inodes are correct, then the data
is accessible. All that's left is to verify the pathnames.
What Is a Clean (Stable) File System?
Some times fsck responds
/opt: stable (ufs file systems)
file system is clean - log replay not required (vxfs file systems)
This means that the super-block is marked clean and that no changes have been made to the file system since it was marked clean. What the system does is first mark the super-block dirty, then it starts modifying the rest of the file system. When the
buffer cache is empty and all pending writes are complete, it goes back and marks the super-block as clean. If it is marked clean, there is normally no reason to run fsck, so unless fsck is told to ignore the clean flag, it just prints this notice and
skips over this file system.
Where Is fsck?
When you run fsck, you are running an executable in the /usr/sbin directory called /usr/sbin/fsck, but this is not the real fsck. It is just a dispatcher that invokes a file system type-specific fsck utility. In the directory /usr/lib/fs resides a
directory for each supported file system type. There are specific programs in this directory for dealing with a particular file system type.
When Should I Run fsck?
Normally you do not have to run fsck. The system runs it automatically when you try to mount a file system that is dirty. However, problems can creep up on you. Software and hardware glitches do occur from time to time. It wouldn't hurt to run fsck just
after performing the monthly backups.
How Do I Run fsck?
Because the system normally runs it for you, running fsck is not an everyday occurrence for you to remember. However, it is quite simple and mostly automatic.
First, to run fsck, the file system you intend to check must not be mounted. This is a bit hard to do if you are in multiuser mode most of the time, so to run a full system fsck you should shut the system down to single user mode. For System V type
systems, such as Unixware or Solaris, use
shutdown -i s
to transition the system to state s, or single user. For older Berkeley style systems, such as SunOS, shut down the system entirely and reboot into single user mode using
boot -s
In single user mode you need to invoke fsck, giving it the options to force a check of all file systems, even if they are already stable.
fsck -o f (ufs file systems)
fsck -o full (vxfs file systems)
If you wish to check a single specific file system, type its character special device name
fsck -o full /dev/rdsk/c0t1d0s1
Checking s5 File Systems
For s5 file systems, fsck is a 5- or 6-phase process, depending on what errors were found, if any. fsck can automatically correct most of these errors and will do so if invoked by the mount command to automatically check a dirty file system. However,
when it is run manually you will be asked to answer the questions that the system would automatically answer.
Phase 1: Blocks and Sizes
During this phase, fsck checks that a file has an appropriate number of blocks allocated for its size and begins to scan for blocks being allocated to more than one file.
You may have to approve (answer yes or no) for clearing inode entries for
UNKNOWN FILE TYPE I=inode number (CLEAR?) PARTIALLY ALLOCATED INODE I=inode number (CLEAR?)
In both of these cases, the entire file is lost. Other errors you may be asked to handle include
SIZE ERROR I=inode number DELETE OR RECOVER EXCESS DATA
If the file appears to be of a different size than allocated, you can either delete the excess data or extend the inode to cover the excess data.
WARNING: SUPER BLOCK, ROOT INODE, OR ROOT DIRECTORY ON fs MAY BE CORRUPTED. fsck CAN'T DETERMINE LOGICAL BLOCK SIZE OF fs BLOCK SIZE COULD BE 512, 1024, OR 2048 BYTES. ENTER LOGICAL BLOCK SIZE OF fs IN BYTES (NOTE: INCORRECT RESPONSE COULD DAMAGE FILE SYSTEM BEYOND REPAIR!) ENTER 512, 1024, OR 2048 OR ENTER s TO SKIP THIS FILE SYSTEM: ENTER 512, 1024, 2048, OR s:
be very careful what you answer. Be sure you have a backup before proceeding. Find the sheet you saved when you built the file system, and retrieve the value from that sheet. If you do enter the correct value, fsck has a good chance of recovering the file system, unless something else was really written over it.
BAD BLK blocknum I=inode number EXCESSIVE BAD BLKS I=inode number
fsck will ask you if you want to clear (erase) this file. One of the files with the duplicate blocks will have to be erased.
DUP BLK blocknum I=inode number EXCESSIVE DUP BLKS I=inode number
If duplicate blocks are found, a phase 1b will be run to scan for the original file that has the duplicate blocks.
Phase 2: Pathnames
This phase removes directory entries from bad inodes found in phase 1 and 1b and checks for directories with inode pointers that are out of range or pointing to bad inodes. You might have to handle
ROOT INODE NOT DIRECTORY (FIX?)
You can convert inode 2, the root directory, back into a directory, but this usually means there is major damage to the inode table.
I OUT OF RANGE I=inode number NAME=file name (REMOVE?) UNALLOCATED I=inode number OWNER=O MODE=M SIZE=S MTIME=T NAME=file name (REMOVE?) BAD/DUP I=inode number OWNER=O MODE=M SIZE=S MTIME=T DIR=file name (REMOVE?) BAD/DUP I=inode number OWNER=O MODE=M SIZE=S MTIME=T FILE=file name (REMOVE?)
A bad inode number was found, an unallocated inode was used in a directory, or an inode that had a bad or duplicate block number in it is referenced. You are given the choice to remove the file, losing the data, or to leave the error. If you leave the
error, the file system is still damaged, but you have the chance to try to dump the file first and salvage part of the data before rerunning fsck to remove the entry.
Phase 3: Connectivity
This phase checks for unreferenced directories and connects them into the lost+found directory. Errors occur only if there isn't enough room in lost+found or if the lost+found directory does not exist. Status messages are printed for each reconnection.
Phase 4: Reference Counts
This phase uses the information from phases 2 and 3 to check for unreferenced files and incorrect link counts on files, directories, or special files.
UNREF FILE I=inode number OWNER=O MODE=M SIZE=S MTIME=T (RECONNECT?)
The filename is not known (it is an unreferenced file), so it is reconnected into the lost+found directory with the inode number as its name. If you clear the file, its contents are lost. Unreferenced files that are empty are cleared automatically.
LINK COUNT FILE I=inode number OWNER=O MODE=M SIZE=S MTIME=T COUNT=X (ADJUST?) LINK COUNT DIR I=inode number OWNER=O MODE=M SIZE=S MTIME=T COUNT=X (ADJUST?)
In both cases, an entry was found with a different number of references than what was listed in the inode. You should let fsck adjust the count.
Phase 5: Free List
The list of free-blocks is checked for duplicates, bad blocks (block number is invalid), and blocks that are in use. If there is a problem, you will be asked to salvage the free list. This will run a sixth phase to reconstruct the free list.
Checking ufs File Systems
For ufs file systems, fsck is a 5-phase process. fsck can automatically correct most of these errors and will do so if invoked by the mount command to automatically check a dirty file system. However, when run manually you will be asked to answer the
questions that the system would automatically answer.
Phase 1: Check Blocks and Sizes
This phase checks the inode list, looking for invalid inode entries. Errors requiring answers include
UNKNOWN FILE TYPE I=inode number (CLEAR)
The file type bits are invalid in the inode. Options are to leave the problem and attempt to recover the data by hand later or to erase the entry and its data by clearing the inode.
PARTIALLY TRUNCATED INODE I=inode number (SALVAGE)
The inode appears to point to less data than the file does. This is safely salvaged, because it indicates a crash while truncating the file to shorten it.
block BAD I=inode number block DUP I=inode number
The disk block pointed to by the inode is either out of range for this inode or already in use by another file. This is an informational message. If a duplicate block is found, phase 1b will be run to report the inode number of the file that originally
used this block.
Phase 2: Check Pathnames
This phase removes directory entries from bad inodes found in phase 1 and 1b and checks for directories with inode pointers that are out of range or pointing to bad inodes. You may have to handle
ROOT INODE NOT DIRECTORY (FIX?)
You can convert inode 2, the root directory, back into a directory, but this usually means there is major damage to the inode table.
I=OUT OF RANGE I=inode number NAME=file name (REMOVE?) UNALLOCATED I=inode number OWNER=O MODE=M SIZE=S MTIME=T TYPE=F (REMOVE?) BAD/DUP I=inode number OWNER=O MODE=M SIZE=S MTIME=T TYPE=F (REMOVE?)
A bad inode number was found, an unallocated inode was used in a directory, or an inode that had a bad or duplicate block number in it is referenced. You are given the choice to remove the file, losing the data, or to leave the error. If you leave the
error, the file system is still damaged, but you have the chance to try to dump the file first and salvage part of the data before rerunning fsck to remove the entry.
Various Directory Length Errors: zero length, too short, not multiple of block size, corrupted
You will be given the chance to have fsck fix or remove the directory as appropriate. These errors are all correctable with little chance of subsequent damage.
Phase 3: Check Connectivity
This phase will detect errors in unreferenced directories. It will create or expand the lost+found directory if needed and connect these directories into the lost+found directory. It prints status messages for all directories placed in lost+found.
Phase 4: Check Reference Counts
This phase uses the information from phases 2 and 3 to check for unreferenced files and incorrect link counts on files, directories, or special files.
UNREF FILE I=inode number OWNER=O MODE=M SIZE=S MTIME=T (RECONNECT?)
The filename is not known (it is an unreferenced file), so it is reconnected into the lost+found directory with the inode number as its name. If you clear the file, its contents are lost. Unreferenced files that are empty are cleared automatically.
LINK COUNT FILE I=inode number OWNER=O MODE=M SIZE=S MTIME=T COUNT=X (ADJUST?) LINK COUNT DIR I=inode number OWNER=O MODE=M SIZE=S MTIME=T COUNT=X (ADJUST?)
In both cases, an entry was found with a different number of references than what was listed in the inode. You should let fsck adjust the count.
BAD/DUP FILE I=inode number OWNER=O MODE=M SIZE=S MTIME=T (CLEAR)
A file or directory has a bad or duplicate block in it. If you clear it now, the data is lost. You can leave the error and attempt to recover the data, and rerun fsck later to clear the file.
Phase 5: Check Cylinder Groups
This phase checks the free block and unused inode maps. It will automatically correct the free lists if necessary, although in manual mode it will ask permission first.
Checking vxfs File Systems
Although s5 and ufs file systems are not all that different in their fsck, vxfs is totally different. It first runs a sanity check on the file system recovering the super-block from the first allocation unit if needed or any allocation unit headers from
the super-block if needed. Then, unless a full fsck was requested, it replays the intent log and exits in a few seconds. No intervention is needed.
If a full fsck is requested—this should be needed only in cases of hardware failure—you should run it in interactive mode (no -p, -y or -n options on the fsck command line) and answer yes to the questions. Errors in connecting files or
directories will clear those files or directories. It will then be necessary to recover them from backups.
What Do I Do After fsck Finishes?
First relax, because fsck rarely finds anything serious wrong, except in cases of hardware failure where the disk drive is failing or where you copied something on top of the file system. UNIX file systems really are very robust.
However, if fsck did find major problems or made a large number of corrections, rerun it to be sure the disk isn't undergoing hardware failure. It shouldn't find more errors in a second run. Then recover any files that it may have deleted. If you keep a
log of the inodes it clears, you can go to a backup tape and dump the list of inodes on the tape. Recover just those inodes to restore the files.
Back up the system again, because there is no reason to have to do this all over again.
Dealing with What Is in lost+found
If fsck reconnected unreferenced entries, it placed them in the lost+found directory. They are safe there, and the system should be backed up in case you lose them while trying to move them back to where they belong. Items in lost+found can be of any
type: files, directories, special files (devices), or fifos. If it is a fifo, you can safely delete it: the process that opened it is long since gone and will open a new one when it runs again.
For files, use the owner name to contact the owner and have him look at the contents and see if the file is worth keeping. Often it is a file that was deleted and is no longer needed, but the system crashed before it could be fully removed.
For directories, the files in the directory should help you and the owner determine where they belong. You can look on the backup tape lists for a directory with those contents if necessary. Then just remake the directory and move the files back. Then
remove the directory entry in lost+found. This re-creation and move has the added benefit of cleaning up the directory.
Finding and Reclaiming Space
One of the banes of system administrators is that users always use 100 percent of the disk space available to them on a system. It always falls on the systems administrator to prod users into removing files and directory trees they no longer need. It
helps if you can attack the portion of the problem that will yield the greatest reward: the users with large files and the users tying up the most space.
What Takes Space
Besides users leaving around files they no longer need, two types of files are often blamed for taking up a lot of wasted space: core files and backup images.
Whenever a user program aborts on a programming error, a copy of the data space is made to a file named core. Core files are very useful for debugging but if left around can take up large amounts of space.
Backup images are made whenever a program automatically saves a backup copy before modifying a file. Many UNIX programs have this behavior. Often old backups remain long after the file has stopped being modified. Some examples of this are .orig files
from patch, .backup files from frame, and name% files from emacs.
Developers also often make backup copies of directories before working on them, and they may forget to remove these when completed. It all adds up to large amounts of disk being used for nonproductive files.
Determining Who Is Using Up the Disk
UNIX provides several tools for determining disk utilization. These include the accounting system, which can track the ownership of disk storage on a daily basis, du for determining where storage is being used, and the diskusg family of utilities for
determining totals per user ID. For information on du, see Chapter 38, "Accounting System."
The System Administrator's Friend The find Utility
One of the most useful tools for a system administrator is the find utility. It traverses all or sections of the UNIX file system hierarchy and can perform tests and execute commands on the files it visits, including the following:
- Finding core files
Many sites run the script findcores from cron each night to find and remove old core files. It contains one line:
find / -local -name core -mtime +7 -print | xargs rm -f
This use of find starts at the root. It traverses only local file systems, avoiding ones on other machines on the network. If the file is named core and has not been modified for at least seven days, it prints its name. Then the xargs utility is used to remove these core files.
- Finding files not accessed recently
Files that are on the disk but never read are prime candidates for removal when space is at a premium. The find statement
find / -local -atime +60 -a -mtime +60 -print | sort
will produce a useful list of files that have not been accessed or modified in the past 60 days. Because find traverses the file system tree in the order of the directory entries (the order in which they were created, not the alphabetical order shown by ls), the sort utility is a handy way of making the output of the list appear in a more human readable order.
- Finding large files
Of course, large files are the easiest targets. Finding them is just as easy.
find / -local -size +500 -print | sort | xargs ls -lsd
will produce a listing of all files larger than 500 blocks. The use of the xargs command will produce a listing showing the owner and size in both blocks and bytes for each file. The sort step will place files in the same directory together in the listing; otherwise, the quantization effects of the xargs command could separate these files in the listing.
Reorganizing the File System Hierarchy
Sooner or later, you'll have to add space to the system. The only way to make more space on a disk drive without deleting the files is to move the files on part of that drive somewhere else. Using the move command to move the files one at a time is
tedious and prone to mistakes. The cp -r command will move a directory and its descendents, but it changes the owner and time stamps, which is sort of intrusive. However, all is not lost. UNIX does provide utilities to make moving files around simple.
Using Symbolic Links to Hide Actual Disk Locations
One of the goals in moving the files was to make space, but that conflicts with the goal of not disturbing the user. It would be best if the user could still think the files were in the old directory even though you have moved them. Symbolic links are
the answer. Using a symbolic link from the old location to the new location makes the files appear to still be in the old location.
All that is left is to move the files and create the symbolic link.
Moving Trees via cpio
cpio, or cp in/out, has one more mode that when combined with the find utility lets you easily move entire directory trees. This is the pass mode. In this mode, it takes entire hierarchies from one place on the disk and makes a perfect replica of them
in another. To move the files in /home/bob to /disks/bob, all you do is
cd /home find bob -print | cpio -pdluam /disks rm -rf bob ln -s /disks/bob bob
and you are done. The find command prints a list of all the files in and below bob in the tree. cpio then re-creates these files under the /disks directory. The arguments used for cpio are as follows:
- p—Pass mode; create a replica of the pathnames read on standard input
- d—Create directories as needed
- l—Create links if possible (hard links)
- u—Unconditional; overwrite the file if it already exists and is newer than the copy
- a—Reset the access time of the original and replica file to what it was prior to cpio running
- m—Reset the modification time of the replica file to match the modification time of the original
cpio copies everything about the file. It even copies special files.
The rm command removes the original files after the copy is complete, and the ln creates the symbolic link.
See Chapters 31, "Archiving" and 32, "Backups," for information on the other archiving methods, dump and tar.
Summary
In UNIX, the following is true:
- Disks are a sequence of bytes.
- Disks are split into sections called slices.
- After a disk is formatted and partitioned, a label is written to the disk to define the slices in a virtual table of contents.
- The slices appear as disk drives.
- Each slice can hold one file system. Some slices are used as raw data areas for swap space or application-specific data such as for databases.
- The file system hierarchy is a tree.
- New file systems can be mounted onto that tree at any place.
- Mounted file systems obscure the mount point directory.
- The basis of a file system is the inode list. It contains all the information about a file.
- Support is provided for multiple types of file systems.
- Multiple methods are provided for backing up these file systems.
As a Systems Administrator, the following are your responsibilities:
- Monitor the available space on the file systems.
The tools provided in this chapter will help you keep track of usage.
- Perform regular checks on file system integrity.
UNIX file systems are very stable, but it doesn't hurt to check them out once a month.
- Perform and verify the readability of backups.
Perform them daily. UNIX's tools make full and incremental backups easy to interleave.
Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451




{kind=link}
{kind=link}