Web based School
Chapter 10
Associative Arrays
- Limitations of Array Variables
- Definition
- Referring to Associative Array Elements
- Adding Elements to an Associative Array
- Creating Associative Arrays
- Copying Associative Arrays from Array Variables
- Adding and Deleting Array Elements
- Listing Array Indexes and Values
- Looping Using an Associative Array
- Creating Data Structures Using Associative Arrays
- Summary
- Q&A
- Workshop
ToChapter's lesson shows you how to use associative arrays. You'll learn the following:
- What an associative array is
- How to access and create an associative array
- How to copy to and from an associative array
- How to add and delete associative array elements
- How to list array indexes and values
- How to loop using an associative array
- How to build data structures using associative arrays
To start, take a look at some of the problems that using array variables creates. Once you have seen some of the difficulties created by array variables in certain contexts, you'll see how associative arrays can eliminate these difficulties.
Limitations of Array Variables
In the array variables you've seen so far, you can access an element of a stored list by specifying a subscript. For example, the following statement accesses the third element of the list stored in the array variable @array:
$scalar = $array[2];
The subscript 2 indicates that the third element of the array is to be referenced.
Although array variables are useful, they have one significant drawback: it's often difficult to remember which element of an array stores what. For example, suppose you want to write a program that counts the number of occurrences of each capitalized word in an input file. You can do this using array variables, but it's very difficult. Listing 10.1 shows you what you have to go through to do this.

Listing 10.1. A program that uses array variables to keep track of capitalized words in an input file.
1: #!/usr/local/bin/perl
2:
3: while ($inputline = <STDIN>) {
4: while ($inputline =~ /\b[A-Z]\S+/g) {
5: $word = $&;
6: $word =~ s/[;.,:-]$//; # remove punctuation
7: for ($count = 1; $count <= @wordlist;
8: $count++) {
9: $found = 0;
10: if ($wordlist[$count-1] eq $word) {
11: $found = 1;
12: $wordcount[$count-1] += 1;
13: last;
14: }
15: }
16: if ($found == 0) {
17: $oldlength = @wordlist;
18: $wordlist[$oldlength] = $word;
19: $wordcount[$oldlength] = 1;
20: }
21: }
22: }
23: print ("Capitalized words and number of occurrences:\n");
24: for ($count = 1; $count <= @wordlist; $count++) {
25: print ("$wordlist[$count-1]: $wordcount[$count-1]\n");
26: }

$ program10_1 Here is a line of Input. This Input contains some Capitalized words. ^D Capitalized words and number of occurrences: Here: 1 Input: 2 This: 1 Capitalized: 1 $
![]()
This program reads one line of input at a time from the standard input file. The loop starting on line 4 matches each capitalized word in the line; the loop iterates once for each match, and it assigns the match being examined in this particular iteration to the scalar variable $word.
Once any closing punctuation has been removed by line 6, the program must then check whether this word has been seen before. Lines 7-15 do this by examining each element of the list @wordlist in turn. If an element of @wordlist is identical to the word stored in $word, the corresponding element of @wordcount is incremented.
If no element of @wordlist matches $word, lines 16-20 add a new element to @wordlist and @wordcount.
Definition
As you can see, using array variables creates several problems. First, it's not obvious which element of @wordlist in Listing 10.1 corresponds to which capitalized word. In the example shown, $wordlist[0] contains Here because this is the first capitalized word in the input file, but this is not obvious to the reader.
Worse still, the program has no way of knowing which element of @wordlist contains which word. This means that every time the program reads a new word, it has to check the entire list to see if the word has already been found. This becomes time-consuming as the list grows larger.
All of these problems with array variables exist because elements of array variables are accessed by numeric subscripts. To get around these problems, Perl defines another kind of array, which enables you to access array variables using any scalar value you like. These arrays are called associative arrays.
To distinguish an associative array variable from an ordinary array variable, Perl uses the % character as the first character of an associative array-variable name, instead of the @ character. As with other variable names, the first character following the % must be a letter, and subsequent characters can be letters, digits, or underscores.
The following are examples of associative array-variable names:
%assocarray %a1 %my_really_long_but_legal_array_variable_name
| NOTE |
Use the same name for an associative array variable and an ordinary array variable. For example, you can define an array variable named @arrayname and an associative array variable named %arrayname. The @ and % characters ensure that the Perl interpreter can tell one variable name from another. |
Referring to Associative Array Elements
The main difference between associative arrays and ordinary arrays is that associative array subscripts can be any scalar value. For example, the following statement refers to an element of the associative array %fruit:
$fruit{"bananas"} = 1;
The subscript for this array element is bananas. Any scalar value can be a subscript. For example:
$fruit{"black_currant"}
$number{3.14159}
$integer{-7}
A scalar variable can be used as a subscript, as follows:
$fruit{$my_fruit}
Here, the contents of $my_fruit become the subscript into the associative array %fruit.
When an array element is referenced, as in the previous example,
the name of the array element is preceded by a $ character,
not the % character. As with array variables, this tells
the Perl interpreter that this is a single scalar item and is
to be treated as such.
| NOTE |
Subscripts for associative array elements are always enclosed in brace brackets ({}), not square brackets ([]). This ensures that the Perl interpreter is always able to distinguish associative array elements from other array elements. |
Adding Elements to an Associative Array
The easiest way to create an associative array item is just to assign to it. For example, the statement
$fruit{"bananas"} = 1;
assigns 1 to the element bananas of the associative array %fruit. If this element does not exist, it is created. If the array %fruit has not been referred to before, it also is created.
This feature makes it easy to use associative arrays to count occurrences of items. For example, Listing 10.2 shows how you can use associative arrays to count the number of capitalized words in an input file. Note how much simpler this program is than the one in Listing 10.1, which accomplishes the same task.
Listing 10.2. A program that uses an associative array to count the number of capitalized words in a file.
1: #!/usr/local/bin/perl
2:
3: while ($inputline = <STDIN>) {
4: while ($inputline =~ /\b[A-Z]\S+/g) {
5: $word = $&;
6: $word =~ s/[;.,:-]$//; # remove punctuation
7: $wordlist{$word} += 1;
8: }
9: }
10: print ("Capitalized words and number of occurrences:\n");
11: foreach $capword (keys(%wordlist)) {
12: print ("$capword: $wordlist{$capword}\n");
13: }
$ program10_2 Here is a line of Input. This Input contains some Capitalized words. ^D Capitalized words and number of occurrences: This: 1 Input: 2 Here: 1 Capitalized: 1 $
![]()
As you can see, this program is much simpler than the one in Listing 10.1. The previous program required 20 lines of code to read input and store the counts for each word; this program requires only seven.
As before, this program reads one line of input at a time from the standard input file. The loop starting in line 4 iterates once for each capitalized word found in the input line; each match is assigned, in turn, to the scalar variable $word.
Line 7 uses the associative array %wordlist to keep track of the capitalized words. Because associative arrays can use any value as a subscript for an element, this line uses the word itself as a subscript. Then, the element of the array corresponding to the word has 1 added to its value.
For example, when the word Here is read in, the associative array element $wordlist{"Here"} has 1 added to its value.
Lines 11-13 print the elements of the associative array. Line
11 contains a call to a special built-in function, keys.
This function returns a list consisting of the subscripts of the
associative array; the foreach statement then loops through
this list, iterating once for each element of the associative
array. Each subscript of the associative array is assigned, in
turn, to the local variable $capword; in this example,
this means that $capword is assigned Here, Input,
Capitalized, and This-one per each iteration
of the for each loop.
An important fact to remember is that associative arrays always are stored in "random" order. (Actually, it's the order that ensures fastest access, but, effectively, it is random.) This means that if you use keys to access all of the elements of an associative array, there is no guarantee that the elements will appear in any given order. In particular, the elements do not always appear in the order in which they are created. |
To control the order in which the associative array elements appear, use sort to sort the elements returned by keys.
foreach $capword (sort keys(%wordlist)) {
print ("$capword: $wordlist{$capword}\n");
}
When line 10 of Listing 10.2 is modified to include a call to sort, the associative array elements appear in sorted order.
Creating Associative Arrays
You can create an associative array with a single assignment. To do this, alternate the array subscripts and their values. For example:
%fruit = ("apples", 17, "bananas", 9, "oranges", "none");
This assignment creates an associative array of three elements:
- An element with subscript apples, whose value is 17
- An element with subscript bananas, whose value is 9
- An element with subscript oranges, whose value is none
Again, it is important to remember that the elements of associative arrays are not guaranteed to be in any particular order, even if you create the entire array at once. |
| NOTE |
Perl version 5 enables you to use either => or , to separate array subscripts and values when you assign a list to an associative array. For example: %fruit = ("apples" => 17, "bananas" => 9, "oranges" => "none"); This statement is identical to the previous one, but is easier to understand; the use of => makes it easier to see which subscript is associated with which value. |
As with any associative array, you always can add more elements to the array later on. For example:
$fruit{"cherries"} = 5;
This adds a fourth element, cherries, to the associative array %fruit, and gives it the value 5.
Copying Associative Arrays from Array Variables
The list of subscripts and values assigned to %fruit in the previous example is an ordinary list like any other. This means that you can create an associative array from the contents of an array variable. For example:
@fruit = ("apples", 6, "cherries", 8, "oranges", 11);
%fruit = @fruit;
The second statement creates an associative array of three elements-apples,
cherries, and oranges-and assigns it to %fruit.
If you are assigning a list or the contents of an array variable to an associative array, make sure that the list contains an even number of elements, because each pair of elements corresponds to the subscript and the value of an associative array element. |
Similarly, you can copy one associative array into another. For example:
%fruit1 = ("apples", 6, "cherries", 8, "oranges", 11);
%fruit2 = %fruit1;
You can assign an associative array to an ordinary array variable in the same way. For example:
%fruit = ("grapes", 11, "lemons", 27);
@fruit = %fruit;
However, this might not be as useful, because the order of the array elements is not defined. Here, the array variable @fruit is assigned either the four-element list
("grapes", 11, "lemons", 27)
or the list
("lemons", 27, "grapes", 11)
depending on how the associative array is sorted.
You can also assign to several scalar variables and an associative array at the same time.
($var1, $var2, %myarray) = @list;
Here, the first element of @list is assigned to $var1, the second to $var2, and the rest to %myarray.
Finally, an associative array can be created from the return value of a built-in function or user-defined subroutine that returns a list. Listing 10.3 is an example of a simple program that does just that. It takes the return value from split, which is a list, and assigns it to an associative array variable.
Listing 10.3. A program that uses the return value from a built-in function to create an associative array.
1: #!/usr/local/bin/perl
2:
3: $inputline = <STDIN>;
4: $inputline =~ s/^\s+|\s+\n$//g;
5: %fruit = split(/\s+/, $inputline);
6: print ("Number of bananas: $fruit{\"bananas\"}\n");
$ program10_3 oranges 5 apples 7 bananas 11 cherries 6 Number of bananas: 11 $
![]()
This program reads a line of input from the standard input file and eliminates the leading and trailing white space. Line 5 then calls split, which breaks the line into words. In this example, split returns the following list:
("oranges", 5, "apples", 7, "bananas", 11, "cherries", 6)
This list is then assigned to the associative array %fruit.
This assignment creates an associative array with four elements:
Element Value oranges 5 apples 7 bananas 11 cherries 6
Line 6 then prints the value of the element bananas, which is 11.
Adding and Deleting Array Elements
As you've seen, you can add an element to an associative array by assigning to an element not previously seen, as follows:
$fruit{"lime"} = 1;
This statement creates a new element of %fruit with index lime and gives it the value 1.
To delete an element, use the built-in function delete. For example, the following statement deletes the element orange from the array %fruit:
delete($fruit{"orange"});
DO use the delete function to delete an element of an associative array; it's the only way to delete elements. DON'T use the built-in functions push, pop, shift, or splice with associative arrays because the position of any particular element in the array is not guaranteed. |
Listing Array Indexes and Values
As you saw in Listing 10.2, the keys function retrieves a list of the subscripts used in an associative array. The following is an example:
%fruit = ("apples", 9,
"bananas", 23,
"cherries", 11);
@fruitsubs = keys(%fruits);
Here, @fruitsubs is assigned the list consisting of the elements apples, bananas, and cherries. Note once again that this list is in no particular order. To retrieve the list in alphabetical order, use sort on the list.
@fruitindexes = sort keys(%fruits));
This produces the list ("apples", "bananas", "cherries").
To retrieve a list of the values stored in an associative array, use the built-in function values. The following is an example:
%fruit = ("apples", 9,
"bananas", 23,
"cherries", 11);
@fruitvalues = values(%fruits);
Here, @fruitvalues contains the list (9, 23, 11), not necessarily in this order.
Looping Using an Associative Array
As you've seen, you can use the built-in function keys with the foreach statement to loop through an associative array. The following is an example:
%records = ("Maris", 61, "Aaron", 755, "Young", 511);
foreach $holder (keys(%records)) {
# stuff goes here
}
The variable $holder is assigned Aaron, Maris, and Young on successive iterations of the loop (although not necessarily in that order).
This method of looping is useful, but it is inefficient. To retrieve the value associated with a subscript, the program must look it up in the array again, as follows:
foreach $holder (keys(%records)) {
$record = %records{$holder};
}
Perl provides a more efficient way to work with associative array subscripts and their values, using the built-in function each, as follows:
%records = ("Maris", 61, "Aaron", 755, "Young", 511);
while (($holder, $record) = each(%records)) {
# stuff goes here
}
Every time the each function is called, it returns a two-element list. The first element of the list is the subscript for a particular element of the associative array. The second element is the value associated with that particular subscript.
For example, the first time each is called in the preceding code fragment, the pair of scalar variables ($holder, $record) is assigned one of the lists ("Maris", 61), ("Aaron", 755), or ("Young", 511). (Because associative arrays are not stored in any particular order, any of these lists could be assigned first.) If ("Maris", 61) is returned by the first call to each, Maris is assigned to $holder and 61 is assigned to $record.
When each is called again, it assigns a different list
to the pair of scalar variables specified. Subsequent calls to
each assign further lists, and so on until the associative
array is exhausted. When there are no more elements left in the
associative array, each returns the empty list.
| NOTE |
Don't add a new element to an associative array or delete an element from it if you are using the each statement on it. For example, suppose you are looping through the associative array %records using the following loop: while (($holder, $record) = each(%records)) { Adding a new record to %records, such as $records{"Rose"} = 4256; or deleting a record, as in delete $records{"Cobb"}; makes the behavior of each unpredictable. This should be avoided. |
Creating Data Structures Using Associative Arrays
You can use associative arrays to simulate a wide variety of data structures found in high-level programming languages. This section describes how you can implement the following data structures in Perl using associative arrays:
- Linked lists
- Structures
- Trees
- Databases
| NOTE |
The remainder of toChapter's lesson describes applications of associative arrays but does not introduce any new features of Perl. If you are not interested in applications of associative arrays, you can skip to the next chapter without suffering any loss of general instruction. |
Linked Lists
A linked list is a simple data structure that enables you to store items in a particular order. Each element of the linked list contains two fields:
- The value associated with this element
- A reference, or pointer, to the next element in the list
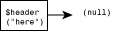
Also, a special header variable points to the first element in the list.
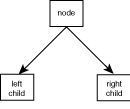
Pictorially, a linked list can be represented as in Figure 10.1. As you can see, each element of the list points to the next.
In Perl, a linked list can easily be implemented using an associative array because the value of one associative array element can be the subscript for the next. For example, the following associative array is actually a linked list of words in alphabetical order:
%words = ("abel", "baker",
"baker", "charlie",
"charlie", "delta",
"delta", "");
$header = "abel";
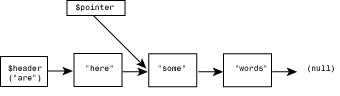
In this example, the scalar variable $header contains the first word in the list. This word, abel, is also the subscript of the first element of the associative array. The value of the first element of this array, baker, is the subscript for the second element, and so on, as illustrated in Figure 10.2.
Figure 10.2: A linked list of words in alphabetical order.
The value of the last element of the subscript, delta, is the null string. This indicates the end of the list.
Linked lists are most useful in applications where the amount of data to be processed is not known, or grows as the program is executed. Listing 10.4 is an example of one such application. It uses a linked list to print the words of a file in alphabetical order.
Listing 10.4. A program that uses an associative array to build a linked list.
1: #!/usr/local/bin/perl
2:
3: # initialize list to empty
4: $header = "";
5: while ($line = <STDIN>) {
6: # remove leading and trailing spaces
7: $line =~ s/^\s+|\s+$//g;
8: @words = split(/\s+/, $line);
9: foreach $word (@words) {
10: # remove closing punctuation, if any
11: $word =~ s/[.,;:-]$//;
12: # convert all words to lower case
13: $word =~ tr/A-Z/a-z/;
14: &add_word_to_list($word);
15: }
16: }
17: &print_list;
18:
19: sub add_word_to_list {
20: local($word) = @_;
21: local($pointer);
22:
23: # if list is empty, add first item
24: if ($header eq "") {
25: $header = $word;
26: $wordlist{$word} = "";
27: return;
28: }
29: # if word identical to first element in list,
30: # do nothing
31: return if ($header eq $word);
32: # see whether word should be the new
33: # first word in the list
34: if ($header gt $word) {
35: $wordlist{$word} = $header;
36: $header = $word;
37: return;
38: }
39: # find place where word belongs
40: $pointer = $header;
41: while ($wordlist{$pointer} ne "" &&
42: $wordlist{$pointer} lt $word) {
43: $pointer = $wordlist{$pointer};
44: }
45: # if word already seen, do nothing
46: return if ($word eq $wordlist{$pointer});
47: $wordlist{$word} = $wordlist{$pointer};
48: $wordlist{$pointer} = $word;
49: }
50:
51: sub print_list {
52: local ($pointer);
53: print ("Words in this file:\n");
54: $pointer = $header;
55: while ($pointer ne "") {
56: print ("$pointer\n");
57: $pointer = $wordlist{$pointer};
58: }
59: }
$ program10_4 Here are some words. Here are more words. Here are still more words. ^D Words in this file: are here more some still words $
![]()
The logic of this program is a little complicated, but don't despair. Once you understand how this works, you have all the information you need to build any data structure you like, no matter how complicated.
This program is divided into three parts, as follows:
- The main program, which reads input and transforms it into the desired format
- The subroutine add_word_to_list, which builds the linked list of sorted words
- The subroutine print_list, which prints the list of words
Lines 3-17 contain the main program. Line 4 initializes the list of words by setting the header variable $header to the null string. The loop beginning in line 5 reads one line of input at a time. Line 7 removes leading and trailing spaces from the line, and line 8 splits the line into words.
The inner foreach loop in lines 9-15 processes one word of the input line at a time. If the final character of a word is a punctuation character, line 11 removes it; this ensures that, for example, word. (word with a period) is considered identical to word (without a period). Line 13 converts the word to all lowercase characters, and line 14 passes the word to the subroutine add_word_to_list.
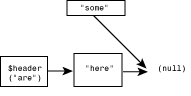
This subroutine first executes line 24, which checks whether the linked list of words is empty. If it is, line 25 assigns this word to $header, and line 26 creates the first element of the list, which is stored in the associative array %wordlist. In this example, the first word read in is here (Here converted to lowercase), and the list looks like Figure 10.3.
Figure 10.3: The linked list with one element in it.
At this point, the header variable $header contains the value here, which is also the subscript for the element of %wordlist that has just been created. This means that the program can reference %wordlist by using $header as a subscript, as follows:
$wordlist{$header}
Variables such as $header that contain a reference to another data item are called pointers. Here, $header points to the first element of %wordlist.
If the list is not empty, line 31 checks whether the first item of the list is identical to the word currently being checked. To do this, it compares the current word to the contents of $header, which is the first item in the list. If the two are identical, there is no need to add the new word to the list, because it is already there; therefore, the subroutine returns without doing anything.
The next step is to check whether the new word should be the first word in the list, which is the case if the new word is alphabetically ahead of the existing first word. Line 34 checks this.
If the new word is to go first, the list is adjusted as follows:
- A new list element is created. The subscript of this element is the new word, and its value is the existing first word.
- The new word is assigned to the header variable.
To see how this adjustment works, consider the sample input provided. In this example, the second word to be processed is are. Because are belongs before here, the array element $wordlist{"are"} is created, and is given the value here. The header variable $header is assigned the value are. This means the list now looks like Figure 10.4.
Figure 10.4: The linked list with two elements in it.
The header variable $header now points to the list element with the subscript are, which is $wordlist{"are"}. The value of $wordlist{"are"} is here, which means that the program can access $wordlist{"here"} from $wordlist{"are"}. For example:
$reference = $wordlist{"are"};
print ("$wordlist{$reference}\n");
The value here is assigned to $reference, and print prints $wordlist{$reference}, which is $wordlist{"here"}.
Because you can access $wordlist{"here"} from $wordlist{"are"}, $wordlist{"are"} is a pointer to $wordlist{"here"}.
If the word does not belong at the front of the list, lines 40-44 search for the place in the list where the word does belong, using a local variable, $pointer. Lines 41-44 loop until the value stored in $wordlist{$pointer} is greater than or equal to $word. For example, Figure 10.5 illustrates where line 42 is true when the subroutine processes more.
Figure 10.5: The linked list when more is processed.
Note that because the list is in alphabetical order, the value stored in $pointer is always less than the value stored in $word.
If the word being added is greater than any word in the list, the conditional expression in line 41 eventually becomes true. This occurs, for example, when the subroutine processes some, as in Figure 10.6.
Figure 10.6: The linked list when some is processed.
Once the location of the new word has been determined, line 46 checks whether the word already is in the list. If it is, there is no need to do anything.
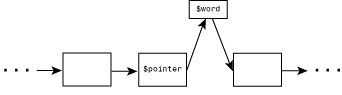
If the word does not exist, lines 47 and 48 add the word to the list. First, line 47 creates a new element of %wordlist, which is $wordlist{$word}; its value is the value of $wordlist{$pointer}. This means that $wordlist{$word} and $wordlist{$pointer} now point to the same word, as in Figure 10.7.
Figure 10.7: The linked list as a new word is being added.
Next, line 48 sets the value of $wordlist{$pointer} to the value stored in $word. This means that $wordlist{$pointer} now points to the new element, $wordlist{$word}, that was just created, as in Figure 10.8.
Figure 10.8: The linked list after the new word is added.
Once the input file has been completely processed, the subroutine
print_list prints the list, one element at a time. The
local variable $pointer contains the current value being
printed, and $wordlist{$pointer} contains the next value
to be printed.
| NOTE |
Normally, you won't want to use a linked list in a program. It's easier just to use sort and keys to loop through an associative array in alphabetical order, as follows: foreach $word (sort keys(%wordlist)) { However, the basic idea of a pointer, which is introduced here, is useful in other data structures, such as trees, which are described later on. |
Structures
Many programming languages enable you to define collections of data called structures. Like lists, structures are collections of values; each element of a structure, however, has its own name and can be accessed by that name.
Perl does not provide a way of defining structures directly. However, you can simulate a structure using an associative array. For example, suppose you want to simulate the following variable definition written in the C programming language:
struct {
int field1;
int field2;
int field3;
} mystructvar;
This C statement defines a variable named mystructvar, which contains three elements, named field1, field2, and field3.
To simulate this using an associative array, all you need to do is define an associative array with three elements, and set the subscripts for these elements to field1, field2, and field3. The following is an example:
%mystructvar = ("field1", "",
"field2", "",
"field3", "");
Like the preceding C definition, this associative array, named %mystructvar, has three elements. The subscripts for these elements are field1, field2, and field3. The definition sets the initial values for these elements to the null string.
As with any associative array, you can reference or assign the value of an element by specifying its subscript, as follows:
$mystructvar{"field1"} = 17;
To define other variables that use the same "structure," all you need to do is create other arrays that use the same subscript names.
Trees
Another data structure that is often used in programs is a tree. A tree is similar to a linked list, except that each element of a tree points to more than one other element.
The simplest example of a tree is a binary tree. Each element of a binary tree, called a node, points to two other elements, called the left child and the right child. Each of these children points to two children of its own, and so on, as illustrated in Figure 10.9.
Note that the tree, like a linked list, is a one-way structure. Nodes point to children, but children don't point to their parents.
The following terminology is used when describing trees:
- Because each of the children of a node is a tree of its own, the left child and the right child are often called the left subtree and the right subtree of the node. (The terms left branch and right branch are also used.)
- The "first" node of the tree (the node that is not a child of another node), is called the root of the tree.
- Nodes that have no children are called leaf nodes.
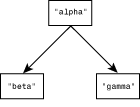
There are several ways of implementing a tree structure using associative arrays. To illustrate one way of doing so, suppose that you wish to create a tree whose root has the value alpha and whose children have the values beta and gamma, as in Figure 10.10.
Figure 10.10: A binary tree with three nodes.
Here, the left child of alpha is beta, and the right child of alpha is gamma.
The problem to be solved is this: How can a program associate both beta and gamma with alpha? If the associative array that is to represent the tree is named %tree, do you assign the value of $tree{"alpha"} to be beta, or gamma, or both? How do you show that an element points to two other elements?
There are several solutions to this problem, but one of the most elegant is as follows: Append the character strings left and right, respectively, to the name of a node in order to retrieve its children. For example, define alphaleft to point to beta and alpharight to point to gamma. In this scheme, if beta has children, betaleft and betaright point to their locations; similarly, gammaleft and gammaright point to the locations of the children of gamma, and so on.
Listing 10.5 is an example of a program that creates a binary tree using this method and then traverses it (accesses every node in the tree).
Listing 10.5. A program that uses an associative array to represent a binary tree.
1: #!/usr/local/bin/perl
2:
3: $rootname = "parent";
4: %tree = ("parentleft", "child1",
5: "parentright", "child2",
6: "child1left", "grandchild1",
7: "child1right", "grandchild2",
8: "child2left", "grandchild3",
9: "child2right", "grandchild4");
10: # traverse tree, printing its elements
11: &print_tree($rootname);
12:
13: sub print_tree {
14: local ($nodename) = @_;
15: local ($leftchildname, $rightchildname);
16:
17: $leftchildname = $nodename . "left";
18: $rightchildname = $nodename . "right";
19: if ($tree{$leftchildname} ne "") {
20: &print_tree($tree{$leftchildname});
21: }
22: print ("$nodename\n");
23: if ($tree{$rightchildname} ne "") {
24: &print_tree($tree{$rightchildname});
25: }
26: }
$ program10_5 grandchild1 child1 grandchild2 parent grandchild3 child2 grandchild4 $
![]()
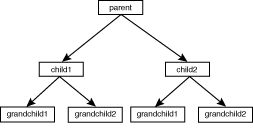
This program creates the tree depicted in Figure 10.11.
Figure 10.11: The tree created by Listing 10.5.
The associative array %tree stores the tree, and the scalar variable $rootname holds the name of the root of the tree. (Note that the grandchild nodes, such as grandchild1, are leaf nodes. There is no need to explicitly create grandchild1left, grandchild1right, and so on because the value of any undefined associative array element is, by default, the null string.)
After the tree has been created, the program calls the subroutine print_tree to traverse it and print its values. print_tree does this as follows:
- Line 17 appends left to the name of the node being examined to produce the name of the left child, which is stored in $leftchildname. For example, if the root node, parent, is being examined, the value stored in $leftchildname is parentleft.
- Similarly, line 18 appends right to the node name and stores the result in $rightchildname.
- Line 19 checks whether the current node has a left child, which is true if $tree{$leftchildname} is defined. (For example, parent has a left child, because $tree{"parentleft"} is defined.) If the current node has a left child, line 20 recursively calls print_tree to print the left subtree (the left child and its children).
- Line 22 prints the name of the current node.
- Line 23 checks whether the current node has a right child. If it does, line 24 recursively calls print_tree to print the right subtree.
Note that print_tree prints the names of the nodes of the tree in the following order: left subtree, node, right subtree. This order of traversal is called infix mode or infix traversal. If you move line 22 to precede line 19, the node is printed first, followed by the left subtree and the right subtree; this order of traversal is called prefix mode. If you move line 22 to follow line 25, the node is printed after the subtrees are printed; this is called postfix mode.
Databases
As you have seen, you can build a tree using an associative array. To do this, you build the associative array subscripts by joining character strings together (such as joining the node name and "left"). You can use this technique of joining strings together to use associative arrays to build other data structures.
For example, suppose you want to create a database that contains the lifetime records of baseball players. Each record is to consist of the following:
- For non-pitchers, a record consists of games played (GP),
home runs (HR), runs batted in (RBI) and batting average (AVG).
For example, the record on Lou Gehrig would read as follows:
Gehrig: 2164 GP, 493 HR, 1991 RBI, .340 BA - For pitchers, a record consists of games pitched (GP), wins
(W), and earned run average (ERA). For example, the record on
Lefty Grove would read as follows:
Grove: 616 GP, 300 W, 3.05 ERA
To create a database containing player and pitcher records, you need the following fields:
- A name field, for the player's name
- A key indicating whether the player was a pitcher
- The fields defined above
You can use an associative array to simulate this in Perl. To do this, build the subscripts for the associative array by concatenating the name of the player with the name of the field being stored by this element of the array. For example, if the associative array is named %playerbase, $playerbase{"GehrigRBI"}, it contains the career RBI total for Lou Gehrig.
Listing 10.6 shows how to build a player database and how to sequentially print fields from each of the player records.
Listing 10.6. A program that builds and prints a database.
1: #!/usr/local/bin/perl
2:
3: @pitcherfields = ("NAME", "KEY", "GP", "W", "ERA");
4: @playerfields = ("NAME", "KEY", "GP", "HR", "RBI", "BA");
5:
6: # Build the player database by reading from standard input.
7: # %playerbase contains the database, @playerlist the list of
8: # players (for later sequential access).
9: $playercount = 0;
10: while ($input = <STDIN>) {
11: $input =~ s/^\s+|\s+$//g;
12: @words = split (/\s+/, $input);
13: $playerlist[$playercount++] = $words[0];
14: if ($words[1] eq "player") {
15: @fields = @playerfields;
16: } else {
17: @fields = @pitcherfields;
18: }
19: for ($count = 1; $count <= @words; $count++) {
20: $playerbase{$words[0].$fields[$count-1]} =
21: $words[$count-1];
22: }
23: }
24:
25: # now, print out pitcher win totals and player home run totals
26: foreach $player (@playerlist) {
27: print ("$player: ");
28: if ($playerbase{$player."KEY"} eq "player") {
29: $value = $playerbase{$player."HR"};
30: print ("$value home runs\n");
31: } else {
32: $value = $playerbase{$player."W"};
33: print ("$value wins\n");
34: }
35: }
$ program10_6 Gehrig player 2164 493 1991 .340 Ruth player 2503 714 2217 .342 Grove pitcher 616 300 3.05 Williams player 2292 521 1839 .344 Koufax pitcher 397 165 2.76 ^D Gehrig: 493 home runs Ruth: 714 home runs Grove: 300 wins Williams: 521 home runs Koufax: 165 wins $
![]()
This program has been designed so that it is easy to add new fields to the database. With this in mind, lines 3 and 4 define the fields that are to be used when building the player and pitcher records.
Lines 9-23 build the database. First, line 9 initializes $playercount to 0; this global variable keeps track of the number of players in the database.
Lines 10-12 read a line from the standard input file, check whether the file is empty, remove leading and trailing white space from the line, and split the line into words.
Line 13 adds the player name (the first word in the input line) to the list of player names stored in @playerlist. The counter $playercount then has 1 added to it; this reflects the new total number of players stored in the database.
Lines 14-18 determine whether the new player is a pitcher or not. If the player is a pitcher, the names of the fields to be stored in this player record are to be taken from @pitcherfields; otherwise, the names are to be taken from @playerfields. To simplify processing later on, another array variable, @fields, is used to store the list of fields actually being used for this player.
Lines 19-22 copy the fields into the associative array, one at a time. Each array subscript is made up of two parts: the name of the player and the name of the field being stored. For example, Sandy Koufax's pitching wins are stored in the array element KoufaxW. Note that neither the player name nor the field names appear in this loop; this means that you can add new fields to the list of fields without having to change this code.
Lines 26-35 now search the database for all the win and home run totals just read in. Each iteration of the foreach loop assigns a different player name to the local variable $player. Line 28 examines the contents of the array element named $player."KEY" to determine whether the player is a pitcher.
If the player is not a pitcher, lines 29-30 print out the player's home-run total by accessing the array element $player."HR". If the player is a pitcher, the pitcher's win total is printed out by lines 32-33; these lines access the array element $player."W".
Note that the database can be accessed randomly as well as sequentially. To retrieve, for example, Babe Ruth's lifetime batting average, you would access the array element $playerbase{"RuthAVG"}. If the record for a particular player is not stored in the database, attempting to access it will return the null string. For example, the following assigns the null string to $cobbavg because Ty Cobb is not in the player database:
$cobbavg = $playerbase{"CobbAVG"};
As you can see, associative arrays enable you to define databases with variable record lengths, accessible either sequentially or randomly. This gives you all the flexibility you need to use Perl as a database language.
Example: A Calculator Program
Listing 10.7 provides an example of what you can do with associative arrays and recursive subroutines. This program reads in an arithmetic expression, possibly spread over several lines, and builds a tree from it. The program then evaluates the tree and prints the result. The operators supported are +, -, *, /, and parentheses (to force precedence).
This program is longer and more complicated than the programs you have seen so far, but stick with it. Once you understand this program, you will know enough to be able to write an entire compiler in Perl!
Listing 10.7. A calculator program that uses trees.
1: #!/usr/local/bin/perl
2: # statements which initialize the program
3: $nextnodenum = 1; # initialize node name generator
4: &get_next_item; # read first value from file
5: $treeroot = &build_expr;
6: $result = &get_result ($treeroot);
7: print ("the result is $result\n");
8: # Build an expression.
9: sub build_expr {
10: local ($currnode, $leftchild, $rightchild);
11: local ($operator);
12: $leftchild = &build_add_operand;
13: if (&is_next_item("+") || &is_next_item("-")) {
14: $operator = &get_next_item;
15: $rightchild = &build_expr;
16: $currnode = &get_new_node ($operator,
17: $leftchild, $rightchild);
18: } else {
19: $currnode = $leftchild;
20: }
21: }
22: # Build an operand for a + or - operator.
23: sub build_add_operand {
24: local ($currnode, $leftchild, $rightchild);
25: local ($operator);
26: $leftchild = &build_mult_operand;
27: if (&is_next_item("*") || &is_next_item("/")) {
28: $operator = &get_next_item;
29: $rightchild = &build_add_operand;
30: $currnode = &get_new_node ($operator,
31: $leftchild, $rightchild);
32: } else {
33: $currnode = $leftchild;
34: }
35: }
36: # Build an operand for the * or / operator.
37: sub build_mult_operand {
38: local ($currnode);
39: if (&is_next_item("(")) {
40: # handle parentheses
41: &get_next_item; # get rid of "("
42: $currnode = &build_expr;
43: if (! &is_next_item(")")) {
44: die ("Invalid expression");
45: }
46: &get_next_item; # get rid of ")"
47: } else {
48: $currnode = &get_new_node(&get_next_item,
49: "", "");
50: }
51: $currnode; # ensure correct return value
52: }
53: # Check whether the last item read matches
54: # a particular operator.
55: sub is_next_item {
56: local ($expected) = @_;
57: $curritem eq $expected;
58: }
59: # Return the last item read; read another item.
60: sub get_next_item {
61: local ($retitem);
62: $retitem = $curritem;
63: $curritem = &read_item;
64: $retitem;
65: }
66: # This routine actually handles reading from the standard
67: # input file.
68: sub read_item {
69: local ($line);
70: if ($curritem eq "EOF") {
71: # we are already at end of file; do nothing
72: return;
73: }
74: while ($wordsread == @words) {
75: $line = <STDIN>;
76: if ($line eq "") {
77: $curritem = "EOF";
78: return;
79: }
80: $line =~ s/\(/ ( /g;
81: $line =~ s/\)/ ) /g;
82: $line =~ s/^\s+|\s+$//g;
83: @words = split(/\s+/, $line);
84: $wordsread = 0;
85: }
86: $curritem = $words[$wordsread++];
87: }
88: # Create a tree node.
89: sub get_new_node {
90: local ($value, $leftchild, $rightchild) = @_;
91: local ($nodenum);
92: $nodenum = $nextnodenum++;
93: $tree{$nodenum} = $value;
94: $tree{$nodenum . "left"} = $leftchild;
95: $tree{$nodenum . "right"} = $rightchild;
96: $nodenum; # return value
97: }
98: # Calculate the result.
99: sub get_result {
100: local ($node) = @_;
101: local ($nodevalue, $result);
102: $nodevalue = $tree{$node};
103: if ($nodevalue eq "") {
104: die ("Bad tree");
105: } elsif ($nodevalue eq "+") {
106: $result = &get_result($tree{$node . "left"}) +
107: &get_result($tree{$node . "right"});
108: } elsif ($nodevalue eq "-") {
109: $result = &get_result($tree{$node . "left"}) -
110: &get_result($tree{$node . "right"});
111: } elsif ($nodevalue eq "*") {
112: $result = &get_result($tree{$node . "left"}) *
113: &get_result($tree{$node . "right"});
114: } elsif ($nodevalue eq "/") {
115: $result = &get_result($tree{$node . "left"}) /
116: &get_result($tree{$node . "right"});
117: } elsif ($nodevalue =~ /^[0-9]+$/) {
118: $result = $nodevalue;
119: } else {
120: die ("Bad tree");
121: }
122:}
$ program10_7 11 + 5 * (4 - 3) ^D the result is 16 $
![]()
This program is divided into two main parts: a part that reads the input and produces a tree, and a part that calculates the result by traversing the tree.
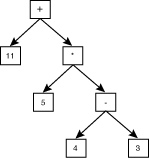
The subroutines build_expr, build_add_operand, and build_mult_operand build the tree. To see how they do this, first look at Figure 10.12 to see what the tree for the example, 11 + 5 * (4 - 3), should look like.
Figure 10.12: The tree for the example in Listing 10.7.
When this tree is evaluated, the nodes are searched in postfix order. First, the left subtree of the root is evaluated, then the right subtree, and finally the operation at the root.
The rules followed by the three subroutines are spelled out in the following description:
- An expression consists of one of the following:
- An add_operand
- An add_operand, a + or - operator, and an expression
- An add_operand consists of one of the following:
- A mult_operand
- A mult_operand, a * or / operator, and an add_operand
- A mult_operand consists of one of the following:
- A number (a group of digits)
- An expression enclosed in parentheses
The subroutine build_expr handles all occurrences of condition 1; it is called (possibly recursively) whenever an expression is processed. Condition 1a covers the case in which the expression contains no + or - operators (unless they are enclosed in parentheses). Condition 1b handles expressions that contain one or more + or - operators.
The subroutine build_add_operand handles condition 2; it is called whenever an add_operand is processed. Condition 2a covers the case in which the add operand contains no * or / operators (except possibly in parentheses). Condition 2b handles add operands that contain one or more * or / operators.
The subroutine build_mult_operand handles condition 3 and is called whenever a mult_operand is processed. Condition 3a handles multiplication operands that consist of a number. Condition 3b handles multiplication operators that consist of an expression in parentheses; to obtain the subtree for this expression, build_mult_operand calls build_expr recursively and then treats the returned subtree as a child of the node currently being built.
Note that the tree built by build_expr, build_mult_operand, and build_add_operand is slightly different from the tree you saw in Listing 10.5. In that tree, the value of the node could also be used as the subscript into the associative array. In this tree, the value of the node might not be unique. To get around this problem, a separate counter creates numbers for each node, which are used when building the subscripts. For each node numbered n (where n is an integer), the following are true:
- $tree{n} contains the value of the node, which is the number or operator associated with the node.
- $tree{n."left"} contains the number of the left child of the node.
- $tree{n."right"} contains the number of the right child of the node.
The subroutines is_next_item, get_next_item, and read_item read the input from the standard input file and break it into numbers and operators. The subroutine get_next_item "pre-reads" the next item and stores it in the global variable $curritem; this lets is_next_item check whether the next item to be read matches a particular operator. To read an item, get_next_item calls read_item, which reads lines of input, breaks them into words, and returns the next word to be read.
The subroutine get_new_node creates a tree node. To do this, it uses the contents of the global variable $nextnodenum to build the associative array subscripts associated with the node. $nextnodenum always contains a positive integer n, which means that the value associated with this node (which is a number or operator) is stored in $tree{n}. The location of the left and right children, if any, are stored in $tree{n."left"} and $tree {n."right"}.
The subroutine get_result traverses the tree built by build_expr in postfix order (subtrees first), performing the arithmetic operations as it does so. get_result returns the final result, which is then printed.
Note that the main part of this program is only eight lines long!
This often happens in more complex programs. The main part of
the program just calls subroutines, and the subroutines do the
actual work.
| NOTE |
This program is just the tip of the iceberg: you can use associative arrays to simulate any data structure in any programming language. |
Summary
In toChapter's lesson, you learned about associative arrays, which are arrays whose subscripts can be any scalar value.
You can copy a list to an associative array, provided there is an even number of elements in the list. Each pair of elements in the list is treated as an associated array subscript and its value. You also can copy an associative array to an ordinary array variable.
To add an element to an associative array, just assign a value to an element whose subscript has not been previously seen. To delete an element, call the built-in function delete.
The following three built-in functions enable you to use associative arrays with foreach loops:
- The built-in function keys retrieves each associative array subscript in turn.
- The built-in function values retrieves each associative array value in turn.
- The built-in function each retrieves each subscript-value pair in turn (as a two-element list).
Associative arrays are not guaranteed to be stored in any particular order. To guarantee a particular order, use sort with keys, values, or each.
Associative arrays can be used to simulate a wide variety of data structures, including linked lists, structures, trees, and databases.
Q&A
| Q: | Are pointers implemented in Perl? |
| A: | Yes, if you are using Perl 5; they are discussed on Chapter 18, "References in Perl 5." Perl 4 does not support pointers. |
| Q: | How can I implement more complicated data structures using associative arrays? |
| A: | All you need to do is design the structure you want to implement, name each of the fields in the structure, and use the name-concatenation trick to build your associative array subscript names. |
| Q: | What do I do if I want to build a tree that has multiple values at each node? |
| A: | There are many ways to do this. One way is to append value1, value2, and so on, to the name of each node; for example, if the node is named n7, n7value1 could be the associative array subscript for the first value associated with the node, n7value2 could be the subscript for the second, and so on. |
| Q: | What do I do if I want to build a tree that has more than two children per node? |
| A: | Again, there are many ways to do this. A possible solution is to use child1, child2, child3, and so on, instead of left and right. |
| Q: | How do I destroy a tree that I have created? |
| A: | To destroy a tree, write a subroutine that traverses the tree in postfix order (subtrees first). Destroy each subtree (by recursively calling your subroutine), and then destroy the node you are looking at by
calling delete.
Note that you shouldn't use keys or each to access each element of the loop before deleting it. Deleting an element affects how the associative array is stored, which means that keys and each might not behave the way you want them to. If you want to destroy the entire associative array in which the tree is stored, you can use the undef function, which is described on Chapter 14, "Scalar-Conversion and List-Manipulation Functions." |
Workshop
The Workshop provides quiz questions to help you solidify your understanding of the material covered and exercises to give you experience in using what you've learned. Try and understand the quiz and exercise answers before you go on to tomorrow's lesson.
Quiz
- Define the following terms:
- associative array
- pointer
- linked list
- binary tree
- node
- child
- What are the elements of the associative array created by
the following assignment?
%list = ("17.2", "hello", "there", "46", "e+6", "88"); - What happens when you assign an associative array to an ordinary array variable?
- How can you create a linked list using an associative array?
- How many times does the following loop iterate?
%list = ("first", "1", "second", "2", "third", "3");
foreach $word (keys(%list)) {
last if ($word == "second");
}
Exercises
- Write a program that reads lines of input consisting of two
words per line, such as
bananas 16
and creates an associative array from these lines. (The first word is to be the subscript and the second word the value.) - Write a program that reads a file and searches for lines of
the form
index word
where word is a word to be indexed. Each indexed word is to be stored in an associative array, along with the line number on which it first occurs. (Subsequent occurrences can be ignored.) Print the resulting index. - Modify the program created in Exercise 2 to store every occurrence of each index line. (Hint: Try building the associative array subscripts using the indexed word, a non-printable character, and a number.) Print the resulting index.
- Write a program that reads input lines consisting of a student
name and five numbers representing the student's marks in English,
history, mathematics, science, and geography, as follows:
Jones 61 67 75 80 72
Use an associative array to store these numbers in a database, and then print out the names of all students with failing grades (less than 50) along with the subjects they failed. - BUG BUSTER: What is wrong with the following code?
%list = ("Fred", 61, "John", 72,
"Jack", 59, "Mary", 80);
$surname = "Smith";
foreach $firstname (keys (%list)) {
%list{$firstname." ".$surname} = %list{$firstname};
}



Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}